Привет, Хабр!
У нас в предзаказе появилась долгожданная книга о библиотеке PyTorch.

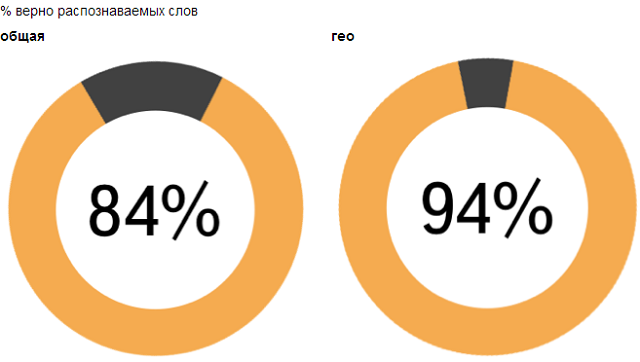
Поскольку весь необходимый базовый материал о PyTorch вы узнаете из этой книги, мы напоминаем о пользе процесса под названием «grokking» или «углубленное постижение» той темы, которую вы хотите усвоить. В сегодняшней публикации мы расскажем, как Кай Арулкумаран (Kai Arulkumaran) грокнул PyTorch (без картинок). Добро пожаловать под кат.
У нас в предзаказе появилась долгожданная книга о библиотеке PyTorch.
Поскольку весь необходимый базовый материал о PyTorch вы узнаете из этой книги, мы напоминаем о пользе процесса под названием «grokking» или «углубленное постижение» той темы, которую вы хотите усвоить. В сегодняшней публикации мы расскажем, как Кай Арулкумаран (Kai Arulkumaran) грокнул PyTorch (без картинок). Добро пожаловать под кат.