Привет. Меня зовут Денис Лисовик, я Backend-инженер в команде Data Science SWAT Авито. В этой статье рассказываю, как использовать разделяемую память в Aqueduct. Вместе мы шаг за шагом пройдем от сервиса, который едва держит один RPS, до сервиса, который может держать сотни запросов в секунду. В процессе вы узнаете, как использовать разделяемую память и как сделать так, чтобы она не утекала, а приложение не падало с Segmentation fault.
Всем привет! Меня зовут Денис Колпаков, я бэкенд-инженер в юните Core Services Авито. Долгое время я был овнером критически значимого для бизнеса сервиса форм, а последний год занимаюсь каталогами и каталогизацией.
Я расскажу, как мы решали продуктовую задачу — искали способ отфильтровать модификации товаров из базы данных.
Я занимаюсь разработкой и поддержкой сервиса уведомлений в Ostrovok.ru. Сервис написан на Python3 и Django. Помимо транзакционных писем, пушей и сообщений, сервис также берёт на себя задачи по массовым рассылкам коммерческих предложений (не спам! trust me, отписки у нас работают лучше подписок) пользователям, давшим на это согласие. Со временем база активных получателей разрослась до более миллиона адресов, к чему почтовый сервис не был готов. Я хочу рассказать о том, как новые возможности Python позволили ускорить массовые рассылки и сэкономить ресурсы и с какими проблемами нам пришлось столкнуться при работе с ними.
У нас уже есть одна статья про развитие типизации в Ostrovok.ru. В ней объясняется, зачем мы переходим с pyContracts на typeguard, почему переходим именно на typeguard и что в итоге получаем. А сегодня я расскажу подробнее о том, каким образом происходит этот переход.
Так сложилось, что уже пять лет мой раздел ntfs с операционной системой Windows располагается на рамдиске. Решено это не аппаратным, а чисто программным способом, доступным на любом ПК с достаточным количеством оперативной памяти: рамдиск создается средствами загрузчика grub4dos, а Windows распознаёт его при помощи драйвера firadisk.
Однако до недавнего времени мне не был известен способ, как реализовать подобное для Linux. Нет, безусловно, существует огромное количество линуксовых LiveCD, загружающихся в память при помощи опций ядра toram, copy2ram и т. д., однако это не совсем то. Во-первых, это сжатые файловые системы, обычно squashfs, поэтому любое чтение с них сопровождается накладными расходами на распаковку, что вредит производительности. Во-вторых, это достаточно сложная каскадная система монтирования (так как squashfs — рид-онли система, а для функционирования ОС нужна запись), а мне хотелось по возможности простого способа, которым можно «вот так взять и превратить» любой установленный на жесткий диск Linux в загружаемый целиком в RAM.
Ниже я опишу такой способ, который был с успехом опробован. Для опытов был взят самый заслуженный дистрибутив Linux — Debian.
Интересен тот факт, что SVM является всего лишь отдельным видом очень простой схемы (схемы, которая вычисляет score = a*x + b*y + c, где a,b,c являются весовыми функциями, а x,y представляют собой точки ввода данных). Его можно легко расширить до более сложных функций. Например, давайте запишем двухслойную нейронную сеть, которая выполняет бинарную классификацию. Проход вперед будет выглядеть следующим образом:
Часто вижу, как владельцы ноутбуков жалуются на шумы микрофона в Linux, в то время как под Windows их меньше, либо же они вообще отсутствуют. Как правило, виноват в этом производитель, установивший самый дешевый микрофон и/или кодек из возможных, надеясь на сглаживание отвратительного качества железа программными средствами.
К счастью, в Linux есть замечательный аудиосервер PulseAudio, с помощью которого можно сделать аудио с вашего микрофона заметно качественней.
Способ #1
Для того, чтобы использовать встроенный модуль подавления шума и эха PulseAudio, работающий по алгоритму webrtc или speex, для какой-то конкретной программы, достаточно запустить ее с переменной окружения:
PULSE_PROP="filter.want=echo-cancel"
И весь ваш звук магическим образом будет избавлен от шумов и эха!
Вне всяких сомнений, Pro Git — это одна из лучших книг про систему контроля версий git. Совсем недавно появилось второе издание этой замечательной книжки. Большие изменения произошли в издательском процессе: исходный код книги теперь хранится в AsciiDoc, а не в Markdown, а различные форматы (PDF, ePub и Mobi) автоматически генерируются с помощью O'Reilly Atlas platform. Разработка книги активно ведётся на гитхабе, актуальная online-версия находится в открытом доступе на официальном сайте, а любители печатной продукции могут заказать себе экземпляр на Amazon. Второе издание получилось почти в два раза больше первого: на сегодняшний день PDF-версия содержит 570 страниц. Помимо улучшения старого материала, книжка также пополнилась новыми главами и разделами:
В первой части мы описали свойства нейронов. Во второй говорили об основных свойствах, связанных с их обучением. Уже в следующей части мы перейдем к описанию того как работает реальный мозг. Но перед этим нам надо сделать последнее усилие и воспринять еще немного теории. Сейчас это скорее всего покажется не особо интересным. Пожалуй, я и сам бы заминусовал такой учебный пост. Но вся эта «азбука» сильно поможет нам разобраться в дальнейшем.
Персептрон
В машинном обучении разделяют два основных подхода: обучение с учителем и обучение без учителя. Описанные ранее методы выделения главных компонент – это обучение без учителя. Нейронная сеть не получает никаких пояснений к тому, что подается ей на вход. Она просто выделяет те статистические закономерности, что присутствуют во входном потоке данных. В отличие от этого обучение с учителем предполагает, что для части входных образов, называемых обучающей выборкой, нам известно, какой выходной результат мы хотим получить. Соответственно, задача – так настроить нейронную сеть, чтобы уловить закономерности, которые связывают входные и выходные данные.
Практически все бесполезные советы начинаются словами: «Если у вас есть что-то ненужное...» и дальше приводятся рекомендации как превратить это самое ненужное во что-либо полезное. В моем случае у меня имелось огромное желание иметь второй монитор. Из подручных материалов имелся только старый ноутбук Toshiba Satellite Pro 4200, который было очень жалко отдавать за те гроши, что за него предлагали. Оказалось, что монитор этого ноутбука можно с легкостью необычайной использовать как вторичный монитор используя сетевое соединение. Для моих целей (программирование, работа с текстами) качество этого монитора вполне подходит.
Всем привет, раз на хабре пошел цикл статей про нейронные сети, то и я напишу про возможность использования нейронных сетей в задаче прогнозирования финансовых временных рядов.
Существует несколько различных теорий о возможности прогнозирования фондовых рынков. Одна из них — гипотеза эффективного рынка, согласно ей, в цене акции уже учтена вся имеющиеся информация и делать прогнозы бессмысленно. Продолжением этой гипотезы можно назвать теорию случайных блужданий.
В теории случайных блужданий информация подразделяется на две категории — предсказуемую, известную и новую, неожиданную. Если предсказуемая, а тем более уже известная информация уже заложена в рыночные цены, то новая неожиданная информация в цене пока еще не присутствует. Одним из свойств непредсказуемой информации является ее случайность и, соответственно, случайность последующего изменения цены. Гипотеза эффективного рынка объясняет изменение цен поступлениями новой неожиданной информации, а теория случайных блужданий дополняет это мнением о случайности изменения цен.
К написанию этой статьи меня побудила большая распространенность некоторых заблуждений на тему искусственных нейронных сетей (ИНС), особенно в области представлений о том, что они могут и чего не могут, ну и хотелось бы знать, насколько вопросы ИНС вообще актуальны здесь, стоит ли что-либо обсудить подробнее.
Я хочу рассмотреть несколько известных архитектур ИНС, привести наиболее общие (в следствие чего не всегда абсолютно точные) сведения об их устройстве, описать их сильные и слабые стороны, а также обрисовать перспективы.
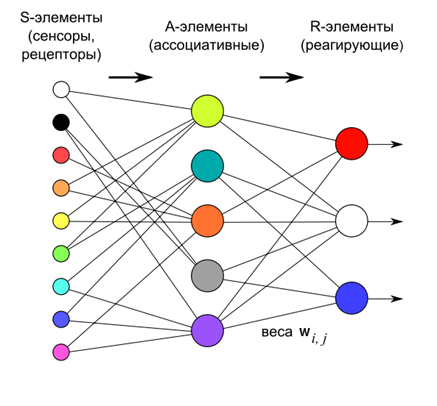
В настоящее время достаточно интересной областью программирования является использование нейронных сетей. Не смотря на всю перспективность этой идеи, большинство реализаций которые я встречал были связаны с различным анализом статистических выборок и предсказанием возможного значения какого-либо параметра.
Разговоры об искусственном интеллекте и громоздких экспертных системах — это конечно все хорошо, но как всю эту теорию приблизить к жизни, к нашим приклодным задачам?
Вопросы правильной расстановки дефисов, длинного и короткого тире, знака минуса, кавычек-елочек и кавычек-лапок уже неоднократно поднимались в интернете и на Хабре в частности (см. ссылки ниже). Однако по-прежнему, студенты и аспиранты в своих курсовых и дипломных, диссертациях и авторефератах не уделяют достаточного внимания типографике.
В данной заметке я привожу две таблицы с основными правилами расстановки указанных знаков и отбивок между ними при верстке текстов в системе LaTeX, в которой готовится значительная часть квалификационных работ по физико-математическим специальностям.
Со временем возможно появятся похожие таблички с правилами расстановки пробелов, знаков препинания и по оформлению текста в целом.
С каждым днем пользователи смартфонов занимают все большую долю интернета. По данным LiveInternet доля российских пользователей OS Android уже превысила долю Windows7. В выходные дни пользователи мобильных платформ пользуются интернетом значительно чаще. Та же тенденция наблюдается и в мире. Все это еще раз доказывает необходимость адаптации сайта для смартфонов и планшетов.
О том, как можно адаптировать ваш Django-проект для мобильных устройств, я расскажу в этой статье. Но сначала давайте разберем, какие есть варианты создания мобильной версии сайта.
Я думаю ни для кого не будет секретом, что у Awesome есть «узкое место», если мы запускаем внешний скрипт, который например должен считать данные из файла, или интернета и вернуть результат в виджет или саму систему, то мы периодически можем наблюдать явлениие «фриза», т.е. когда система перестает реагировать на нажатия клавиш и мыши до получения результата обработки (правда активный клиент при этом продолжает работать). Чаще всего это происходит при использовании io.popen или awful.util.pread
3 августа в сабреддите /r/Anarchism некто пользователь PhineasFisher создал тред, в котором сообщил о том, что ему удалось украсть 40 гигабайт различных данных компании Gamma International. Возможно, подобная история могла оказаться не столь громкой, если бы не бизнес, которым занимается эта европейская фирма — создание и продажа программных средств для взлома и скрытой слежки (а иными словами — самой настоящей малвари), заказчиками которых обычно выступали государственные структуры. Через несколько дней после первого сообщения взломщик выложил длинный рассказ о том, как ему удалось проникнуть на сервера Gamma International и что удалось там найти.
Сегодня открыли доступ к обучающим материалам курса «Введение в Linux».
Курс создан Linux Foundation и проходит на платформе edX.
О курсе:
Linux обеспечивает работу 94% суперкомпьютеров, большинства серверов в Интернете, основных финансовых сделок в мире и миллиардов Android устройств. Если коротко, то Linux везде. Он присутствует во множестве различных архитектур, от мэйнфреймов до серверов, настольных компьютеров, мобильных устройств и на ошеломляющем разнообразии железа.
Этот курс освещает различные инструменты и техники обычно используемые Linux программистами, системными администраторами и конечными пользователями для выполнения их ежедневной работы в среде Linux. Он создан для опытных пользователей компьютером, кто мало или вообще не использовал Linux, работают ли они индивидуально или в корпоративной среде.
После завершения этого курса вы будете хорошо знать как работать с основными дистрибутивами Linux в графической или командной оболочке. Вы сможете продолжить свое обучение как пользователь, системный администратор или разработчик используя приобретенные навыки.
UPD: Курс очень простой, он для пользователей, которые действительно первый раз запускаю Linux
От автора курса:
Этот курс создан на основе оригинального курса Linux Foundation «Introduction to Linux», который всегда преподавали с инструктором в классе или в виртуальном классе через Интернет. Linux Foundation верит, что задача изменения этого курса для его бесплатного использования сообществом была стоящей и будет хорошо оценена.
HOST1: ip link add grelan type gretap local <IP1> remote <IP2>
HOST1: ip link set grelan up
HOST1: iptables -I INPUT -p gre -s <IP2> -j ACCEPT
HOST2: ip link add grelan type gretap local <IP2> remote <IP1>
HOST2: ip link set grelan up
HOST2: iptables -I INPUT -p gre -s <IP1> -j ACCEPT
Четыре команды на туннель и две на firewall (не нужны если трафик между своими серверми уже разрешен)
Это всё что нужно, дальше длинное объяснение с подробностями.







 Практически все
Практически все  В настоящее время достаточно интересной областью программирования является использование нейронных сетей. Не смотря на всю перспективность этой идеи, большинство реализаций которые я встречал были связаны с различным анализом статистических выборок и предсказанием возможного значения какого-либо параметра.
В настоящее время достаточно интересной областью программирования является использование нейронных сетей. Не смотря на всю перспективность этой идеи, большинство реализаций которые я встречал были связаны с различным анализом статистических выборок и предсказанием возможного значения какого-либо параметра.


 Хороший понедельник, Хабр! Мы продолжаем изучение Erlang для самых маленьких.
Хороший понедельник, Хабр! Мы продолжаем изучение Erlang для самых маленьких. {kind=link}
{kind=link}
{kind=link}