

Вообще-то, третья статья данного цикла должна была рассказывать о конкретных оптимизациях. Но пока я прикидывал её план, стало ясно, что без освещения некоторых аспектов неопределённого поведения многое из дальнейших описаний будет непонятно. Поэтому сделаем ещё один осторожный шаг, прежде, чем окунаться в омут с головой.
Наверное, многие слышали, что неопределённое поведение (undefined behavior, UB) -- постоянный источник разнообразных багов, иногда очень забавных, иногда довольно жутких. Тема также неоднократно освещалась и на Хабре, навскидку раз, два, три (и даже целый тег есть). Однако чаще всего статьи по данной теме посвящены тому, как можно отстрелить себе ногу, голову или случайно сжечь свой жёсткий диск, исполнив какой-нибудь опасный код. Я же намерен сделать акцент на том, зачем авторы языков программирования надобавляли всей этой красоты, и как оптимизатор может её эксплуатировать. Всё будет проиллюстрировано наглядными примерами из LLVM и присыпано байками из собственного опыта, так что наливайте себе чай, располагайтесь поудобнее, и погнали.

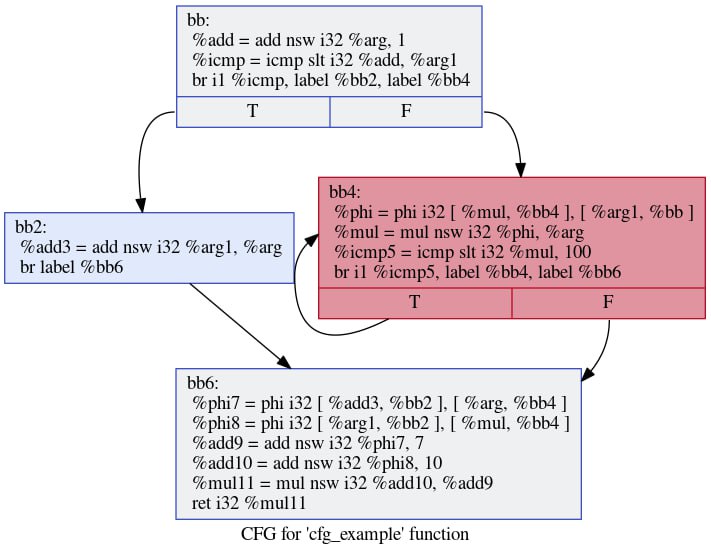




 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.



{kind=link}