Недавно на isocpp.org была опубликована ссылка на статью Eli Bendersky «Perfect forwarding and universal references in C++». В этой небольшой статье есть простой ответ на простой вопрос — для решения каких задач и как нужно использовать rvalue-ссылки.

flashnik @flashnikread-only
Head of Data Science
Кэш в многопроцессорных системах. Когерентность кэша. Протокол MESI
3 мин
Привет, Хабр!
В свое время это тема показалась мне очень интересной, поэтому я решил поделиться своими скромными знаниями с вами. Данная статья не претендует на полное детальное описание, скорее это краткий обзор.
Ни для кого не секрет, что в современных компьютерах доступ к памяти могут одновременно иметь несколько независимых процессоров (ядер, трэдов). Каждый из них имеет свои приватные кэши, в которых хранятся копии необходимых линий, а некоторые из них при этом локально модифицированы. Встает вопрос, а что если одна и та же линия одновременно понадобится нескольким процессорам. Не сложно сделать вывод, что для корректной работы системы необходимо обеспечить единое пространство памяти для всех процессоров.
Для обеспечения этого были придуманы специальные протоколы когерентности. Когерентность кэша — свойства кэш-памяти, означающее целостность данных, хранящихся в локальных кэшах, разделяемой системы. Каждая ячейка кэша имеет флаги, описывающие, как ее состояние соотносится с состоянием ячейки с таким же адресом в других процессорах системы.
При изменении состояния текущей ячейки необходимо каким-то образом сообщить об этом остальным кэшам. Например, генерируя широковещательных сообщения, доставляемые по внутренней сети многопроцессорной системы.
Было придумано множество протоколов когерентности, отличающиеся алгоритмами, количеством состояний и, как следствие скоростью работы и масштабируемостью. Большинство современных протоколов когерентности представляют вариации протокола MESI [1]. По этой причине мы его и рассмотрим.
В свое время это тема показалась мне очень интересной, поэтому я решил поделиться своими скромными знаниями с вами. Данная статья не претендует на полное детальное описание, скорее это краткий обзор.
Введение
Ни для кого не секрет, что в современных компьютерах доступ к памяти могут одновременно иметь несколько независимых процессоров (ядер, трэдов). Каждый из них имеет свои приватные кэши, в которых хранятся копии необходимых линий, а некоторые из них при этом локально модифицированы. Встает вопрос, а что если одна и та же линия одновременно понадобится нескольким процессорам. Не сложно сделать вывод, что для корректной работы системы необходимо обеспечить единое пространство памяти для всех процессоров.
Для обеспечения этого были придуманы специальные протоколы когерентности. Когерентность кэша — свойства кэш-памяти, означающее целостность данных, хранящихся в локальных кэшах, разделяемой системы. Каждая ячейка кэша имеет флаги, описывающие, как ее состояние соотносится с состоянием ячейки с таким же адресом в других процессорах системы.
При изменении состояния текущей ячейки необходимо каким-то образом сообщить об этом остальным кэшам. Например, генерируя широковещательных сообщения, доставляемые по внутренней сети многопроцессорной системы.
Было придумано множество протоколов когерентности, отличающиеся алгоритмами, количеством состояний и, как следствие скоростью работы и масштабируемостью. Большинство современных протоколов когерентности представляют вариации протокола MESI [1]. По этой причине мы его и рассмотрим.
Автономное копирование данных в новый телефон на Android
2 мин
Сегодня я расскажу, как можно перенести данные из одного телефона на Android в другой без подключения к интернет.

С помощью этого метода удастся перенести:
• Контакты с фотографиями и привязкой к рингтонам
• Историю звонков
• СМС и ММС
• Все приложения
• Настройки рабочих столов (при условии, что вы пользуетесь GoLauncher EX)
• Пользовательские рингтоны
• Фотографии
• Музыку
Не удастся перенести:
• Настройки и данные большинства программ
С помощью этого метода удастся перенести:
• Контакты с фотографиями и привязкой к рингтонам
• Историю звонков
• СМС и ММС
• Все приложения
• Настройки рабочих столов (при условии, что вы пользуетесь GoLauncher EX)
• Пользовательские рингтоны
• Фотографии
• Музыку
Не удастся перенести:
• Настройки и данные большинства программ
Граф интересов (Interest graph): новый принцип взаимодействия в сети
6 мин
Пару месяцев назад меня очень тронула публикация Идеальная социальная сеть. Автор этой публикации, arilou-campe, обозначил доминирующие принципы, по которым выстраивается большая часть социального взаимодействия в современной сети, а затем он попробовал предположить, на каких принципах будет выстраиваться это взаимодействие в ближайшем будущем.
Я хочу продолжить и уточнить его мысль, озвучить несколько важных и плодотворных, на мой взгляд, концептов («граф интересов» — один из них), вокруг которых сегодня ведётся дискуссия о будущем развитии сети, а также привести в качестве примера несколько проектов (над одним из которых я сам сейчас работаю), уже реализующих на практике новые принципы социального взаимодействия: те самые принципы, которые могут стать доминирующими в самом ближайшем будущем.
Я хочу продолжить и уточнить его мысль, озвучить несколько важных и плодотворных, на мой взгляд, концептов («граф интересов» — один из них), вокруг которых сегодня ведётся дискуссия о будущем развитии сети, а также привести в качестве примера несколько проектов (над одним из которых я сам сейчас работаю), уже реализующих на практике новые принципы социального взаимодействия: те самые принципы, которые могут стать доминирующими в самом ближайшем будущем.
Чему мы должны учить разработчиков нового программного обеспечения? Почему?
11 мин
Перевод
Требуются существенные изменения в обучении компьютерной науке, для лучшего соответствия потребностям индустрии.

Компьютерная наука должна быть в центре развития систем программного обеспечения. В противном случае мы должны полагаться на индивидуальный опыт и практические методы, что в конечном итоге приведёт к менее продуктивным, менее надёжным системам, разработанным и поддерживающимся по неоправданно высоким ценам. Нам нужны изменения в образовании, которые позволят улучшить производственную практику.
Во многих местах существует разрыв между обучением компьютерной науке и потребностями индустрии. Взгляните на следующую ситуацию:
Знаменитый профессор компьютерной науки (с гордостью): «Мы не учим программированию; мы обучаем компьютерной науке.»
Производственный менеджер: «Они не способны программировать.»
Во многом они оба правы, и не только на поверхностном уровне. Задача научного сообщества состоит не в том, чтобы обучать посредственных программистов, а индустрия не требует только «всесторонне развитых, высокообразованных мыслителей» и «учёных».
Другой профессор компьютерной науки: «Я не написал ни одной строчки кода.»
Компьютерная наука должна быть в центре развития систем программного обеспечения. В противном случае мы должны полагаться на индивидуальный опыт и практические методы, что в конечном итоге приведёт к менее продуктивным, менее надёжным системам, разработанным и поддерживающимся по неоправданно высоким ценам. Нам нужны изменения в образовании, которые позволят улучшить производственную практику.
Проблема
Во многих местах существует разрыв между обучением компьютерной науке и потребностями индустрии. Взгляните на следующую ситуацию:
Знаменитый профессор компьютерной науки (с гордостью): «Мы не учим программированию; мы обучаем компьютерной науке.»
Производственный менеджер: «Они не способны программировать.»
Во многом они оба правы, и не только на поверхностном уровне. Задача научного сообщества состоит не в том, чтобы обучать посредственных программистов, а индустрия не требует только «всесторонне развитых, высокообразованных мыслителей» и «учёных».
Другой профессор компьютерной науки: «Я не написал ни одной строчки кода.»
Альтернативные аллокаторы памяти
13 мин
Перевод
Написал Стивен Тови в 2:29 утра по программированию (шутка юмора Google Translate)
Вступление от себя: эта заметка, прорекламированная Алёной C++, предназначена в основном разработчикам игр для консолей, но будет, наверное, полезна и всем, кому приходится сталкиваться с экстремальным аллоцированием динамической памяти. Возможно, любители посравнивать управление памятью в C++ и Java тоже найдут над чем задуматься.
Оригинал с небезынтересной дискуссией в комментариях: altdevblogaday.org/2011/02/12/alternatives-to-malloc-and-new
Обязательная вступительная басня
Мне очень нравятся суши. Это вкусно и удобно. Мне нравится, что можно с бухты-барахты, не тратя целый обеденный час, зайти в суши-ресторан с конвейером, занять место и взять что-то свежее и вкусное с ленты. Но при всём при этом, чего мне реально не хотелось бы, так это быть официантом в суши-ресторане, особенно если бы моей обязанностью было бы рассаживать посетителей по местам.
Экспериментальное определение характеристик кэш-памяти
6 мин
В ряде случаев (например, для тонкой оптимизации программы под конкретный компьютер) полезно знать характеристики кэш-подсистемы: количество уровней, время доступа к каждому уровню, их размер и ассоциативность, и т.п.
Для одноразовой оптимизации необходимые значения можно посмотреть в спецификации на компьютер, но когда требуется автоматическая оптимизация (например, во время сборки и установки программы), характеристики приходится определять косвенно, по результатам прогона специального набора тестов.
Удобная тестовая программа для Linux —
Пример графика, который был получен этой программой на реальной системе:
Для одноразовой оптимизации необходимые значения можно посмотреть в спецификации на компьютер, но когда требуется автоматическая оптимизация (например, во время сборки и установки программы), характеристики приходится определять косвенно, по результатам прогона специального набора тестов.
Удобная тестовая программа для Linux —
lat_mem_rd из пакета тестов lmbench. Её работа заключается в том, что она выделяет в памяти массив и читает его элементы с заданным шагом, циклически проходя по массиву снова и снова. Затем выделяется массив большего размера, и т.д. Для каждого значения шага и размера массива подсчитывается среднее время доступа.Пример графика, который был получен этой программой на реальной системе:
«Софт за пределами морали». Глава вторая «Типы скриптов»
4 мин
часть 1.1
часть 1.2
Я не буду писать здесь о вирусах и троянах, о связках сплойтов и сервисах продающих инсталлы.
Напишу лишь о том, с чем имел удовольствие познакомиться лично.
Я сознательно буду употреблять слово «скрипты», потому что в моей практике был только php5, да и отличий от системных приложений не так уж и много.
«Чекеры»
Назначение — проверка аккаунтов/имейлов/прокси на валидность.
Аккаунты также можно проверять на активированность по имейлу/наличие фото/баланса на счету и собирать прочую информацию.
часть 1.2
Я не буду писать здесь о вирусах и троянах, о связках сплойтов и сервисах продающих инсталлы.
Напишу лишь о том, с чем имел удовольствие познакомиться лично.
Я сознательно буду употреблять слово «скрипты», потому что в моей практике был только php5, да и отличий от системных приложений не так уж и много.
«Чекеры»
Назначение — проверка аккаунтов/имейлов/прокси на валидность.
Аккаунты также можно проверять на активированность по имейлу/наличие фото/баланса на счету и собирать прочую информацию.
О смысле. Деревья синтаксического подчинения (деревья подчинения)
2 мин
В предыдущем посте я обмолвился о деревьях подчинения и использовал (возможно, зря) спорный пример с «туманностью».
Теперь просто необходимо объяснить, почему я интерпретировал данный текст таким образом. Хотя, как оказалось, по комментариям специалистов в творчестве Пушкина – неверно, но будем рассматривать данный пример не в аспекте исторической точности, а в аспекте способов интерпретации текста на естественном языке машиной.
Начнём с определения того, что же такое деревья синтаксического подчинения (в простонородье – деревья подчинения)? Это упорядоченный граф (т.е. дерево), где узлами являются слова предложения, а их иерархия и система подчинения определяет, какие слова являются главными в предложении и какие от каких зависят.
Для наглядности приведу пару снимков того, что я имею в виду:
Теперь просто необходимо объяснить, почему я интерпретировал данный текст таким образом. Хотя, как оказалось, по комментариям специалистов в творчестве Пушкина – неверно, но будем рассматривать данный пример не в аспекте исторической точности, а в аспекте способов интерпретации текста на естественном языке машиной.
Начнём с определения того, что же такое деревья синтаксического подчинения (в простонородье – деревья подчинения)? Это упорядоченный граф (т.е. дерево), где узлами являются слова предложения, а их иерархия и система подчинения определяет, какие слова являются главными в предложении и какие от каких зависят.
Для наглядности приведу пару снимков того, что я имею в виду:
Использование скрытых Марковских моделей для снятия морфологической омонимии
3 мин
В предыдущем посте я писал о том, что такое морфологическая омонимия (пример со словом «стали») и упоминал о том, что для её разрешения используют скрытые Марковские модели (Hidden Markov Model, HMM).
Вначале немного о разметке теста (в английской литературе этот процесс называется «part-of-speech tagging» (POST)) – это ручной или автоматический процесс, в результате которого каждому слову текста приписывает атрибутивная информация (тэг), которая определяет какой частью речи является это слово: существительное, глагол, прилагательное, наречие, местоимение, частица, союз, междометие и т.д. Именно тут мы и наткнёмся на проблему «стали».
Вначале немного о разметке теста (в английской литературе этот процесс называется «part-of-speech tagging» (POST)) – это ручной или автоматический процесс, в результате которого каждому слову текста приписывает атрибутивная информация (тэг), которая определяет какой частью речи является это слово: существительное, глагол, прилагательное, наречие, местоимение, частица, союз, междометие и т.д. Именно тут мы и наткнёмся на проблему «стали».
Революционное богатство. Тоффлер
2 мин
Элвин Тоффлер — американский социолог и футуролог, один из авторов концепции «сверхиндустриальной цивилизации». В его основных работах проводится тезис о том, что человечество переходит к новой технологической революции, то есть на смену первой волне (аграрной цивилизации) и второй (индустриальной цивилизации) приходит новая, ведущая к созданию (сверхиндустриальной) информационной цивилизации.
Тоффлер предупреждает о новых сложностях, социальных конфликтах и глобальных проблемах, с которыми столкнётся человечество на стыке XX и XXI вв. Подробнее об авторе.
В книге «Революционное богатство» показан наш 21 век, в котором уже во всю идет переход в информационную эпоху. Рассматриваются США, Европа, Китай, Япония, Индия мельком Россия.

В книге приводится аналогия трассы, по которой несутся автомобили: от машин под 100 миль в час до ползущих 10, 5 миль в час. Первые это современный бизнес и частные организации, последние — образование, государственные учреждения и политика. Все это на примере США.
В дальнейшем каждая из тем детально раскрывается. Рассматривается переход от массовости к индивидуальному. Десинхронизация современного бизнеса и государства.
Коренное изменение образования. Переход от школ, которые создавались для индустриальной волны, готовившие рабочих для фабрик, к индивидуальному образованию.
Тоффлер предупреждает о новых сложностях, социальных конфликтах и глобальных проблемах, с которыми столкнётся человечество на стыке XX и XXI вв. Подробнее об авторе.
В книге «Революционное богатство» показан наш 21 век, в котором уже во всю идет переход в информационную эпоху. Рассматриваются США, Европа, Китай, Япония, Индия мельком Россия.
В книге приводится аналогия трассы, по которой несутся автомобили: от машин под 100 миль в час до ползущих 10, 5 миль в час. Первые это современный бизнес и частные организации, последние — образование, государственные учреждения и политика. Все это на примере США.
В дальнейшем каждая из тем детально раскрывается. Рассматривается переход от массовости к индивидуальному. Десинхронизация современного бизнеса и государства.
Коренное изменение образования. Переход от школ, которые создавались для индустриальной волны, готовившие рабочих для фабрик, к индивидуальному образованию.
Adobe Profiler Fail
3 мин
Доброго вечера всем хабравчанам. Я долго думал как назвать данный пост и решил назвать первым, что придет на ум. В принципе данное название почти полностью описывает то, о чем хочу рассказать. А расскажу я о том, как можно легко и просто вносить изменения в абсолютно любой просматриваемый вами swf файл без декомпиляции.
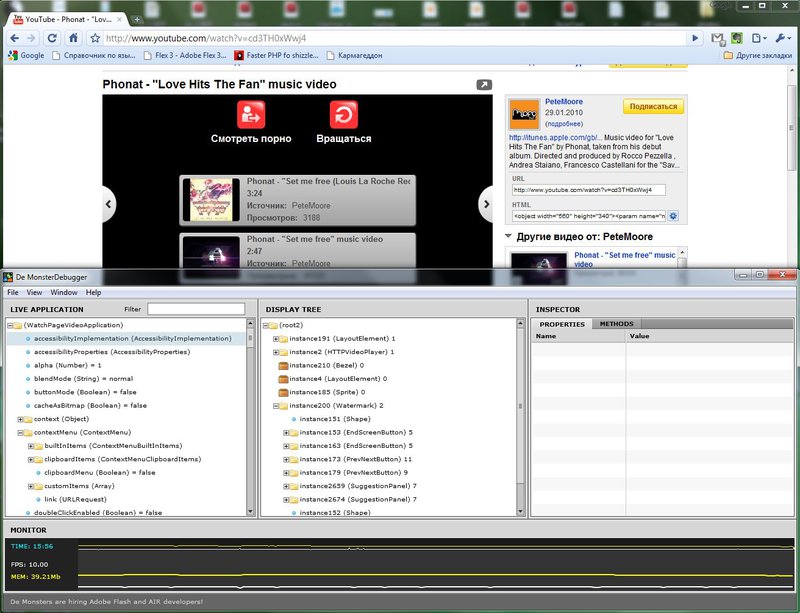
И так начнем. Нашим подопытным будет плеер YouTube.
И так начнем. Нашим подопытным будет плеер YouTube.
Заметки об NLP (часть 4)
5 мин
(Начало: 1, 2, 3) На сей раз хочу немного отвлечься и порассуждать (а точнее, похоливарить) на тему статистических алгоритмов и вообще «обходных путей» компьютерной лингвистики.
В первых частях нашего разговора речь шла о «классическом пути» анализа текста — от слов к предложениям, от предложений к связному тексту. Но в наше безумное время появились и соблазны решить проблему «одним махом», найдя, если угодно, баг в системе или «царскую дорогу».
В первых частях нашего разговора речь шла о «классическом пути» анализа текста — от слов к предложениям, от предложений к связному тексту. Но в наше безумное время появились и соблазны решить проблему «одним махом», найдя, если угодно, баг в системе или «царскую дорогу».
Появилась возможность совместного использования сборок .Net 4 и Silverlight 4
2 мин


Сегодня многие разработчики пишут код, который должен выполняться как Silverlight так и .Net Runtime’мами. Хорошим примером является проверка данных, когда вы проверяете их сначала на стороне клиента используя Silverlight, а затем на стороне сервера используя .Net. До недавних пор нужно было компилировать один и тот же код в сборки для разных runtime’мов(Silverlight и .Net). Эта модель работоспособна, но не идеальна!
Разделение Subversion репозитория на части
3 мин
Когда я узнал в первые про систему контроля версий, я решил, что обязательно надо попробовать этот инструмент для разработки. В то время я себе мало представлял что это такое. Поэтому просмотрев доступные предложения выбрал Subversion.
Почитав немного мануалы решил создать свой первый репозиторий. И вдруг я на минуту задумался, а как организовать структуру, если у меня будет несколько проектов… и для себя решил, что создам дерево, которое разделяется на проекты, а в каждом проекте будут всем до боли знакомые trunk, tags, branches. Шло время кол-во проектов увеличивалось (правда не особо много, но все же) и как-то грустно стало наблюдать сквозную нумерацию ревизий в проекте. Т.е. смотришь логи проекта, а там сначала 649 ревизия, а потом 700. Все таки программисты народ чистолюбивый, любит когда все разложено по полочкам, поэтому было решено разделить один большой репозиторий на несколько более мелких.
Почитав немного мануалы решил создать свой первый репозиторий. И вдруг я на минуту задумался, а как организовать структуру, если у меня будет несколько проектов… и для себя решил, что создам дерево, которое разделяется на проекты, а в каждом проекте будут всем до боли знакомые trunk, tags, branches. Шло время кол-во проектов увеличивалось (правда не особо много, но все же) и как-то грустно стало наблюдать сквозную нумерацию ревизий в проекте. Т.е. смотришь логи проекта, а там сначала 649 ревизия, а потом 700. Все таки программисты народ чистолюбивый, любит когда все разложено по полочкам, поэтому было решено разделить один большой репозиторий на несколько более мелких.
50 цитат о программировании всех времён
6 мин
Перевод
Перевёл после прочтения комментариев к статье «О ненависти к C++». В цитатах можно найти ответы на большинство возникших там вопросов.
50. Программирование сегодня — это гонка разработчиков программ, стремящихся писать программы больше и с лучшей идиотоустойчивостью, и вселенной, которая пытается создавать больших и лучших идиотов. Пока вселенная побеждает.
— Rick Cook
49. Lisp — это не язык, а строительный материал.
— Alan Kay
48. Ходить по воде и разрабатывать программы, следуя спецификации, очень просто… если они заморожены.
— Edward V Berard
50. Программирование сегодня — это гонка разработчиков программ, стремящихся писать программы больше и с лучшей идиотоустойчивостью, и вселенной, которая пытается создавать больших и лучших идиотов. Пока вселенная побеждает.
— Rick Cook
49. Lisp — это не язык, а строительный материал.
— Alan Kay
48. Ходить по воде и разрабатывать программы, следуя спецификации, очень просто… если они заморожены.
— Edward V Berard
Continuous Delivery в Яндексе. Как разогнать свой цикл разработки, используя только Open Source решения
8 мин
Перед тестированием всегда стояли и стоят две задачи – помочь команде поддерживать высокий уровень качества разработки и делать это, не задерживая весь процесс. И это справедливо не только для наших проектов в Яндексе, где мы работаем над очень большим количеством сервисов. Часто основная задача и вовсе формулируется как увеличение скорости тестирования при сохранении должного уровня качества. Скорость процесса разработки, приверженность ценностям частых и быстрых релизов – это основополагающие факторы для успеха любого продукта. У команды больше возможностей маневра, команда быстрее находит и исправляет ошибки, быстрее получает фидбек. Как же ускоряться, не теряя качества, как достичь дзена непрерывной доставки изменений?

Сегодня мы покажем, что Continuous Delivery — это просто и весело! А пользу от него можно получить, встроив его даже частично. Мы в тестировании Яндекса уже несколько лет используем подобный подход для наших библиотек с открытым исходным кодом — Allure Framework или Yandex QATools. Процесс прост, значительно масштабируем и может применяться как для огромных команд из одного человека, так и для маленьких командочек из десятков человек. А самое главное — весь инструментарий доступен в Open Source!
Кстати, до 30 сентября можно подать заявку и поступить в нашу Школу автоматизации процессов разработки в Питере. Обучение в ней бесплатное и будет состоять не только из курса лекций — обязательным этапом станет командная работа над учебным проектом.
А теперь вернёмся к теме. Представьте картину: уютное рабочее место, вы пишете код, добавляете юнит-тесты и отправляете изменения в систему контроля версий, а через пару часов они «выезжают» на боевые сервера. И все при этом работает.
Сегодня мы покажем, что Continuous Delivery — это просто и весело! А пользу от него можно получить, встроив его даже частично. Мы в тестировании Яндекса уже несколько лет используем подобный подход для наших библиотек с открытым исходным кодом — Allure Framework или Yandex QATools. Процесс прост, значительно масштабируем и может применяться как для огромных команд из одного человека, так и для маленьких командочек из десятков человек. А самое главное — весь инструментарий доступен в Open Source!
Кстати, до 30 сентября можно подать заявку и поступить в нашу Школу автоматизации процессов разработки в Питере. Обучение в ней бесплатное и будет состоять не только из курса лекций — обязательным этапом станет командная работа над учебным проектом.
А теперь вернёмся к теме. Представьте картину: уютное рабочее место, вы пишете код, добавляете юнит-тесты и отправляете изменения в систему контроля версий, а через пару часов они «выезжают» на боевые сервера. И все при этом работает.
Свободная литература или сказ про дружбу CoolReader c Tor
5 мин

Живет у меня в доме соседка: очень хорошая женщина, пенсионерка, ветеран труда, бывший медицинский работник, отработавший всю жизнь медсестрой в больнице. В настоящее время на пенсии. Я ей помогаю, чем могу, но сказ не про соседку, а про то, что подарила ей дирекция больницы, где она раньше работала планшет. Все бы ничего в этом планшете (WIFI есть, 3G нету, диагональ экрана 7 дюймов, на алиэкспрессе такие по 45 долларов с доставкой), но вот что делать с этим планшетом, естественно, не объяснили. И пришлось мне отвечать на вопрос, что делаю со своим планшетом я, а я на планшете книжки читаю, в основном Ясинского и Эльтерруса.
Естественно я подключил планшет к своему ноутбуку и перекинул апкашку CoolReader, а также свою библиотеку. К сожалению, через два дня выяснилось, что литературные пристрастия у нас разные и мои книжки соседке неинтересны. Пришлось поделиться паролем от своего вайфая и настроить opds «Флибусты», так как что такое Интернет соседка знала весьма приблизительно и ни компьютера, ни интернет-соединения у нее нет и никогда не было.
После выходных меня огорошили тем фактом, что нужные книжки с Флибусты не скачиваются. Сказать, что я был в недоумении — ничего не сказать — вся интересующая меня литература всегда была в свободном доступе, но соседка хотела Дарью Донцову и «50 оттенков серого» и, к моему удивлению, они действительно не скачивались.
Автоматическое определение рубрики текста
5 мин
Введение
В предыдущих статьях, посвященных организации данных в виде рубрикатора (Использование графа, как основы для создания рубрикатора и Проблемы, подстерегающие любого создателя рубрикаторов) были описаны общие идеи по организации рубрикатора. В этой статье я опишу один из возможных алгоритмов автоматического определения тематики текста на основе заранее подготовленного графа-рубрикатора. При этом я сознательно избегаю сложных формул, чтобы донести идею, лежащую в основе алгоритма, максимально просто.
Подготовка данных рубрикатора
Для начала определимся с тем, в каком виде мы будем готовить данные для рубрикатора.
- 1. Рубрикатор – это граф, а не дерево
- 2. Текст, тематика которого определяется, может быть отнесен к нескольким рубрикам одновременно
- 3. Для каждого соотнесения с рубрикой указывается коэффициент точности определения рубрики
- 4. Тематика текста определяется для каждого текста отдельно, и не зависит от того как были определены рубрики других текстов ранее
Последний пункт нуждается в небольшом пояснении. Независимость определения тематики текста очень хороша, когда не требуется последующая сортировка результатов. Когда тексты просто отнесены к рубрики или нет. Но при наличии в рубрике нескольких текстов, наверняка возникнет необходимость отсортировать их по критерию наилучшего попадания в рубрику. В данной статье этот вопрос опущен для ясности.
Алгоритм определения тематики текста, кратко
Описываем рубрикатор. Извлекаем из исследуемого текста ключевые слова, описанные в рубрикаторе. В результате извлечения получаем кусочки разорванного и чаще всего несвязного графа. Используем волновой (или любой другой, по желанию) алгоритм для «дотягивания» извлеченных кусочков графа до вершины «всё». Анализируем и выводим результаты.