В конце марта 2023г., компания Databricks выпустила Dolly, большую языковую модель, подобную ChatGPT, дообученную на платформе Databricks Machine Learning Platform. Результат оценки работы модели Dolly показывает, что модель с открытым исходным кодом двухлетней давности (GPT-J) при дообучении на публичном датасете, собранном в Стэнфорде (Stanford Alpaca), на небольшом наборе данных из 50 000 диалогов (вопросов и ответов), может демонстрировать удивительно высокое качество обучения, не характерное для родительской модели (GPT-J), на которой она основана.
Но с первой версией модели Dolly существует одна проблема - датасет от Stanford Alpaca был собран с помощью автоматизированных скриптов от ChatGPT, что нарушает лицензию и правила использования моделей OpenAI.
Чтобы исправить эту проблему, в апреле 2023г. Databricks выпустила
Dolly 2 - большую языковую модель с открытым исходным кодом и открытой лицензией для научных и коммерческих целей.
Dolly 2 - это языковая модель с 12 млрд. параметров, основанная на семействе моделей EleutherAI pythia и дообученная исключительно на новом датасете высокого качества, созданном сотрудниками Databricks с использованием RL from Human Feedback (RLHF).
Databricks открыли исходный код Dolly 2, включая код обучения, сам датасет и веса модели, подходящие для коммерческого использования. Это означает, что любая организация может создавать, владеть и настраивать комплексные модели, не платя за доступ к API или передавая данные третьим сторонам.

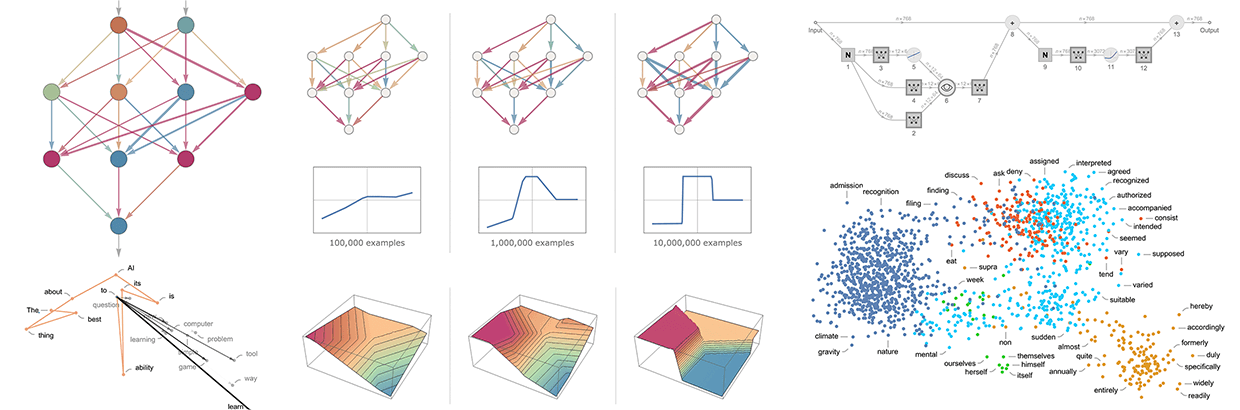




 В октябре состоялся второй чемпионат по программированию. Мы получили 12 500 заявок, более 6000 человек попробовали свои силы в соревнованиях. В этот раз участники могли выбрать один из следующих треков: бэкенд, фронтенд, мобильную разработку и машинное обучение. В каждом треке требовалось пройти квалификационный этап и финал.
В октябре состоялся второй чемпионат по программированию. Мы получили 12 500 заявок, более 6000 человек попробовали свои силы в соревнованиях. В этот раз участники могли выбрать один из следующих треков: бэкенд, фронтенд, мобильную разработку и машинное обучение. В каждом треке требовалось пройти квалификационный этап и финал.