 Пост является значительной переработкой статьи The Complete Guide to China’s Major Social Media Networks с моими правками, комментариями и некоторыми иллюстрациями. А ещё добавил правильное русское чтение китайских сервисов.
Пост является значительной переработкой статьи The Complete Guide to China’s Major Social Media Networks с моими правками, комментариями и некоторыми иллюстрациями. А ещё добавил правильное русское чтение китайских сервисов.
17 апреля 2014 г. китайский аналог Twitter'а — Sina Weibo – вышел на американскую биржу. Благодаря IPO компания привлекла меньше ожидаемого, однако это, безусловно, большой успех китайских социальных медиа-ресурсов. Поэтому стоит сделать небольшой обзор существующих на сегодняшний день китайских социальных интернет-ресурсов. Разумеется, он не претендует на абсолютною полноту и объективность, поэтому смело пишите свои дополнения и замечания.
Платформы и сервисы, о которых пойдёт речь, имеют как настольный, так и мобильный клиент, если прямо не указано другое.
Так же следует помнить, что многие иностранные ресурсы – такие, как Facebook, Twitter, YouTube, частично Википедия –
заблокироавны в КНР, поэтому местные жители пользуются китайскими аналогами, зачастую не зная о существовании оригиналов. Кроме того, везде существуют списки «плохих слов» (в основном плохих политически), ввод которых блокируется, либо активность таких пользователей тщательно отслеживается. Под Китаем, разумеется, будем иметь в виду его материковую часть, не считая Гонконга, Макао и Тайваня, где цензура компартии не работает.
Категории социальных медиа
Существуют разные категоризации социальных сервисов. Здесь мы разберём их так, чтобы провести аналогию с западными сервисами.
Разумеется, каждый сервис, помимо основного функционала, обладает и многими побочными возможностями, поэтом для категоризации сфокусируемся только на основном назначении того или иного сайта\приложения.





 У меня сложилось впечатление, что в России есть стереотип, что зарабатывать на 3d-принтерах можно только двумя способами:
У меня сложилось впечатление, что в России есть стереотип, что зарабатывать на 3d-принтерах можно только двумя способами: 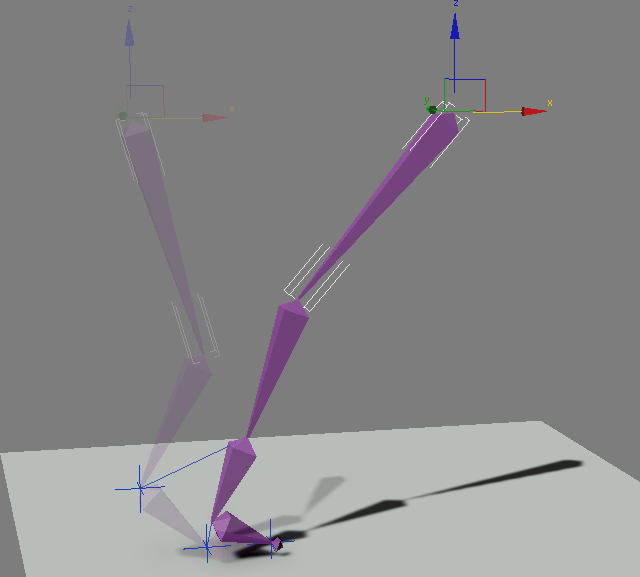 Что такое «Инверсная кинематика»?
Что такое «Инверсная кинематика»?



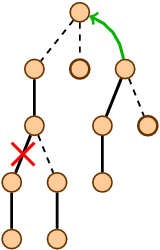 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 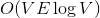 и
и 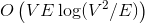 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.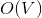 памяти и
памяти и 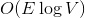 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья. Доброго времени суток, читатель.
Доброго времени суток, читатель. 


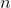 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 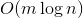 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 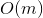 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.