Одной из актуальных проблем информационной безопасности является конфиденциальность сообщений, которая обеспечивается в RSA-подобных шифрах применением криптографической защиты сообщений. Подобная защита успешно реализуется при знании закона распределения делителей составного числа (модуля кольца вычетов) в натуральном ряде чисел (НРЧ) и наличии криптографической системы (КГС), в рамках которой и циркулируют сообщения.

Дмитрий @flamehj
Пользователь
Разбираем особенности алгоритмов CatBoost и LightGBM: какой от них профит
Medium
11 min
Review

Всем привет. Меня зовут Артур. Готовясь к выступлению на внутреннем митапе по теме особенности алгоритмов у CatBoost и LightGBM, я понял, что не смог найти единого места, где были бы понятным языком рассказаны основные особенности того, что алгоритмически работает под капотом у CatBoost и LightGBM. Причём не формальные записи алгоритмов на псевдокоде, а понятные пошаговые инструкции. Так появилась эта статья.
Как сделать свой AnythingGPT, отвечающий на вопросы так, как вам это необходимо (Python, OpenAI Embeddings, ChatGPT API)
Medium
17 min
Tutorial

Всем привет! Недавно я на практике применил одно интересное решение, которое давно хотел попробовать, и теперь готов рассказать, как своими руками такое можно сделать для любой другой аналогичной задачи. Речь пойдет о создании своей кастомизированной версии ChatGPT, которая отвечает на вопросы, учитывая большую базу знаний, которая по длине не ограничивается размером промта (то есть вы бы не смогли просто добавить всю информацию перед каждым вопросом к ChatGPT). Для этого будем использовать контекстные эмбеддинги от OpenAI (для действительно качественного поиска релеватных вопросов из базы знаний) и сам СhatGPT API (для оборачивания ответов в натуральный человеческие ответы). При этом, также предполагается, что ассистент может отвечать не только на прямо указанные в Q&A вопросы, но и на такие вопросы, на которые смог бы отвечать человек, который ознакомился с Q&A. Кому интересно научиться делать простых ботов, отвечающих по большой базе знаний, добро пожаловать под кат.
Монотонная кубическая интерполяция
Medium
8 min
Review
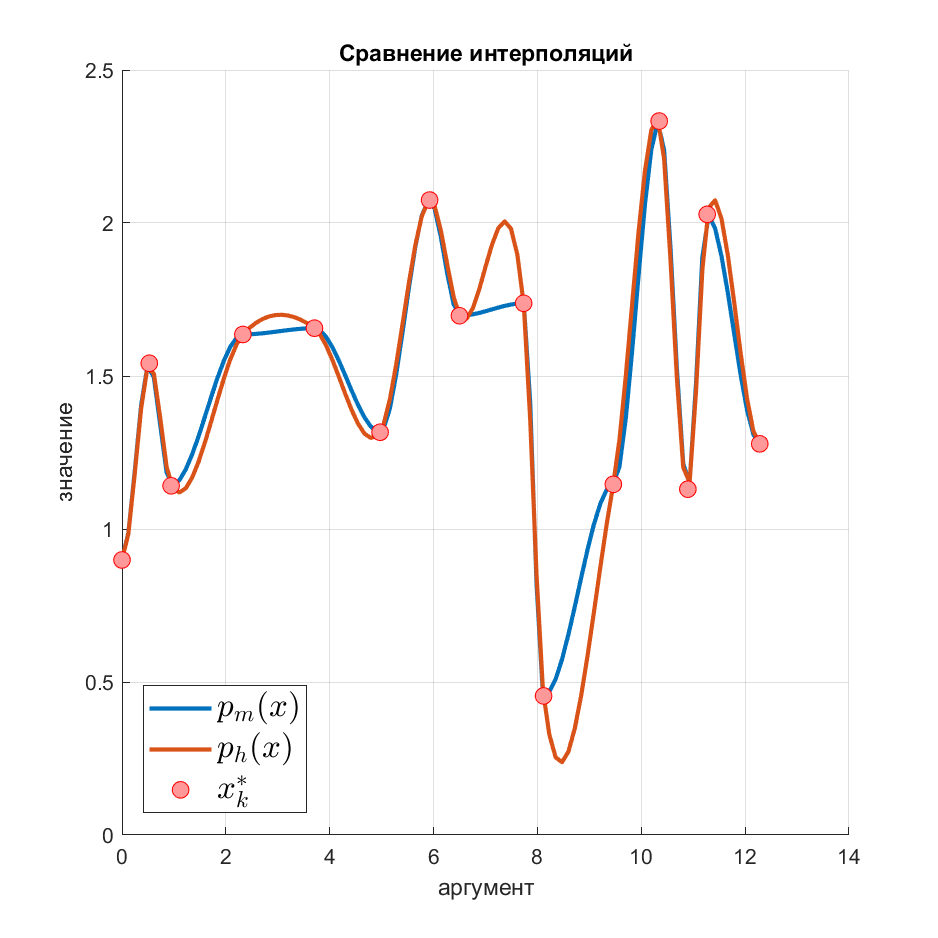
Привет, Хабр!
В данной статье разобран алгоритм монотонной кубической интерполяции, предложенный Фритчем и Карлосоном в работе [1].
На рисунке красным обозначен результат обычной кубической интерполяции Эрмита, а синим - монотонной, кругами - опорные точки траектории.
Примеры кода написаны на C++, исходники всей библиотеки лежат здесь. Также написана копия библиотеки на Java, исходники лежат здесь.
Прибытие тензорного поезда. Как достижения мультилинейной алгебры помогают преодолеть проклятие размерности
Hard
6 min
Case
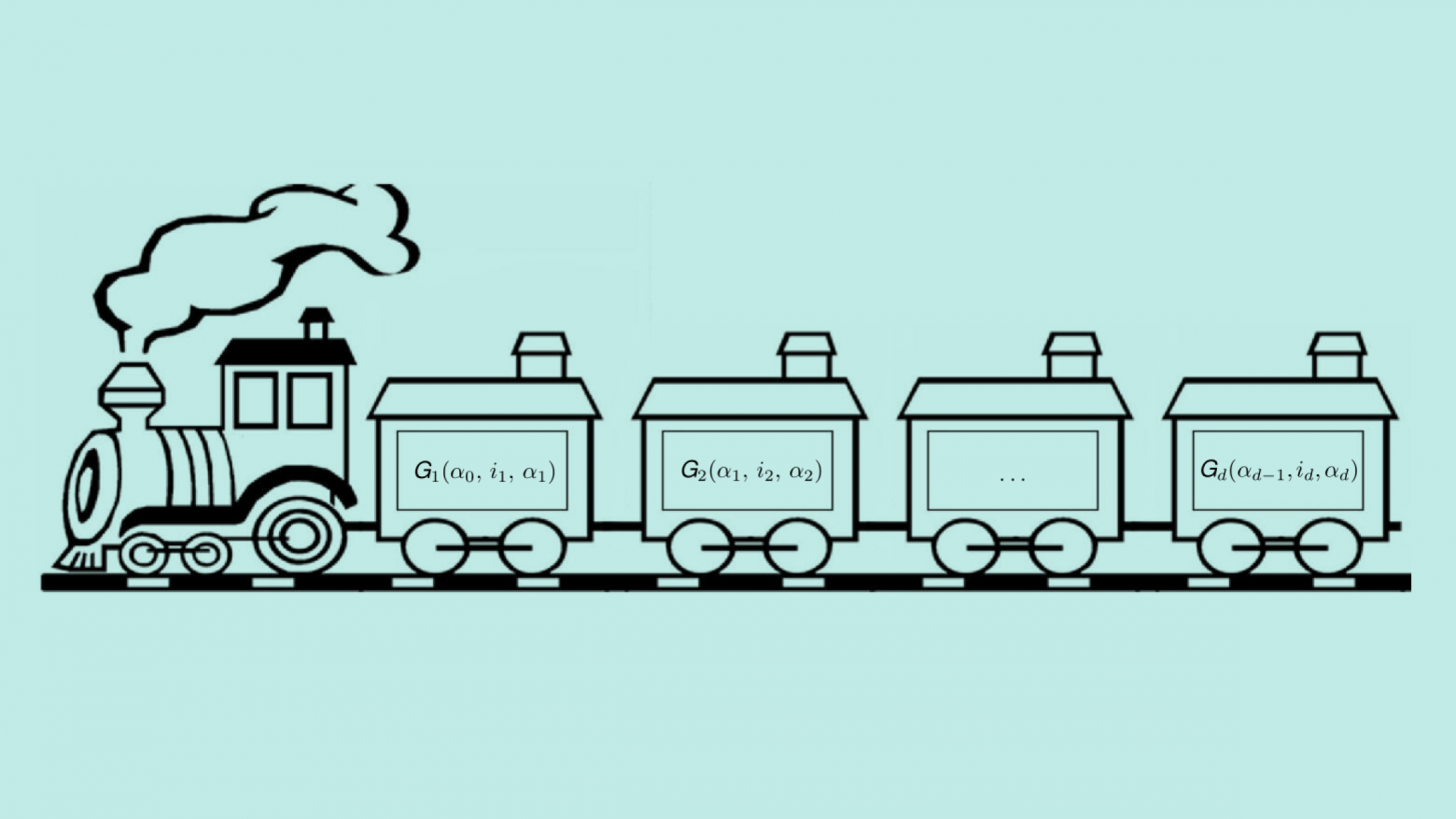
Привет! Меня зовут Глеб Рыжаков, я научный сотрудник Сколтеха. Я занимаюсь математикой, а точнее, линейной алгеброй, и её приложениями к практическим задачам. Сегодня я расскажу вам о нашем исследовании, которое может помочь справиться с проблемой проклятия размерности, которая возникает во множестве статистических задач, включая машинное обучение.
Понятие «проклятие размерности» появилось в середине прошлого века в пионерской работе Ричарда Беллмана, посвященной методам решения сложных задач путём разбиения их на более простые подзадачи. Сегодня оно понимается в более общем смысле, а именно как экспоненциальный — O(nd) — рост количества необходимых данных и, как следствие, количества памяти, необходимой для их хранения, с ростом размерности пространства d. Когда задачу можно свести к работе с многомерными массивами в общем случае комплексных чисел, удобно говорить о d-мерных тензорах и использовать достижения мультилинейной алгебры. Хорошая новость заключается в том, что там существует такая процедура, как тензорное разложение, которое в ряде случаев может помочь преодолеть проклятие размерности.
Разделяй и властвуй. Повышение эффективности алгоритмов. Часть 2
Medium
5 min

Ссылка на первую часть.
Мастер‑теорема
На примере из прошлой части, попробуем сформулировать и обобщить принцип «Разделяй и властвуй». Мы беремся за проблему, размера n, делим эту проблему на подзадачи размером n/b. Количество таких подзадач обозначим числом a. И еще имеется задача скомпоновать результаты выполнения этих a задач размером n/b в итоговый результат для задачи размера n, который будем считать задачей полиномиальной сложности степени c, O(nc) . Если задача компоновки будет не полиномиальной, то все изложение резко усложнится. Поэтому, давайте позволим задаче компоновки быть полиномиальной, тем более в это попадает очень большое количество алгоритмов.
Классификация аудиофайлов с библиотекой Librosa
Medium
10 min
Review

Привет Хабр! В этой статье поработаем с аудиофайлами, используя библиотеку librosa и алгоритмы Machine learning.
Сначала немного поговорим о том, что такое аудиосигнал. Аудиосигнал представляет собой сложный сигнал, состоящий из нескольких одночастотных звуковых волн, которые распространяются вместе как изменение давления в среде. Каждый аудиосигнал имеет свои определенные характеристики, например, такие как частота, амплитуда, ширина полосы, децибел и т.д. Число волн, производимых сигналом за одну секунду называется частотой. Амплитуда показывает интенсивность звука, то есть является высотой волны.
Как IndVarSimplification применяет математику в вашем коде
Medium
3 min

Многие оптимизации в компиляторе выглядят естественными. Но IndVarSimplification, предмет этой статьи, сильно выделяется среди них. Это та оптимизация, которая сначала кажется темной магией, но за маской на самом деле скрывается математика.
В этой статье я постарался разобраться, как работает IndVarSimplification. Будет немного кода на Rust, чтение ассемблера и копание в коде LLVM.
Изучаем ёмкостную трёхточку и собираем FM передатчик
Medium
11 min

Сегодняшний опыт позволит нам увидеть на экране осциллографа, какие параметры цепи влияют на работу LC-генератора Колпитца, и откуда берутся искажения формы волны.
После чего соберём маленький транзисторный УКВ ЧМ передатчик на базе такого генератора. Не пугайтесь, он совсем маломощный (как MP3-модуляторы в гнезде автомобильного прикуривателя) и не нарушает законов о радиосвязи.
А чтобы услышать, что передатчик вещает, соберем ещё и FM радиоприёмник.
Основы линейной регрессии
13 min
Здравствуй, Хабр!
Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
! Осторожно, трафик! В статье присутствует заметное число изображений для иллюстраций, часть в формате gif.
Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
! Осторожно, трафик! В статье присутствует заметное число изображений для иллюстраций, часть в формате gif.
Как принять сигнал мобильной связи на приёмник цифрового телевидения: теория и практика
Medium
20 min
Tutorial

Несмотря на вроде бы абсурдный заголовок, принять и декодировать сигналы мобильной связи действительно можно на телевизионный приёмник, хотя и с некоторыми оговорками. Не все и не на любой приёмник, но такая возможность есть. Чтобы вам это выполнить самим, понадобятся:
- ноутбук,
- DVB-Т-приёмник в виде USB-брелока,
- свободный флеш-накопитель для записи дистрибутива Linux на него.
Чтобы лучше разобраться в работе GSМ, нужно два мобильных телефона или телефон и GSM-модем.
Если вас заинтересовала эта тема, и вы хотите расширить свои знания, добро пожаловать под кат.
Выращиваем ИИ — Генетические алгоритмы: введение
19 min
Tutorial
(сгенерированое изображение)
Существует множество способов создать искусственную нейронную сеть или даже "искусственный интеллект". Но все эти способы обескураживают, от части сложностью которую я не до конца понимаю, отчасти от того, что все сводится к математическим формулам.
В таких подходах нет нечего плохого, они помогают решать поставленные перед ними задачи. Но похоже мне очень хочется написать велосипед.
FTM, который написал MUSIC: точное определение местоположения Wi-Fi-устройств в условиях многолучевости.Часть 2/3
Medium
14 min
Translation

Статья «When FTM Discovered MUSIC: Accurate WiFi-based Ranging in the Presence of Multipath» опубликована в материалах Международной конференции IEEE по компьютерным коммуникациям, которая прошла в Торонто, Канада, с 6 по 9 июля 2020 г. (IEEE International Conference on Computer Communications, INFOCOM 2020). Идеи, изложенные в этой публикации, получили дальнейшее развитие, в частности, в статье «FSI: A FTM Calibration Method Using Wi-Fi Physical Layer Information» («FSI: метод калибровки FTM с использованием информации о физическом уровне Wi-Fi»), опубликованной во 2-й части материалов 17-й Международной конференции по беспроводным алгоритмам, системам и приложениям, которая прошла в Даляне, Китай, с 24 по 26 ноября 2022 г. (Wireless Algorithms, Systems, and Applications; WASA 2022).
Математическая продлёнка. Математика кривого пропеллера
Easy
3 min

Вы, наверняка, знаете отчего "гнётся и рвётся" пропеллер на цифровых фото и видео. А какую именно форму принимают лопасти винта? Как зависит их видимая форма от скорости вращения? И причём здесь гиперболы?
Приглашаю любопытных любителей самолётов на небольшое занятие математического кружка.
Искусственный интеллект и странные аттракторы
Medium
10 min
Case
Я уже довольно немолодой человек с консервативными взглядами на развитие новых технологий. Все, что связано с Искусственным Интеллектом, никогда не занимало меня настолько, чтобы уделять ему достаточно много времени или хотя бы следить за последними новостями в этой области. Однако с неделю назад искусственный интеллект сам меня нашел и предложил свои услуги. Сидел я себе в Скайпе, общался по работе, и вдруг в моём списке чатов появился новый чат с пользователем Bing и новое сообщение в нём:
Bing 13:21
Привет, это Bing! Я здесь, чтобы помочь вам. (smileeyes)
Математическая оптимизация и моделирование в PuLP: задача о назначениях
Easy
11 min
Tutorial
Приветствую! Я, Ложкинс Алексей, консультант и разработчик оптимизационных решений и математических моделей для бизнеса. Это первая в цикле работ обучающая статья, часть личного образовательного проекта "Make optimization simple". Цель проекта – продемонстрировать доступность технологий и показать на примерах, что моделировать можно без глубокого математического фундамента.
Из статьи вы узнаете об основных компонентах математической оптимизационной задачи на примере классической задачи о назначениях, в частности, распределение машин такси на заказы. Далее, я покажу, как реализовать программный прототип математической модели посредством Python и библиотеки PuLP, а также продемонстрирую, как получить оптимальное решение задачи всего в одной строке кода без реализации специальных алгоритмов.
Быстрое нахождениe остатка от деления больших чисел для делителей специального вида
Medium
11 min
Tutorial
В этой статье я расскажу об одном способе вычисления x mod p, для p вида (2 ** n - omega), причём omega значительно меньше 2 ** n. Напишу генератор констант на Python. Приведу пару игрушечных примеров на С++, для которых может быть выполнено исчерпывающее тестирование для всех возможных аргументов. А в качестве серьёзной проверки - вычислю 97! mod (2 ** 256 - 2 ** 32 - 977).
Обобщай это, обобщай то
Medium
7 min
В рамках этой статьи я вновь попытаюсь аккуратно стереть границы между абстрактной алгеброй и объектно-ориентированным программированием, чтобы посмотреть на то, что получится на стыке. Ознакомиться с предыдущими трудами на эту тему можно по ссылкам: раз и два.
На этот раз мы остановимся на связи между алгебраическими кольцами и алгоритмом поиска выпуклой оболочки множества точек (convex hull).
Регрессионный анализ в DataScience. Часть 3. Аппроксимация
Medium
72 min
Tutorial
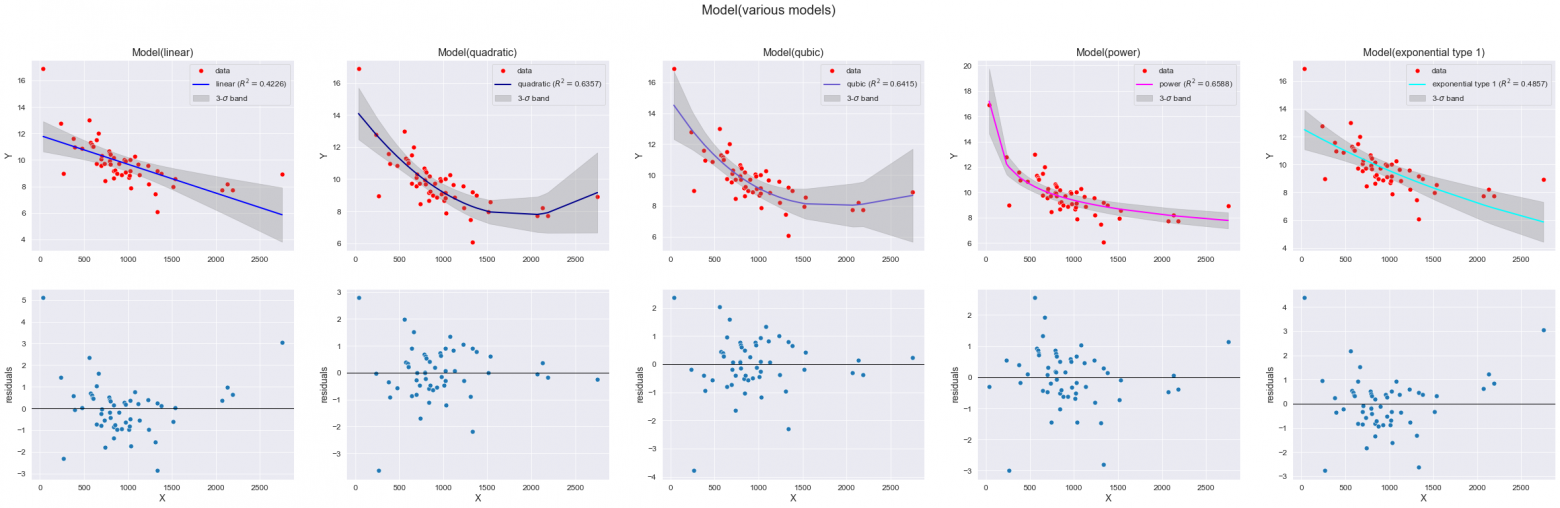
В предыдущих обзорах (https://habr.com/ru/articles/690414/, https://habr.com/ru/articles/695556/) мы рассматривали линейную регрессию. Пришло время переходить к нелинейным моделями. Однако, прежде чем рассматривать полноценный нелинейный регрессионный анализ, остановимся на аппроксимации зависимостей.
Про аппроксимацию написано так много, что, кажется, и добавить уже нечего. Однако, кое-что добавить попытаемся.
При выполнении анализа данных может возникнуть потребность оперативно построить аналитическую зависимость. Подчеркиваю - речь не идет о полноценном регрессионном анализе со всеми его этапами, проверкой гипотез и т.д., а только лишь о подборе уравнения и оценке ошибки аппроксимации. Например, мы хотим оценить характер зависимости между какими-либо показателями в датасете и принять решение о целесообразности более глубокого исследования. Подобный инструмент предоставляет нам тот же Excel - все мы помним, как добавить линию тренда на точечном графике:
Система синтеза асинхронных схем Petrify: проблемы и их решение
6 min
Сказать, что Petrify решает, поставленные перед ней задачи, можно лишь с большой натяжкой. Вернее она кое-что может для небольших заданий (где количество сигналов едва превышает 20), проблема взрыва состояний так и не была решена. Но и для таких задач удовлетворительный результат не гарантирован. Декомпозиция далеко не всегда дает приемлемые результаты.
В чем причина этих неудач? Я бы назвал 3 основные:
1. Увлеченность STG. Да, это красивая, забавная модель, очень интересно играть маркерами и т.п. Но, подумайте, процесс переключения сигналов схемы это такой же процесс как выполнение какой-либо программы. Мы используем для описания программы сети Петри? Для чего тогда они нужны при описании процессов, происходящих в схеме? В результате разработчики Petrify львиную долю своих усилий потратили на изучение свойств сетей Петри. А собственно задачи синтеза схем так и не были решены.
2. Упор на «вычислительность». Под этим я подразумеваю убежденность, что для синтеза схем обязательно нужно вычислять логические функции. Как результат, вместо решения задач синтеза, исследовались только возможности уменьшения таких вычислений.
3. Неспособность разобраться в причинах возникающих проблем. Но об этом ниже.
В чем причина этих неудач? Я бы назвал 3 основные:
1. Увлеченность STG. Да, это красивая, забавная модель, очень интересно играть маркерами и т.п. Но, подумайте, процесс переключения сигналов схемы это такой же процесс как выполнение какой-либо программы. Мы используем для описания программы сети Петри? Для чего тогда они нужны при описании процессов, происходящих в схеме? В результате разработчики Petrify львиную долю своих усилий потратили на изучение свойств сетей Петри. А собственно задачи синтеза схем так и не были решены.
2. Упор на «вычислительность». Под этим я подразумеваю убежденность, что для синтеза схем обязательно нужно вычислять логические функции. Как результат, вместо решения задач синтеза, исследовались только возможности уменьшения таких вычислений.
3. Неспособность разобраться в причинах возникающих проблем. Но об этом ниже.