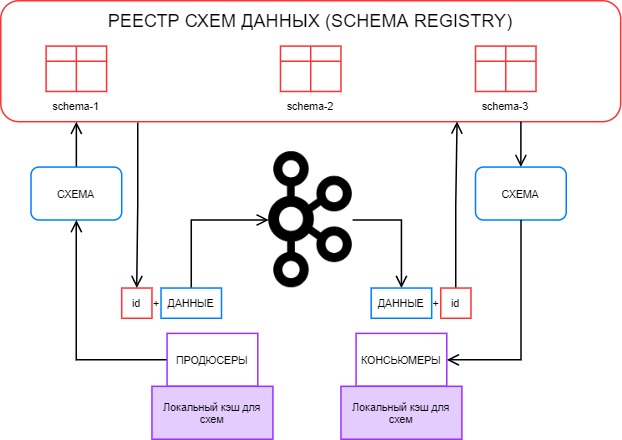
Для кого статья
Вы уже написали свои первые 1000 строк кода и сейчас хотите сделать их понятнее, потому что внесение изменений занимает столько-же времени, сколько написать заново, но советы из ООП, SOLID, clean architecture и т.д. непонятны вам.
О чем статья
Эта статья - не объяснение принципов ООП, SOLID своими словами, а попытка создать промежуточный уровень между никакой и чистой архитектурами. 100% советы будут накладываться друг на друга и перефразировать SOLID, но так даже лучше.
От кого статья
Я Middle разработчик. Конечно, не гуру разработки, но кому, как не мне, помнить о проблемах, с которыми сталкивался когда только начинал свой путь.
Отказ от ответственности
Уверен, каждый пункт из статьи может быть предметом спора, но на то это и вольный пересказ. Вся статья идет под эмблемой "Лучше применить такую архитектуру, чем не применять вообще никакой".
Формат статьи - наводящие советы / вопросы.