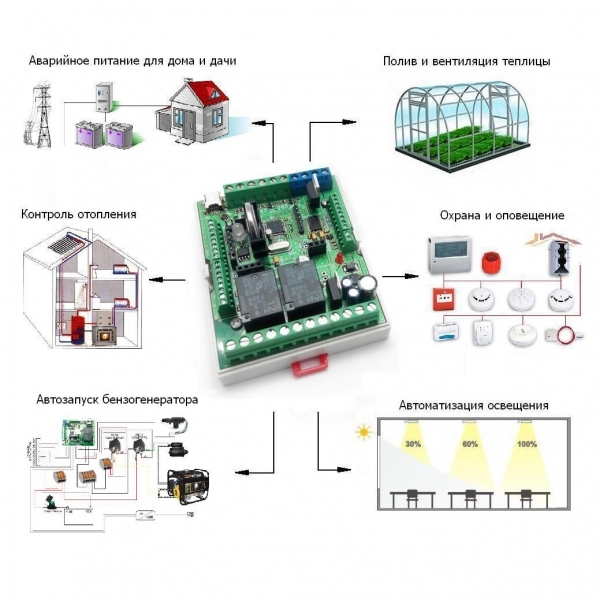
В конце 2008 года на тогда ещё небольшую петербуржскую компанию вышел один западный медиахолдинг
примерно так:
— Это вы там упоролись по хардкору и приспособили SSE-инструкции для реализации кода Рида-Соломона?
— Да, только мы не…
— Да мне пофиг. Хотите заказ?
Проблема была в том, что видеомонтаж требовал адовой производительности, и тогда использовались RAID-5 массивы. Чем больше дисков в RAID-5 — тем выше была вероятность отказа прямо во время монтажа (для 12 дисков — 6%, а для 36 дисков — уже 17-18%).
Дроп диска при монтаже недопустим: даже если диск падает в хайэндовой СХД, скорость резко деградирует. Медиахолдигу надоело с криком биться головой о стену каждый раз, и поэтому кто-то посоветовал им сумрачного русского гения.
Много позже, когда наши соотечественники подросли, возникла вторая интересная задача —
Silent Data Corruption. Это такой тип ошибок хранения, когда на блине одновременно меняется и бит в основных данных, и контрольный бит. Если речь о видео или фотографии — в целом, никто даже не заметит. А если речь про медицинские данные, то это становится диагностической проблемой. Так появился специальный продукт под этот рынок.
Ниже — история того, что они делали, немного математики и результат —
ОС для highload-СХД. Серьёзно, первая русская ОС, доведённая до ума и выпущенная. Хоть и для СХД.




 Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.







 Мерило нравственности и блюститель духовных скреп российских граждан, Елена Борисовна Мизулина возвращается на законодательное поле боя с новой инициативой — оградить российских детей от «плохих» онлайн видеоигр. В целом, член Совета Федерации Федерального собрания Российской Федерации
Мерило нравственности и блюститель духовных скреп российских граждан, Елена Борисовна Мизулина возвращается на законодательное поле боя с новой инициативой — оградить российских детей от «плохих» онлайн видеоигр. В целом, член Совета Федерации Федерального собрания Российской Федерации