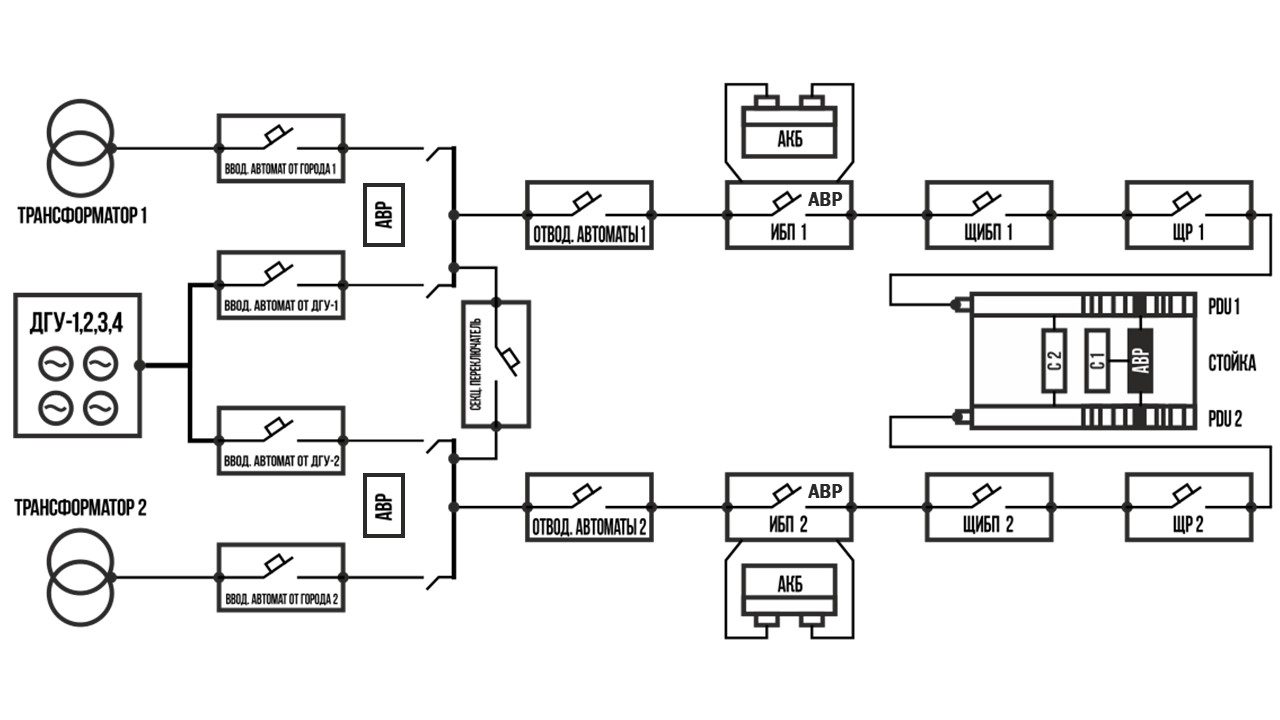
Представьте, что у вас полная серверная инженерного оборудования: несколько десятков кондиционеров, куча ДГУ и бесперебойников. Чтобы «железо» работало как надо, вы регулярно проверяете его работоспособность и не забываете о профилактике: проводите тестовые запуски, проверяете уровень масла, меняете детали. Даже для одной серверной нужно хранить много информации: реестр оборудования, список расходников на складе, график профилактических работ, а еще гарантийные документы, договоры с поставщиками и подрядчиками.
Теперь умножим количество залов на десять. Появились вопросы логистики. На каком складе что хранить, чтобы не бегать за каждой запчастью? Как вовремя пополнять запасы, чтобы внеплановый ремонт не застал врасплох? Если оборудования много, держать все технические работы в голове невозможно, а на бумаге – сложно. Тут на помощь приходит MMS, или maintenance management system, – система управления техническим обслуживанием оборудования (ТО).

В MMS мы составляем графики профилактических и ремонтных работ, храним инструкции для инженеров. Не у всех ЦОДов такая система есть, многие считают ее слишком дорогим решением. Но на своем опыте мы убедились, что важен не инструмент, а подход к работе с информацией. Первую систему мы создали в Excel и постепенно доработали ее до программного продукта.
Вместе с alexddropp мы решили поделиться опытом развития собственной MMS. Я покажу, как развивалась система и как помогла внедрить лучшие практики ТО. Алексей расскажет, как получил MMS в наследство, что изменилось за это время и как система облегчает жизнь инженерам сейчас.
Теперь умножим количество залов на десять. Появились вопросы логистики. На каком складе что хранить, чтобы не бегать за каждой запчастью? Как вовремя пополнять запасы, чтобы внеплановый ремонт не застал врасплох? Если оборудования много, держать все технические работы в голове невозможно, а на бумаге – сложно. Тут на помощь приходит MMS, или maintenance management system, – система управления техническим обслуживанием оборудования (ТО).
В MMS мы составляем графики профилактических и ремонтных работ, храним инструкции для инженеров. Не у всех ЦОДов такая система есть, многие считают ее слишком дорогим решением. Но на своем опыте мы убедились, что важен не инструмент, а подход к работе с информацией. Первую систему мы создали в Excel и постепенно доработали ее до программного продукта.
Вместе с alexddropp мы решили поделиться опытом развития собственной MMS. Я покажу, как развивалась система и как помогла внедрить лучшие практики ТО. Алексей расскажет, как получил MMS в наследство, что изменилось за это время и как система облегчает жизнь инженерам сейчас.