Здравствуйте, коллеги!
Из последних известий по нашим планируемым новинкам из области ML/DL:
Нишант Шакла, "Машинное обучение с Tensorflow" — книга в верстке, ожидается в магазинах в январе
Делип Рао, Брайан Макмахан, "Обработка естественного языка на PyTorch" — контракт подписан, планируем приступать к переводу в январе.
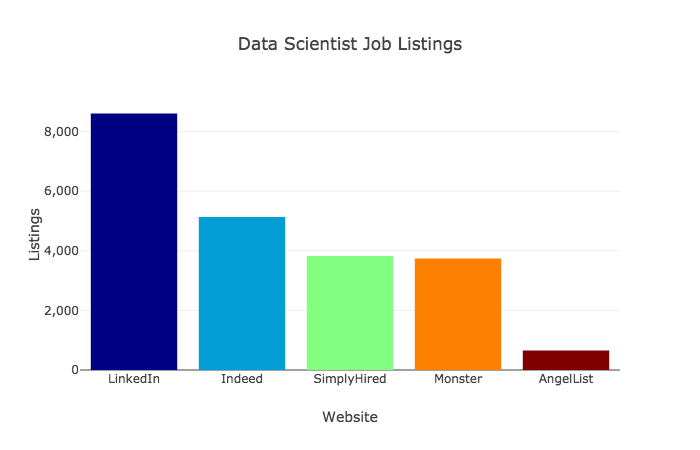
В данном контексте мы хотели в очередной раз вернуться к болезненной теме — слабой проработке темы ML/DL в языке Java. Из-за явной незрелости этих решений и алгоритмов на языке Java мы когда-то приняли решение отказаться от книги Гибсона и Паттерсона по DL4J, и публикуемая сегодня статья Хамфри Шейла (Humphrey Sheil) подсказывает, что мы, вероятно, были правы. Предлагаем познакомиться с мыслями автора о том, каким образом язык Java мог бы наконец составить конкуренцию Python в машинном обучении
Из последних известий по нашим планируемым новинкам из области ML/DL:
Нишант Шакла, "Машинное обучение с Tensorflow" — книга в верстке, ожидается в магазинах в январе
Делип Рао, Брайан Макмахан, "Обработка естественного языка на PyTorch" — контракт подписан, планируем приступать к переводу в январе.
В данном контексте мы хотели в очередной раз вернуться к болезненной теме — слабой проработке темы ML/DL в языке Java. Из-за явной незрелости этих решений и алгоритмов на языке Java мы когда-то приняли решение отказаться от книги Гибсона и Паттерсона по DL4J, и публикуемая сегодня статья Хамфри Шейла (Humphrey Sheil) подсказывает, что мы, вероятно, были правы. Предлагаем познакомиться с мыслями автора о том, каким образом язык Java мог бы наконец составить конкуренцию Python в машинном обучении