Часть 1: Постановка задачи
Привет, Хабр! Я архитектор решений в компании CleverDATA. Сегодня я расскажу про то, как мы классифицируем большие объемы данных с использованием моделей, построенных с применением практически любой доступной библиотеки машинного обучения. В этой серии из двух статей мы рассмотрим следующие вопросы.
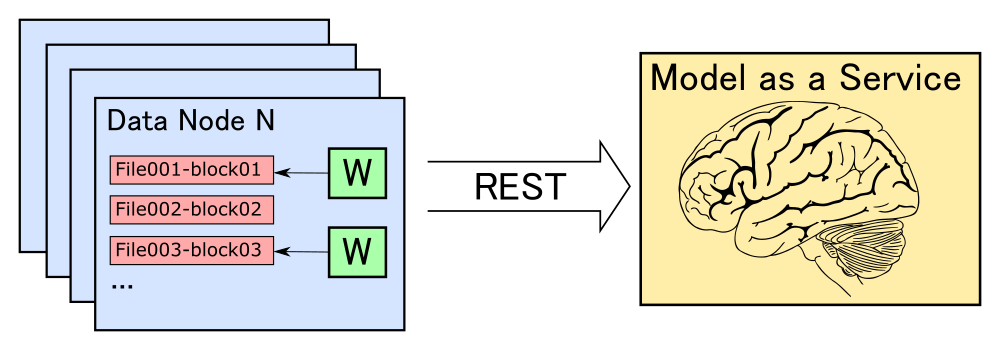
- Как представить модель машинного обучения в виде сервиса (Model as a Service)?
- Как физически выполняются задачи распределенной обработки больших объемов данных при помощи Apache Spark?
- Какие проблемы возникают при взаимодействии Apache Spark с внешними сервисами?
- Как при помощи библиотек akka-streams и akka-http, а также подхода Reactive Streams можно организовать эффективное взаимодействие Apache Spark с внешними сервисами?
Изначально я планировал написать одну статью, но так как объем материала оказался достаточно большим, я решил разбить ее на две части. Сегодня в первой части мы рассмотрим общую постановку задачи, а также основные проблемы, которые необходимо решить при реализации. Во второй части мы поговорим о практической реализации решения данной задачи с использованием подхода Reactive Streams.