Запуск сайта ответственное мероприятие, надеюсь что этот список контрольных вопросов позволит ничего не упустить из виду.

Сергей Кокшаров @devaka
User
Чеклист запуска сайта
3 min

Этот чеклист будет полезен всем, кто запускает сайты или следит за этим увлекательным процессом. Ничего не пропустите!
Камасутра Start-up-а. Чеклист из 5 поз, без которых 70% проектов разваливаются менее чем за год
5 min

При запуске нового проекта, всегда есть очень много специфических моментов, от которых зависит его жизнеспособность. Если покопаться в Google по запросам «Как запустить стартап», «Проблемы старапов» или «Опыт запуска стартапа», можно найти кучу статей, описывающих гору проблем в начинающихся проектах. Не смотря на свою непохожесть, они все объединены одной общей историей: «детские болезни» и ошибки, которые приводят к феерическому «сексу» с внезапно взбесившимся проектом и кучей неприятностей в придачу. Посему, сегодня будет краткий экскурс в прикладную «сексологию стартапов» с максимально подробным разбором практических моментов.
Настоящие ассоциативные массивы в JavaScript
4 min
Tutorial
Translation
Использование литерала объекта, как простого средства для хранения пар ключ-значение давно стало обычным делом в JavaScript. Тем не менее, литерал объекта всё же не является настоящим ассоциативным массивом и по этому, в некоторых ситуациях, его использование может привести к неожиданным результатам. Пока JS не предоставляет нативную реализацию ассоциативных массивов (не во всех браузерах, по крайней мере), существует отличная альтернатива объектам, с нужной функциональностью и без подводных камней.
Внезапный диван леопардовой расцветки
8 min
Если вы интересуетесь искусственным интеллектом и прочим распознаванием, то наверняка уже видели эту картинку:

А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
Так вот, на самом деле все совершенно не так.
А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
{kind=link}
Так вот, на самом деле все совершенно не так.
Здоровый сон — 4 совета от космонавтов
5 min
Translation

Кто разбирается в проблемах сна лучше всего? Конечно же, космонавты. В этой статье мы расскажем, как решить проблему с недосыпом и вернуть здоровый сон.
Google Similar Images: поиск похожих изображений
1 min
Translation
Google Similar Images — это экспериментальный сервис от Google Labs, который позволяет находить изображения, похожие на то, что вы выбрали.
«Similar Images позволяет вам искать изображения, используя картинки, а не слова. Нажмите на ссылку Similar images под изображением, чтобы найти другие изображения, похожие на это.»
Интерфейс не обеспечивает анализа изображений в реальном времени, то есть нельзя загрузить собственные картинки для анализа. Вместо этого Google предлагает найти изображения в интернете, выбрать одно и нажать на ссылку «Similar images». Результаты удивительно релевантны, и это, возможно, самая впечатляющая функция, когда-либо реализованная Google Image Search.
«Similar Images позволяет вам искать изображения, используя картинки, а не слова. Нажмите на ссылку Similar images под изображением, чтобы найти другие изображения, похожие на это.»
Интерфейс не обеспечивает анализа изображений в реальном времени, то есть нельзя загрузить собственные картинки для анализа. Вместо этого Google предлагает найти изображения в интернете, выбрать одно и нажать на ссылку «Similar images». Результаты удивительно релевантны, и это, возможно, самая впечатляющая функция, когда-либо реализованная Google Image Search.
Microsoft постепенно прощается с Internet Explorer 6
1 min
После того, как несколько дней назад уровень использования Internet Explorer 6 в США упал ниже одного процента, компания Microsoft начала праздновать «кончину» браузера, выпущенного 10 лет назад. По данным компании Net Applications США присоединилась к таким странам, как Австрия, Польша, Швеция, Дания, Финляндия и Норвегия, где им также уже пользуются меньше 1 процента населения. На подходе Чехия, Мексика, Украина, Португалия и Филиппины, где этот показатель колеблется в районе 1 процента. Антилидером по прежнему является Китай с его 25 процентами.

Психологическая деформация программистов. Взгляд с обеих сторон баррикад
6 min
 Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.
Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.Я достаточно часто сталкивался с подобным мнением и не придавал ему особого значения, но когда женский коллектив нашей организации поздравил программистов с 23-м февраля по доброму назвав их «космическими войсками», решил всё же расставить определенные акценты в данном вопросе, т.к. одна из моих профессий связана напрямую с психоанализом. Да и баш уже не молчит.
Не все комментарии одинаково полезны
7 min
Все животные равны, но некоторые животные равнее других. Скотный Двор, Джордж Оруэлл (оригинал).
Достаточно много статей на хабре набирает существенное количество комментариев, e.g. в статьях "лучшее за месяц" их, как правило, более сотни. За годы чтения хабра, создалось впечатление, что примерно в половине случаев для комментариев первого уровня получается вот такая вот картина
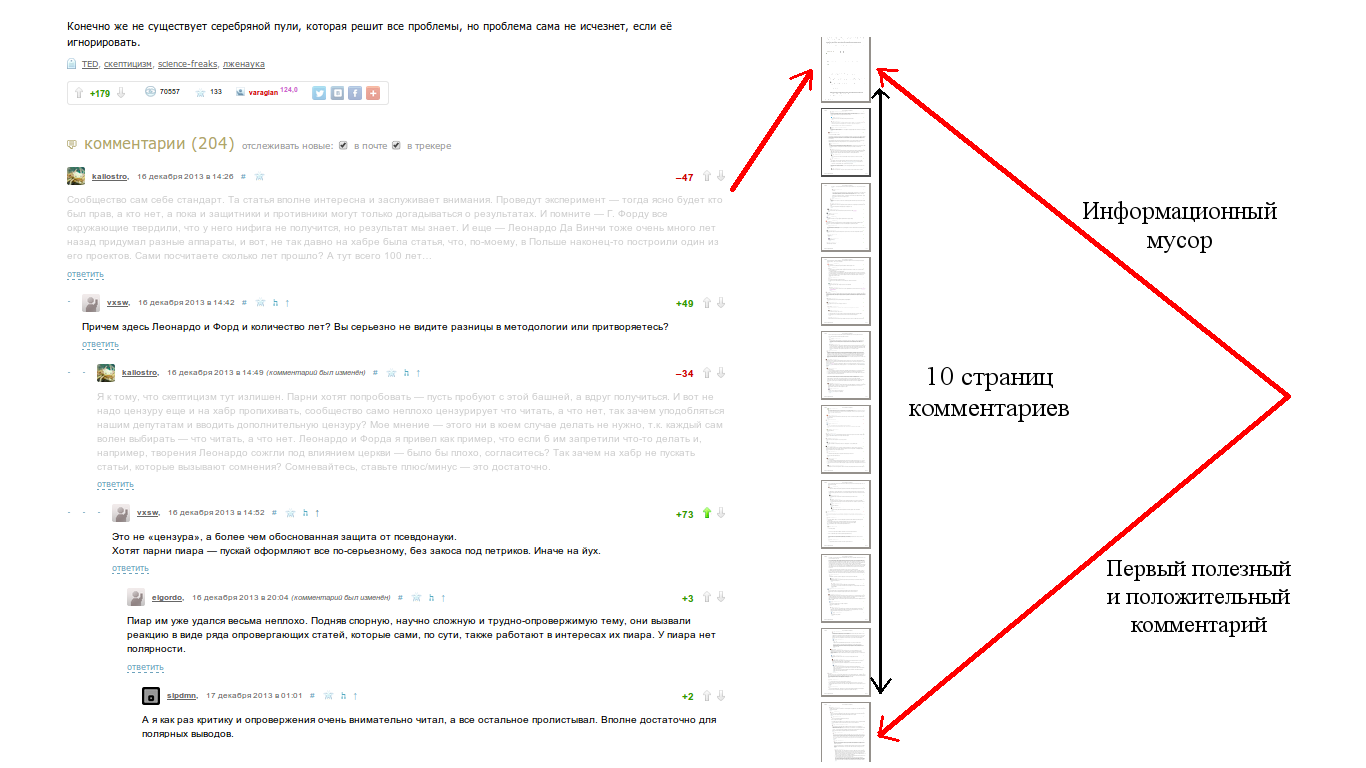
(картинка сделана на основе хабра-статьи «Список скептика»).
Под катом рассказ, какие бывают сортировки комментариев, где они применяются и краткое рассуждение о том, как вообще можно сортировать комментарии (и зачем).
Быстрая сборка кубика Рубика
7 min
 Возможно, многие из читателей задавались вопросом, как людям удаётся собирать кубик Рубика 3×3 за 7 секунд. Если даже предположить, что рекордсмену сильно повезло, то таблица мирового рейтинга по среднему из пяти результатов уже не оставляет сомнений: если больше 80 человек в среднем укладываются в 12 секунд, очевидно они что-то знают. В этом кратком обзоре я постараюсь приоткрыть секреты скоростной сборки. Сразу оговорюсь, что после прочтения этой статьи вы не станете чемпионами: здесь приведены только основные моменты и ссылки на более подробную информацию. Кроме того, даже после изучения метода полностью вам потребуются долгие тренировки для достижения хороших результатов. Зато вы получите неплохое представление о том, как это делается, и при желании будете знать, куда двигаться дальше. Я думаю, при достаточной усидчивости после нескольких месяцев тренировок многие смогут достичь среднего результата в районе 30 секунд.
Возможно, многие из читателей задавались вопросом, как людям удаётся собирать кубик Рубика 3×3 за 7 секунд. Если даже предположить, что рекордсмену сильно повезло, то таблица мирового рейтинга по среднему из пяти результатов уже не оставляет сомнений: если больше 80 человек в среднем укладываются в 12 секунд, очевидно они что-то знают. В этом кратком обзоре я постараюсь приоткрыть секреты скоростной сборки. Сразу оговорюсь, что после прочтения этой статьи вы не станете чемпионами: здесь приведены только основные моменты и ссылки на более подробную информацию. Кроме того, даже после изучения метода полностью вам потребуются долгие тренировки для достижения хороших результатов. Зато вы получите неплохое представление о том, как это делается, и при желании будете знать, куда двигаться дальше. Я думаю, при достаточной усидчивости после нескольких месяцев тренировок многие смогут достичь среднего результата в районе 30 секунд.Неназойливые регистрация и вход на сайт
5 min

Надоело отправлять пользователям подтверждения аккаунта и сброса пароля по утере на почту?
Пользователи уходят, устав заполнять вашу форму регистрации?
Вы точно уверены, что у посетителей вашего сайта есть аккаунт на Facebook или Вконтакте?
Не хотите хранить никакие персональные данные?
Ваши пользователи устали вводить логин и пароль?
Вашим пользователям лень даже нажать на кнопку «Войти»?
Видели, как это сделано на stackoverflow и хотите так же, и даже лучше?
Ниже о том, как сделать вход на ваш сайт ненавязчивым, автоматическим, и без особых затрат.
Ошибки PHP: классификация, примеры, обработка
6 min
В статье представлена очередная попытка разобраться с ошибками, которые могут встретиться на вашем пути php-разработчика, их возможная классификация, примеры их возникновения, влияние ошибок на ответ клиенту, а также инструкции по написанию своего обработчика ошибок.
О компиляторах и интерпретаторах
2 min
Если ты всегда мечтал написать свой язык программирования — добро пожаловать. Здесь ты наверняка найдёшь для себя что-нибудь интересное.
GitHub-юзер yawnt собрал чудесную подборку ссылок для любителей драконов, языков и прочих вкусных внутренностей. А знающие камрады в комментариях наверняка поделятся с тобой и другими яствами.
Пишет yawnt следующее:
С каждым днём мне всё интереснее тема компиляторов, интерпретаторов и дизайна языков программирования в целом. И я решил поделиться с народом ссылками на собранные мной материалы (большую часть мне самому ещё предстоит прочитать :<). Надеюсь, кому-нибудь они окажутся полезными.
Я не включил (и не собираюсь) в список ссылки на официальную документацию, т. к. считаю очевидным, что первым делом следует смотреть именно туда ;P.
Про абстрагирование, слабосвязную архитектуру и проектирование в целом
4 min
К хорошим постам «Код в стиле «дамп потока сознания»» и «Микро-рефакторинг, о котором мы так часто забываем».
Конечно, многие из вас обнаружат, что предлагаемые ниже ответы на эти вопросы весьма знакомы, но возьмите эту статью на заметку, так как кидать линк зачастую все же существенно комфортнее, чем распинаться в объяснениях и доказательствах очевидного.
- Почему большинство программистов не любят «читать чужой код»?
- Почему рефакторинг и внесение изменений становятся серьезной проблемой?
- Почему так часто случается, что легче переписать с нуля?
- Почему одни программисты называют других хорошими или плохими словами?
Конечно, многие из вас обнаружат, что предлагаемые ниже ответы на эти вопросы весьма знакомы, но возьмите эту статью на заметку, так как кидать линк зачастую все же существенно комфортнее, чем распинаться в объяснениях и доказательствах очевидного.
GSA: Препарируем Google Search Appliance в виртуальной машине
5 min

Последние годы, с интересом почитывая о персональных поисковых системах в веселых желтых коробках имени Google, я периодически гуглил по словам GSA, Google Search Appliance, reverse engineering и, чего греха таить, hack, DIY, disk dump и т.п. Но ничего, кроме официальных пресс-релизов и переписки счастливых (?) обладателей с группой поддержки, я не встречал.
Иногда звучали на форумах робкие вопросы вроде «а как бы рута мне получить» или «попасть в GSA по ssh», но на все подобные вопросы ответ был один — только группа поддержки Google знает пароли. И никому не скажет. Удивительно, но я не встречал в интернете никаких попыток собрать «хакинтош» на движке Гугла, или по живому коду разобраться в алгоритме ранжирования страниц.
Ситуация слегка изменилась в 2008 году, когда на волне эйфории от виртуализации, Google выкатил VGSA – бесплатную виртуальную машину для Vmware с ограниченной до 50 тысяч документов лицензией. Впрочем, особого энтузиазма это в интернете не вызвало, в 2009 году проект был свернут и большинство ссылок в Гугле на VGSA стали возвращать 404 (заметьте – самим же Гуглом). Ссылку на релиз от 2008 года можно найти довольно легко. Ссылка на версию 2009 сохранилась лишь на паре китайских сайтов.
О том, как я поставил vgsa_20090210 на ESX 5.1 и увидел много чего интересного, можно прочитать ниже.
Рекомендации по проектированию пользовательских интерфейсов (по книге Раскина «Интерфейс»). Часть 1
6 min
Материал, который я собираюсь изложить — это обобщение книги Джефа Раскина, дополненное некоторыми рассуждениями на основе собственного опыта. Первый пост в этой серии — «Вступление» — находится здесь.
В первой части описаны особенности человеческого восприятия, важные для проектирования интерфейса, а также принципы построения интерфейса.
В первой части описаны особенности человеческого восприятия, важные для проектирования интерфейса, а также принципы построения интерфейса.
Watir: простой парсинг сложных сайтов
4 min
 Каждый, кто пишет парсеры, знает, что можно распарсить сто сайтов, а на сто-первом застрять на несколько дней. Структура очередного отмороженного сайта может быть сколь угодно сложной, и, когда дело касается сжатых javascript-ов и ajax-запросов, расшифровать их и извлечь информацию с помощью обычного curl-а и регекспов становится дороже самой информации.
Каждый, кто пишет парсеры, знает, что можно распарсить сто сайтов, а на сто-первом застрять на несколько дней. Структура очередного отмороженного сайта может быть сколь угодно сложной, и, когда дело касается сжатых javascript-ов и ajax-запросов, расшифровать их и извлечь информацию с помощью обычного curl-а и регекспов становится дороже самой информации. Грубо говоря, проблема в том, что в браузере работает javascript, а на сервере его нет. Нужно либо писать интерпретатор js на одном из серверных языков (jParser и jTokenizer), либо ставить на сервер браузер, посылать в него запросы и вытаскивать итоговое dom-дерево.
В древности в таких случаях мы строили свой велосипед: на отдельной машине запускали браузер, в нем js, который постоянно стучался на сервер и получал от него задания (джобы), сам сайт грузился в iframe, а скрипт извне отправлял dom-дерево ифрейма обратно на сервер.
Сейчас появились более продвинутые средства — xulrunner (crowbar) и watir. Первый — безголовый firefox. У crowbar есть даже ff-плагин для визуального выделения нужных данных, который генерит специальный парсер-js-код, однако там не поддерживаются cookies, а допиливать неохота. Watir позиционируется разработчиками как средство отладки, но мы будем его использовать по прямому назначению и в качестве примера вытащим какие-нибудь данные с сайта travelocity.com.
Почему мы (всё ещё) верим в удалённую работу
5 min
Translation
На дворе 2013, прошло почти три года с момента, как мы заработали первую сумму денег и начали расти из компании из четырёх сотрудников. Недавно Джефф написал хороший пост об удалённой работе, в основном о нашем плане того, как заставить это работать. Сейчас, по прошествии нескольких лет, я бы хотел написать, что же на самом деле происходит.
Итак, что мы представляем из себя на данный момент? В Stack Exchange сейчас работают 75 человек, примерно половина занимается продажами (маркетинг и реклама), остальные же — созданием продуктов (разработка, дизайн, управление сообществами). БОльшая часть удалённо работающих сотрудников занимаются разработкой: 16 удалённых и 18 офисных разработчиков, сисадминов, дизайнеров. У нас команда-гибрид, которая, как мне кажется, лучшая в мире. Я руковожу отделом проектирования, так что буду говорить в основном о разработчиках, но это применимо ко всем должностям.
Итак, что мы представляем из себя на данный момент? В Stack Exchange сейчас работают 75 человек, примерно половина занимается продажами (маркетинг и реклама), остальные же — созданием продуктов (разработка, дизайн, управление сообществами). БОльшая часть удалённо работающих сотрудников занимаются разработкой: 16 удалённых и 18 офисных разработчиков, сисадминов, дизайнеров. У нас команда-гибрид, которая, как мне кажется, лучшая в мире. Я руковожу отделом проектирования, так что буду говорить в основном о разработчиках, но это применимо ко всем должностям.