Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было
декартово дерево. В этот раз —
система непересекающихся множеств. Она же известна под названиями
disjoint set union (DSU) или
Union-Find.
Условие
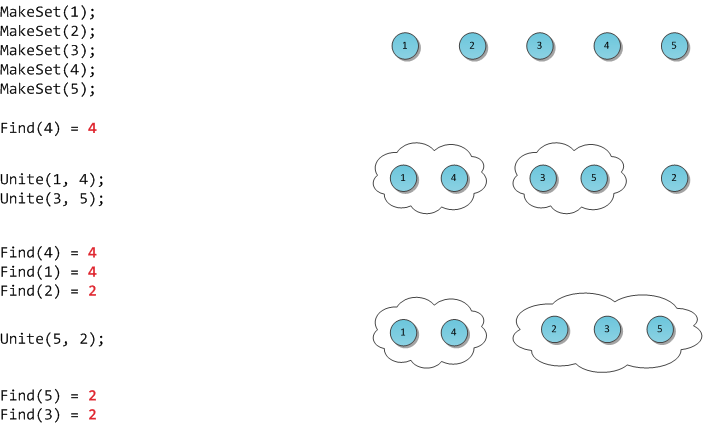
Поставим перед собой следующую задачу. Пускай мы оперируем элементами
N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать
быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить
идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества —
представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.

 Доброго времени суток, хабравчане! В этой статье я подробно расскажу вам о трансформации и вращении в javascripte. Матрица трансформаций, на первый взгляд, штука непонятная и многие ею пользуются даже не осознавая, что она делает на самом деле, используя готовые значения из интернета. На
Доброго времени суток, хабравчане! В этой статье я подробно расскажу вам о трансформации и вращении в javascripte. Матрица трансформаций, на первый взгляд, штука непонятная и многие ею пользуются даже не осознавая, что она делает на самом деле, используя готовые значения из интернета. На 

 Когда станете хорошо известны в своем деле, клиенты будут постоянно обращаться к вам, а не выбудете искать их. Когда есть много работы, то и стараться продавать свои услуги не будет особой нужды.
Когда станете хорошо известны в своем деле, клиенты будут постоянно обращаться к вам, а не выбудете искать их. Когда есть много работы, то и стараться продавать свои услуги не будет особой нужды.
 На написание поста меня сподвигла найденная на просторах хабра ссылочка на
На написание поста меня сподвигла найденная на просторах хабра ссылочка на  Верстка — относительно независимый этап веб-разработки и, к примеру, в маленьких веб-студиях часто — это первый кандидат на аутсорсинг в условиях ограниченных трудовых ресурсов.
Верстка — относительно независимый этап веб-разработки и, к примеру, в маленьких веб-студиях часто — это первый кандидат на аутсорсинг в условиях ограниченных трудовых ресурсов.