

Качество печатной платы зависит не только от оборудования, уровня технологов и процессов на фабрике. Не меньший вклад в него вносят конструкторские решения разработчика платы — тополога. От них зависит технологичность: то, насколько просто будет произвести и ремонтировать изделие. Наиболее технологичной плата получится, если тополог сразу учтёт технологические нормы и особенности производства, внеся их в параметры своего CAD‑проекта. Такой подход называется Design for Manufacturing (DFM) — дизайн, оптимизированный под производство. Давайте разбираться, что это такое.
Этот материал адресован в первую очередь топологам, технологам и всем, кто уже работает в RnD и на производствах — или готовится войти в индустрию. Но мы постарались сделать его доступным для всех читателей.




 Микроконтроллер ARM Cortex M3 STM32F103c8t6 широко распространен как 32-х битный микроконтроллер для любительских проектов. Как для практически любого микроконтроллера, для него существует SDK, включающая, в том числе и заголовочные файлы C++ определения периферии контроллера.
Микроконтроллер ARM Cortex M3 STM32F103c8t6 широко распространен как 32-х битный микроконтроллер для любительских проектов. Как для практически любого микроконтроллера, для него существует SDK, включающая, в том числе и заголовочные файлы C++ определения периферии контроллера.

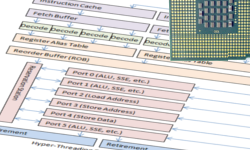 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.