Основываясь на многолетнем опыте преподавания английского специалистам IT-сферы (программистам, бизнес аналитикам, тестировщикам, маркетинговым специалистам), я собрала список наиболее распространенных среди “айтишников” ошибок в английском языке.

Интересуюсь природой вещей

Поскольку я столкнулся с существенными затруднениями в поисках объяснения механизма обратного распространения ошибки, которое мне понравилось бы, я решил написать собственный пост об обратном распространении ошибки реализовав алгоритм Word2Vec. Моя цель, — объяснить сущность алгоритма, используя простую, но нетривиальную нейросеть. Кроме того, word2vec стал настолько популярным в NLP сообществе, что будет полезно сосредоточиться на нем.
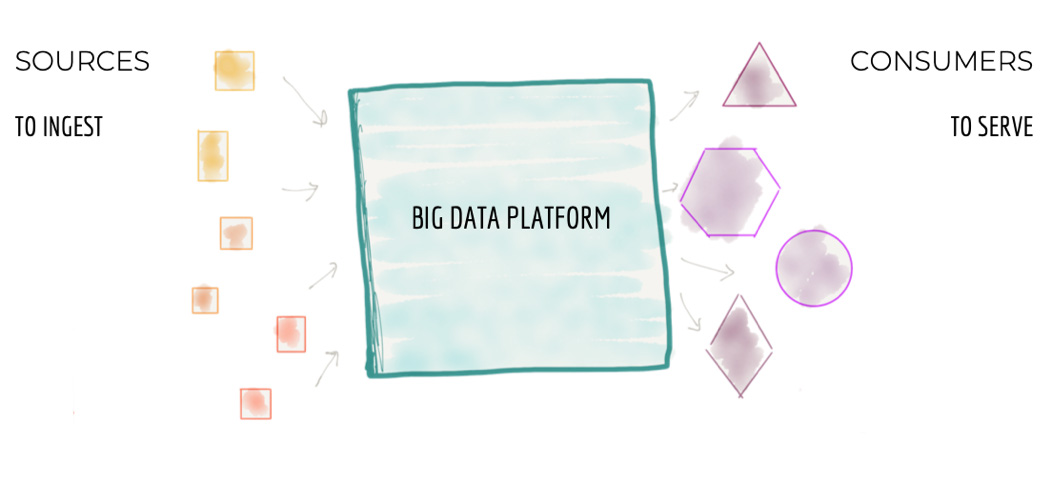
Все крупные компании сейчас пытаются строить огромные централизованные хранилища данных. Или же ещё более огромные кластерные Data Lakes (как правило, на хадупе). Но мне не известно ни одного примера успешного построения такой платформы данных. Везде это боль и страдание как для тех, кто строит платформу данных, так и для пользователей. В статье ниже автор (Жамак Дегани) предлагает совершенно новый подход к построению платформы данных. Это архитектура платформы данных четвертого поколения, которая называется Data Mesh. Оригинальная статья на английском весьма объёмна и откровенно тяжело читается. Перевод так же получился немаленьким и текст не очень прост: длинные предложения, суховатая лексика. Я не стал переформулировать мысли автора, дабы сохранить точность формулировок. Но я крайне рекомендую таки продраться через этот непростой текст и ознакомиться со статьёй. Для тех, кто занимается данными, это будет очень полезно и весьма интересно.
Евгений Черный

Привет! Меня зовут Александр Курилкин, и я веду курс по алгоритмам в «ШАД Helper». В этом посте я разберу несколько задач из вступительных экзаменов прошлых лет, чтобы вы смогли увидеть, что вас ждет, и понять, чему мы сможем вас научить на нашем курсе. Надеюсь, что вы разделяете мою любовь к интересным задачам по алгоритмам и получите искреннее удовольствие от прочтения этого поста! Итак, приступим...



Всем привет! Меня зовут Саша, я CTO & Co-Founder в LoyaltyLab. Два года назад я с друзьями, как и все бедные студенты, ходил вечером за пивом в ближайший магазин у дома. Нас очень расстраивало, что ритейлер, зная, что мы придём за пивом, не предлагает скидку на чипсы или сухарики, хотя это так логично! Мы не поняли, почему такая ситуация происходит и решили сделать свою компанию. Ну и как бонус выписывать себе скидки каждую пятницу на те самые чипсы.

И дошло всё до того, что с материалом по технической стороне продукта я выступаю на NVIDIA GTC. Мы рады делиться наработками с коммьюнити, поэтому я выкладываю свой доклад в виде статьи.
Привет, Хабр! Представляю вашему вниманию перевод статьи "Web2Text: Deep Structured Boilerplate Removal" коллектива авторов Thijs Vogels, Octavian-Eugen Ganea и Carsten Eickhof.
Веб-страницы являются ценным источником информации для многих задач обработки естественного языка и поиска информации. Эффективное извлечение основного содержимого из этих документов имеет важное значение для производительности производных приложений. Чтобы решить эту проблему, мы представляем новую модель, которая выполняет классификацию и маркировку текстовых блоков на странице HTML как шаблонных блоков, или блоков содержащих основной контент. Наш метод использует Скрытую Марковскую модель поверх потенциалов, полученных из признаков объектной модели HTML-документа (Document Object Model, DOM) с использованием сверточных нейронных сетей (Convolutional Neural Network, CNN). Предложенный метод качественно повышает производительность для извлечения текстовых данных из веб-страниц.

Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Представлены обзоры 11 статей по Computer Vision, Natural Language Processing, Reinforcement learning и другим темам.

