Большая часть времени исполнения программы приходится на циклы: это могут быть вычисления, прием и обработка информации и т.д. Правильное применение техник оптимизации циклов позволит увеличить скорость работы программы. Но прежде, чем приступать к оптимизациям необходимо выделить «узкие» места программы и попытаться найти причины падения быстродействия.

Андрей Хайрутдинов @Grab
Пользователь
Теория Игр и функция Шпрага-Гранди
6 min
Доброго времени суток, уважаемое Хабрасообщество.
В последнее время все большее и большее распространение получает олимпиадное программирование, неотъемлемой частью которого является знание алгоритмов (и, разумеется, умение их применять).
Я хочу рассказать вам основы теории Игр, доказать функцию Шпрага-Гранди, разобрать несколько классических impartial-задач и проиллюстрировать их кодом на python.
В последнее время все большее и большее распространение получает олимпиадное программирование, неотъемлемой частью которого является знание алгоритмов (и, разумеется, умение их применять).
Я хочу рассказать вам основы теории Игр, доказать функцию Шпрага-Гранди, разобрать несколько классических impartial-задач и проиллюстрировать их кодом на python.
Реализация нечеткого поиска
6 min
Если ваш веб проект так или иначе будет связан с поиском и предоставлением пользователям некоторых данных, то перед вами наверняка встанет задача реализации строки поиска. При этом, если в проекте по какой-либо причине не удастся использовать технологии умных сервисов как Google или Яндекс, то поиск частично или полностью придется реализовать самостоятельно. Одной из подзадач наверняка будет реализация нечеткого поиска, ведь пользователи часто ошибаются и иногда не знают точных терминов, названий или имен.
В данной статье описывается возможная реализация нечеткого поиска, которая была применена для поиска на сайте edatuda.ru.
Счастливый ProductOwner — верхом на пороховой бочке
8 min
Вы — руководитель проектов и вам поручили создать сложный интернет-магазин с извращенным биллингом за 4 месяца. Вам хочется работать в этой компании ближайшие 2-3 года — платят хорошо, проекты громкие. Топы верят в вас. На кону ваша профессиональная репутация.
Разберем, какой оседлать собственное подразделение разработки и добиться успеха.
Разберем, какой оседлать собственное подразделение разработки и добиться успеха.
Корпоративный троллинг — 3, или сдача работ без лишних забот
11 min
В предыдущих статьях (первая, вторая) мы бегло и в шутливой форме прошлись по примерам противодействия, которое оказывают нам сотрудники заказчика на различных этапах проекта. Сегодня предметом рассмотрения будет сдача работ, и мы подойдем к этому этапу во всеоружии, чтобы ни один тролль не прорвался. Получилось много букв, но, надеюсь оно того стоит.
Сдача результатов работы является одним из самых драматических этапов проекта. Человеко-месяцы, потраченные на разработку, отладку, тестирование и внедрение вашего решения, не должны быть потрачены зря. Если сдача работ поручена вам, то ваша роль в команде весьма значительна, а доверие руководства велико, даже если начальники вам этого никогда не говорили. Облажаться на сдаче работ иногда означает конец вашей блистательной карьеры. Так что лучше этого не делать.
Процесс приемо-сдаточных испытаний должен быть строго формализован. Всем понятно, что в конце этого процесса должен появиться протокол и акт, на основании которого выпускается приказ о переводе системы в опытную или промышленную эксплуатацию. Акт также является формальным поводом для выставления счета на оплату очередного этапа проекта.
В этой статье я без лишних шуток (какие уж тут шутки!) и максимально последовательно (ну, для блога, конечно) опишу процесс сдачи проектных работ. Разумеется, многие вещи опытным коллегам покажутся очевидными. Пусть. Зато менее опытные коллеги или желающие примерить ответственную роль сдающего на себя найдут эту публикацию полезной и познавательной.
Сдача результатов работы является одним из самых драматических этапов проекта. Человеко-месяцы, потраченные на разработку, отладку, тестирование и внедрение вашего решения, не должны быть потрачены зря. Если сдача работ поручена вам, то ваша роль в команде весьма значительна, а доверие руководства велико, даже если начальники вам этого никогда не говорили. Облажаться на сдаче работ иногда означает конец вашей блистательной карьеры. Так что лучше этого не делать.
Процесс приемо-сдаточных испытаний должен быть строго формализован. Всем понятно, что в конце этого процесса должен появиться протокол и акт, на основании которого выпускается приказ о переводе системы в опытную или промышленную эксплуатацию. Акт также является формальным поводом для выставления счета на оплату очередного этапа проекта.
В этой статье я без лишних шуток (какие уж тут шутки!) и максимально последовательно (ну, для блога, конечно) опишу процесс сдачи проектных работ. Разумеется, многие вещи опытным коллегам покажутся очевидными. Пусть. Зато менее опытные коллеги или желающие примерить ответственную роль сдающего на себя найдут эту публикацию полезной и познавательной.
Корпоративный троллинг. Часть вторая
6 min
Сегодня мы разберем разновидности противодействия, которые встречаются при очных мероприятиях — на презентациях и переговорах. Конечно, трудно охватить одним махом обширнейшую сферу черной риторики, черного пиара и прочей черной мерзости, которая сопровождает любое наше даже самое благое начинание. Но хабралюди народ опытный, информацию искать обученный. Как говорится, хороший инженер не обязан все знать, но он должен уметь быстро добывать необходимые знания. Сам я не являюсь гуру ни в переговорах, ни в риторике, но имел опыт общения с настоящими мастерами своего дела, которые в Хабр писать никогда не станут, даже если знают о существовании этого ресурса. Мне кажется, что этот опыт, обобщенный и очищенный от эмоций, будет многим интересен.
Groovy за 15 минут – краткий обзор
8 min
Groovy — объектно-ориентированный язык программирования разработанный для платформы Java как альтернатива языку Java с возможностями Python, Ruby и Smalltalk.
Groovy использует Java-подобный синтаксис с динамической компиляцией в JVM байт-код и напрямую работает с другим Java кодом и библиотеками. Язык может использоваться в любом Java проекте или как скриптовый язык.
Возможности Groovy (отличающие его от Java):
— Статическая и динамическая типизация
— Встроенный синтаксис для списков, ассоциативных массивов, массивов и регулярных выражений
— Замыкания
— Перегрузка операций
[http://ru.wikipedia.org/wiki/Groovy]
Более того, почти всегда java-код — это валидный groovy-код.
Groovy использует Java-подобный синтаксис с динамической компиляцией в JVM байт-код и напрямую работает с другим Java кодом и библиотеками. Язык может использоваться в любом Java проекте или как скриптовый язык.
Возможности Groovy (отличающие его от Java):
— Статическая и динамическая типизация
— Встроенный синтаксис для списков, ассоциативных массивов, массивов и регулярных выражений
— Замыкания
— Перегрузка операций
[http://ru.wikipedia.org/wiki/Groovy]
Более того, почти всегда java-код — это валидный groovy-код.
Таблицы Юнга в задачах поиска и сортировки
6 min
Таблицы Юнга являются широко известным (в узких кругах) типом объектов, изучаемых в комбинаторике и смежных науках: ссылка, ссылка, книжка. Ниже рассматривается применение частного вида таблиц Юнга применительно к таким стандартным алгоритмическим задачам, как поиск и сортировка. С этой точки зрения таблицы Юнга весьма близки пирамидам, собственно так они и позиционируются в учебнике Кормена и ко (упражнения в разделе, посвященном пирамидам).
Синдром рефакторинга
5 min

Бытует мнение, что программные системы, будучи объектом не совсем материальным, не поддаются старению. И если говорить о старении физическом, то действительно, шансы на то, что буковка “o” в имени класса вдруг от старости ссохнется и превратится в букву “c” – действительно малы. Но вместо старения физического, программные системы стареют морально. Со временем накапливается груз ошибок за счет неточностей в исходных требованиях, непонимания требований самим заказчиком, архитектурных ошибок или неудачных компромиссных решений; да и ошибки поменьше, типа слабопонятного кода, его высокой связности, отсутствия юнит-тестов и комментариев делают свое черное дело. Все это приводит к накоплению технического долга (о котором шла речь в прошлый раз), из-за которого при добавлении новой возможности в систему приходиться платить «проценты» в виде более высокой стоимости реализации и более низкого качества получаемого результата.
CUDA: аспекты производительности при решении типичных задач
7 min
 Перед тем как начать переносить реализацию вычислительного алгоритма на видеокарту стоит задуматься — получим ли мы желаемый прирост производительности или только потеряем время. И несмотря на обещания производителей о сотнях GFLOPS, у современного поколения карт есть свои проблемы, о которых лучше знать заранее. Я не буду глубоко уходить в теорию и рассмотрю несколько существенных практических моментов и сформулирую некоторые полезные выводы.
Перед тем как начать переносить реализацию вычислительного алгоритма на видеокарту стоит задуматься — получим ли мы желаемый прирост производительности или только потеряем время. И несмотря на обещания производителей о сотнях GFLOPS, у современного поколения карт есть свои проблемы, о которых лучше знать заранее. Я не буду глубоко уходить в теорию и рассмотрю несколько существенных практических моментов и сформулирую некоторые полезные выводы.Высокопроизводительные вычисления: проблемы и решения
12 min
Компьютеры, даже персональные, становятся все сложнее. Не так уж давно в гудящем на столе ящике все было просто — чем больше частота, тем больше производительность. Теперь же системы стали многоядерными, многопроцессорными, в них появились специализированные ускорители, компьютеры все чаще объединяются в кластеры.
Зачем? Как во всем этом многообразии разобраться?
Что значит SIMD, SMP, GPGPU и другие страшные слова, которые встречаются все чаще?
Каковы границы применимости существующих технологий повышения производительности?
Компьютерные мощности быстро растут и все время кажется, что все, существующей скорости хватит на все.
Но нет — растущая производительность позволяет решать проблемы, к которым раньше нельзя было подступиться. Даже на бытовом уровне есть задачи, которые загрузят ваш компьютер надолго, например кодирование домашнего видео. В промышленности и науке таких задач еще больше: огромные базы данных, молекулярно-динамические расчеты, моделирование сложных механизмов — автомобилей, реактивных двигателей, все это требует возрастающей мощности вычислений.
В предыдущие годы основной рост производительности обеспечивался достаточно просто, с помощью уменьшения размеров элементов микропроцессоров. При этом падало энергопотребление и росли частоты работы, компьютеры становились все быстрее, сохраняя, в общих чертах, свою архитектуру. Менялся техпроцесс производства микросхем и мегагерцы вырастали в гигагерцы, радуя пользователей возросшей производительностью, ведь если «мега» это миллион, то «гига» это уже миллиард операций в секунду.
Но, как известно, рай бывает либо не навсегда, либо не для всех, и не так давно он в компьютерном мире закончился. Оказалось, частоту дальше повышать нельзя — растут токи утечки, процессоры перегреваются и обойти это не получается. Можно, конечно, развивать системы охлаждения, применять водные радиаторы или совсем уж жидким азотом охлаждать — но это не для каждого пользователя доступно, только для суперкомпьютеров или техноманьяков. Да и при любом охлаждении возможность роста была небольшой, где-то раза в два максимум, что для пользователей, привыкших к геометрической прогрессии, было неприемлемо.
Казалось, что закон Мура, по которому число транзисторов и связанная с ним производительность компьютеров удваивалась каждые полтора-два года, перестанет действовать.
Пришло время думать и экспериментировать, вспоминая все возможные способы увеличения скорости вычислений.
Зачем? Как во всем этом многообразии разобраться?
Что значит SIMD, SMP, GPGPU и другие страшные слова, которые встречаются все чаще?
Каковы границы применимости существующих технологий повышения производительности?
Введение
Откуда такие сложности?
Компьютерные мощности быстро растут и все время кажется, что все, существующей скорости хватит на все.
Но нет — растущая производительность позволяет решать проблемы, к которым раньше нельзя было подступиться. Даже на бытовом уровне есть задачи, которые загрузят ваш компьютер надолго, например кодирование домашнего видео. В промышленности и науке таких задач еще больше: огромные базы данных, молекулярно-динамические расчеты, моделирование сложных механизмов — автомобилей, реактивных двигателей, все это требует возрастающей мощности вычислений.
В предыдущие годы основной рост производительности обеспечивался достаточно просто, с помощью уменьшения размеров элементов микропроцессоров. При этом падало энергопотребление и росли частоты работы, компьютеры становились все быстрее, сохраняя, в общих чертах, свою архитектуру. Менялся техпроцесс производства микросхем и мегагерцы вырастали в гигагерцы, радуя пользователей возросшей производительностью, ведь если «мега» это миллион, то «гига» это уже миллиард операций в секунду.
Но, как известно, рай бывает либо не навсегда, либо не для всех, и не так давно он в компьютерном мире закончился. Оказалось, частоту дальше повышать нельзя — растут токи утечки, процессоры перегреваются и обойти это не получается. Можно, конечно, развивать системы охлаждения, применять водные радиаторы или совсем уж жидким азотом охлаждать — но это не для каждого пользователя доступно, только для суперкомпьютеров или техноманьяков. Да и при любом охлаждении возможность роста была небольшой, где-то раза в два максимум, что для пользователей, привыкших к геометрической прогрессии, было неприемлемо.
Казалось, что закон Мура, по которому число транзисторов и связанная с ним производительность компьютеров удваивалась каждые полтора-два года, перестанет действовать.
Пришло время думать и экспериментировать, вспоминая все возможные способы увеличения скорости вычислений.
Оптимизация PNG и JPEG без потери качества. Часть 1
9 min
Введение
Предлагаю Вашему вниманию обзор посвященный оптимизации изображений формата PNG и JPEG без потери качества. Под «без потери качества» подразумевается, что визуально оригинальные и оптимизированные изображения ни чем не будут отличаться. Я читал на Хабре довольно много статьей посвященных данному вопросу, но скажу, большая часть — полная чушь, в них констатируются факты, а не причины. Данный обзор посвящен людям, которые имеют базовые знания об оптимизации изображений.
Настройка репозитория Sonatype Nexus для проксирования артефактов Maven
6 min
Добрый день!
Про утилиту сборки для Java-проектов Maven и про возможность создания локального сервера для Maven-репозитория с помощью Sonatype Nexus на Хабре уже упоминали (тут и тут). Однако, никакого рецепта по этому поводу представлено не было. Это неудивительно при наличии достаточно полной грамотной документации. По долгу службы мне пришлось настраивать его на нашей фирме, и оказалось, что советы из официальной документации не совсем подходят. Возникшей проблемой и способом ее решения я и хочу поделиться с сообществом. Но обо всем по порядку.
Локальный сервер для Maven-репозитория (как, например, Sonatype Nexus) может быть использован для хранения локальных артефактов Maven, и действительно пригодится командам, которые разрабатывают модульные приложения, но не собираются публиковать модули в общий доступ.
Кроме того, такой сервер может работать и для локального хранения удаленных артефактов Maven, что значительно сокращает время загрузки удаленных артефактов всеми членами команды и предохраняет от недоступности внешних репозиториев. Именно о таком использовании и пойдет речь дальше.
Про утилиту сборки для Java-проектов Maven и про возможность создания локального сервера для Maven-репозитория с помощью Sonatype Nexus на Хабре уже упоминали (тут и тут). Однако, никакого рецепта по этому поводу представлено не было. Это неудивительно при наличии достаточно полной грамотной документации. По долгу службы мне пришлось настраивать его на нашей фирме, и оказалось, что советы из официальной документации не совсем подходят. Возникшей проблемой и способом ее решения я и хочу поделиться с сообществом. Но обо всем по порядку.
Зачем это нужно?
Локальный сервер для Maven-репозитория (как, например, Sonatype Nexus) может быть использован для хранения локальных артефактов Maven, и действительно пригодится командам, которые разрабатывают модульные приложения, но не собираются публиковать модули в общий доступ.
Кроме того, такой сервер может работать и для локального хранения удаленных артефактов Maven, что значительно сокращает время загрузки удаленных артефактов всеми членами команды и предохраняет от недоступности внешних репозиториев. Именно о таком использовании и пойдет речь дальше.
Улучшаем интерфейс Java-приложения
27 min
Tutorial
 Добрый день, Хабражитель!
Добрый день, Хабражитель!Достаточно много различной раздробленной информации существует на тему работы со Swing и графикой в просторах интернета, а также на тему интерфейсов Java-приложений. Кто-то твердит о том, что Java морально устарела и десктоп-приложения на Java не имеет смысла писать, кто-то с пеной у рта доказывает обратное. В то же время работа идет, приложения пишутся и встают очередные проблемы. В предыдущей статье я уже привел небольшой список полезных библиотек для исключительных случаев, но нередко бывает так, что никакая сторонняя библиотека не позволяет сделать то, что Вам нужно. Именно в такой момент стоит задуматься о возможной необходимости написания своих компонентов.
Итак, в данном посте я постарался изложить самые важные и значимые на мой взгляд моменты по работе со Swing и графикой — как создавать компоненты, как стилизовать интерфейс, чего делать не стоит и многое другое…
Особенности зарубежной типографики
5 min
Несколько месяцев назад я столкнулся с задачей верстки буклета на французском языке. Оказалось, что в рунете тема зарубежной типографики представлена крайне скупо, поэтому необходимую информацию пришлось находить и переводить самостоятельно.
В данной статье я хотел бы рассказать о наиболее примечательных, на мой взгляд, европейских типографических традициях, их сходствах и различиях.

В данной статье я хотел бы рассказать о наиболее примечательных, на мой взгляд, европейских типографических традициях, их сходствах и различиях.
Вычисление редакционного расстояния
5 min
Редакционное расстояние, или расстояние Левенштейна — метрика, позволяющая определить «схожесть» двух строк — минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую. В статье излагается метод вычисления редакционного расстояния при использовании небольшого объема памяти, без существенной потери скорости. Данный подход может быть применен для больших строк (порядка 105 символов, т.е. фактически для текстов) при получении не только оценки «схожести», но и последовательности изменений для перевода одной строки в другую.
Визуализация графов. Метод связывания ребер
7 min
Иногда полезно представить граф в графической форме, так чтобы была видна структура. Можно привести десятки примеров, где это может пригодиться: визуализация иерархии классов и пакетов исходного кода какой-нибудь программы, визуализация социального графа (тот же Twitter или Facebook) или графа цитирования (какие публикации на кого ссылаются) и т.д. Но вот незадача: количество ребер в графе зачастую настолько велико, что нарисованный граф просто невозможно разобрать. Взгляните на эту картинку:
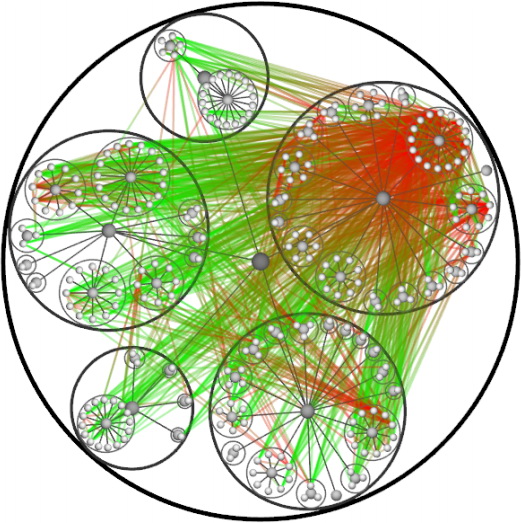
Это граф зависимостей некой программной системы. Он представляет собой дерево разбиения на пакеты (серые шарики — пакеты, белые — классы), на которое поверх наложены ребра зависимости одних классов от других. Чтобы не рисовать стрелки направления, ребра нарисованы в виде градиентных линий, где зеленый — это начало, а красный — конец ребра. Как видите, граф настолько визуально перегружен, что архитектуру программы невозможно проследить.
Под катом описание метода, решающего эту проблему.
Это граф зависимостей некой программной системы. Он представляет собой дерево разбиения на пакеты (серые шарики — пакеты, белые — классы), на которое поверх наложены ребра зависимости одних классов от других. Чтобы не рисовать стрелки направления, ребра нарисованы в виде градиентных линий, где зеленый — это начало, а красный — конец ребра. Как видите, граф настолько визуально перегружен, что архитектуру программы невозможно проследить.
Под катом описание метода, решающего эту проблему.
Задача нахождения максимума на отрезках фиксированной длины
3 min
Постановка задачи
Пусть дан массив A длины N, и дано число K ≤ N. Требуется найти максимум (минимум, сумма ...) в подотрезках длины K данного массива. Это частный случай задачи RMQ (Range Minimum Query — минимум на отрезке), но с дополнительными ограничениями — постоянная длина отрезка поиска. В данном решении задача не предполагает возможность изменения элементов массива.
Суффиксный массив — удобная замена суффиксного дерева
14 min
Здравствуйте, уважаемое сообщество! Думаю, многим знакома такая структура данных как суффиксное дерево. На Хабре уже было описание как его построить и зачем. Если вкратце, то оно нужно тогда, когда надо много раз искать какие-то произвольные образцы Xi в заранее заданном тексте A, а строится такое дерево мучительно с помощью алгоритма Укконена (есть и другие варианты, но они предполагают еще большее количество страданий). Общее наблюдение при работе с алгоритмами таково, что деревья — это, конечно, хорошо, но на практике их лучше избегать из за серьезных оверхэдов по памяти и не очень оптимального (с точки зрения эффективности оперирования данными компьютером) расположения. Кроме того, именно в таком дереве есть еще более существенная неприятность, а именно алфавитнозависимость структуры. Для решения этих проблем был придуман суффиксный массив. О том как его строить и как использовать и пойдет в этой статье.
Материал статьи предполагает знание понятий суффикса и префикса строки, а также знание того, как работает бинарный поиск. Надо также представлять, что такое стабильная сортировка и поразрядная сортировка, а также понимание, что имеется ввиду под стабильной сортировкой подсчетом. Для некоторых частей нам понадобится знание задачи о минимуме на отрезке — Range Minimum Query (RMQ). Ну, в общем, вас предупредили: никто не говорил, что будет просто.
Материал статьи предполагает знание понятий суффикса и префикса строки, а также знание того, как работает бинарный поиск. Надо также представлять, что такое стабильная сортировка и поразрядная сортировка, а также понимание, что имеется ввиду под стабильной сортировкой подсчетом. Для некоторых частей нам понадобится знание задачи о минимуме на отрезке — Range Minimum Query (RMQ). Ну, в общем, вас предупредили: никто не говорил, что будет просто.
Стеганографический метод Куттера-Джордана-Боссена
2 min
Решил продолжить цикл статей по стеганографии, на хабре уже был рассмотрен примитивный алгоритм LSB. Решил написать о методе Куттера-Джордана-Боссена (его также называют методом «креста»), который применяется для встраивания информации в изображения.