Иногда полезно представить граф в графической форме, так чтобы была видна структура. Можно привести десятки примеров, где это может пригодиться: визуализация иерархии классов и пакетов исходного кода какой-нибудь программы, визуализация социального графа (тот же Twitter или Facebook) или графа цитирования (какие публикации на кого ссылаются) и т.д. Но вот незадача: количество ребер в графе зачастую настолько велико, что нарисованный граф просто невозможно разобрать. Взгляните на эту картинку:
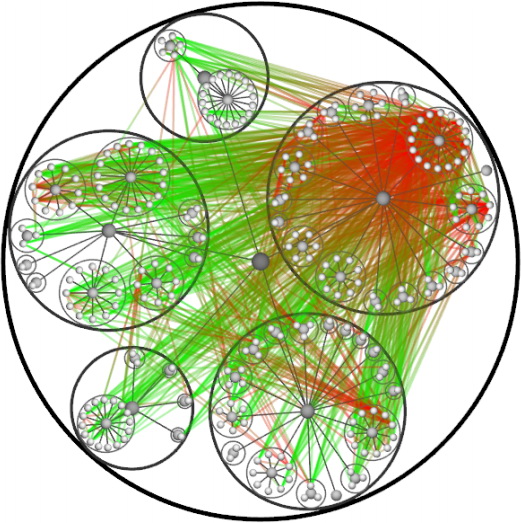
Это граф зависимостей некой программной системы. Он представляет собой дерево разбиения на пакеты (серые шарики — пакеты, белые — классы), на которое поверх наложены ребра зависимости одних классов от других. Чтобы не рисовать стрелки направления, ребра нарисованы в виде градиентных линий, где зеленый — это начало, а красный — конец ребра. Как видите, граф настолько визуально перегружен, что архитектуру программы невозможно проследить.
Под катом описание метода, решающего эту проблему.


