Три года назад я опубликовал
статью, посвященную идее «динамических курсов» (тех, что генерируются из базы знаний в момент запроса пользователя), а чуть позже
разработал несложный сервис, который ее реализует. Сейчас этот сервис доступен на другом сайте
kursopoisk.ru и, фактически, представляет собой библиотеку атомарного контента (статьи, видеоролики и расчеты, главным образом, по математике), из которого, в соответствии с заранее прописанными связями, и формируются подобные микрокурсы. Я их называю динамическими, однако, в духе современной терминологии, правильно было бы использовать термин
траектории обучения. Сразу хочу сказать, что создавал я Курсопоиск, в первую очередь, для себя, чтобы самому быстро находить нужный контент и вспоминать материал, с которым когда-то разобрался, а потом благополучно забыл.
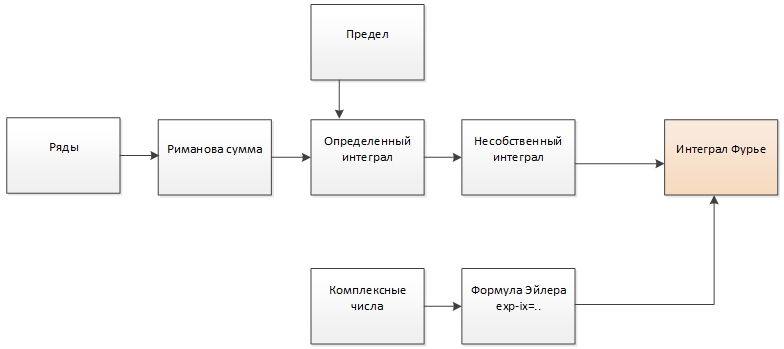
Принцип формирования траекторий иллюстрируется рисунком и был подробно описан в
предыдущей статье, поэтому я не буду повторяться, а расскажу о том, что поменялось.