
В этой статье мы познакомимся с эффективными приемами работы с DOM, которые помогут минимизировать потребление памяти и обеспечить высокую производительность ваших приложений.

User
В этой статье мы познакомимся с эффективными приемами работы с DOM, которые помогут минимизировать потребление памяти и обеспечить высокую производительность ваших приложений.

Цель этого руководства — познакомить вас со списком новых (потрясающих) возможностей, недавно появившихся в CSS.
В представленных здесь функциях есть гораздо больше синтаксиса, подробностей и нюансов, я просто хотел показать вам возможности, продемонстрировать базовый синтаксис и примеры использования, чтобы вы при желании могли исследовать тему глубже.

Метод опорных векторов (Support Vector Machines или просто SVM) — мощный и универсальный набор алгоритмов для работы с данными любой формы, применяемый не только для задач классификации и регрессии, но и также для выявления аномалий. В данной статье будут рассмотрены основные подходы к созданию SVM, принцип работы, а также реализации с нуля его наиболее популярных разновидностей.

Далее пойдёт речь про бэггинг и мой самый любимый алгоритм — случайный лес. Не смотря на то, что это одни из самых первых алгоритмов среди семейства ансамблей, они до сих пор пользуются большой популярностью за счёт своей простоты и эффективности, зачастую не уступая бустингам в плане точности. О том, что это такое и как работает, далее в статье.
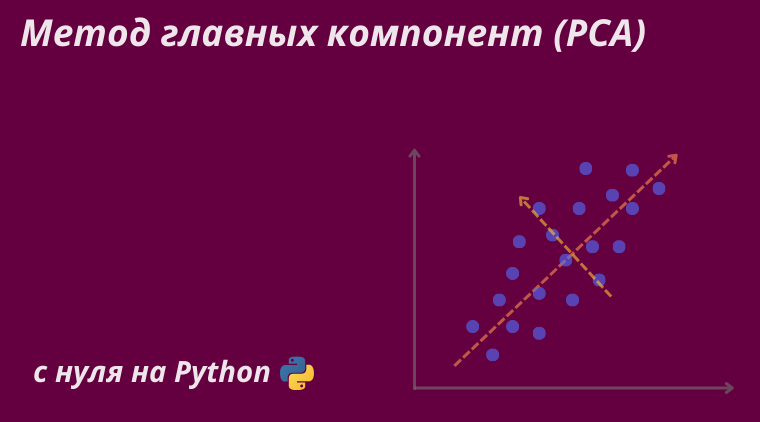
Метод главных компонент (Principal Component Analysis или же PCA) — алгоритм обучения без учителя, используемый для понижения размерности и выявления наиболее информативных признаков в данных. Его суть заключается в предположении о линейности отношений данных и их проекции на подпространство ортогональных векторов, в которых дисперсия будет максимальной.
Такие вектора называются главными компонентами и они определяют направления наибольшей изменчивости (информативности) данных. Альтернативно суть PCA можно определить как линейное проецирование, минимизирующее среднеквадратичное расстояние между исходными точками и их проекциями.

На сегодняшний день градиентный бустинг (gradient boosting machine) является одним из основных production-решений при работе с табличными, неоднородными данными, поскольку обладает высокой производительностью и точностью, а если быть точнее, то его модификации, речь о которых пойдёт чуть позже.
В данной статье представлена не только реализация градиентного бустинга GBM с нуля на Python, но а также довольно подробно описаны ключевые особенности его наиболее популярных модификаций.

Следующим мощным алгоритмом машинного обучения является AdaBoost (adaptive boosting), в основе которого лежит концепция бустинга, когда слабые базовые модели последовательно объединяются в одну сильную, исправляя ошибки предшественников.
В AdaBoost в качестве базовой модели используется пень решений (могут использоваться другие модели) — дерево с небольшой глубиной, которому присваивается вектор весов размера N, каждое значение которого соответствует определённому значению y_train и изначально равно 1 / N, где N — количество образцов в обучающей выборке. Каждый следующий пень обучается с учётом весов, рассчитанных на основе ошибок предыдущего прогноза. Также для каждого обученного пня отдельно рассчитывается вес, используемый для оценки важности итоговых прогнозов.

К-ближайших соседей (K-Nearest Neighbors или просто KNN) — алгоритм классификации и регрессии, основанный на гипотезе компактности, которая предполагает, что расположенные близко друг к другу объекты в пространстве признаков имеют схожие значения целевой переменной или принадлежат к одному классу.

Дерево решений CART (Classification and Regressoin Tree) — алгоритм классификации и регрессии, основанный на бинарном дереве и являющийся фундаментальным компонентом случайного леса и бустингов, которые входят в число самых мощных алгоритмов машинного обучения на сегодняшний день. Деревья также могут быть не бинарными в зависимости от реализации. К другим популярным реализациям решающего дерева относятся следующие: ID3, C4.5, C5.0.

Наивный байесовский классификатор (Naive Bayes classifier) — вероятностный классификатор на основе формулы Байеса со строгим (наивным) предположением о независимости признаков между собой при заданном классе, что сильно упрощает задачу классификации из-за оценки одномерных вероятностных плотностей вместо одной многомерной.
Помимо теории и реализации с нуля на Python, в данной статье также будет приведён небольшой пример использования наивного Байеса в контексте фильтрации спама со всеми подробными расчётами вручную.

Линейный дискриминантный анализ (Linear Discriminant Analysis или LDA) — алгоритм классификации и понижения размерности, позволяющий производить разделение классов наилучшим образом. Основная идея LDA заключается в предположении о многомерном нормальном распределении признаков внутри классов и поиске их линейного преобразования, которое максимизирует межклассовую дисперсию и минимизирует внутриклассовую. Другими словами, объекты разных классов должны иметь нормальное распределение и располагаться как можно дальше друг от друга, а одного класса — как можно ближе.
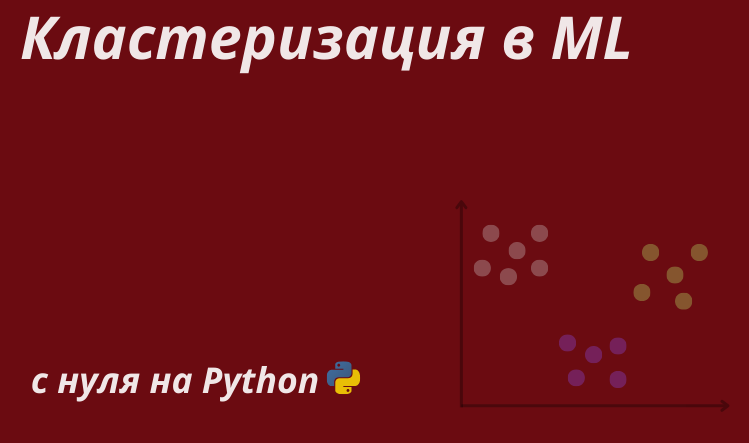
Кластеризация — это набор методов без учителя для группировки данных по определённым критериям в так называемые кластеры, что позволяет выявлять сходства и различия между объектами, а также упрощать их анализ и визуализацию. Из-за частичного сходства в постановке задач с классификацией кластеризацию ещё называют unsupervised classification.
В данной статье описан не только принцип работы популярных алгоритмов кластеризации от простых к более продвинутым, но а также представлены их упрощённые реализации с нуля на Python, отражающие основную идею. Помимо этого, в конце каждого раздела указаны дополнительные источники для более глубокого ознакомления.

Как правило, работа с документацией — это последний этап любого проекта, связанного с данными (data science, data visualization и т. д.), проектированием и разработкой ПО. Речь о создании и редактировании библиотек, файлов README, обучающих материалов и др. Среди всех преимуществ VScode — его уникальная экосистема расширений. И особенно впечатляют те, что помогают работать с документацией. В этой статье поделюсь самыми полезными из них.
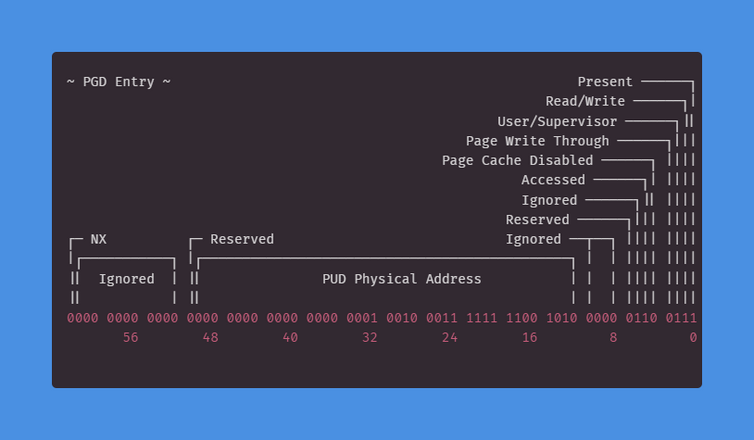
В этом посте я буду говорить о страничной организации только в контексте PML4 (Page Map Level 4), потому что на данный момент это доминирующая схема страничной организации x86_64 и, вероятно, останется таковой какое-то время.
Окружение
Это необязательно, но я рекомендую подготовить систему для отладки ядра Linux с QEMU + gdb. Если вы никогда этого не делали, то попробуйте такой репозиторий: easylkb (сам я им никогда не пользовался, но слышал о нём много хорошего), а если не хотите настраивать окружение самостоятельно, то подойдёт режим практики в любом из заданий по Kernel Security на pwn.college (вам нужно знать команды vm connect и vm debug).
Я рекомендую вам так поступить, потому что считаю, что самостоятельное выполнение команд вместе со мной и возможность просмотра страниц (page walk) на основании увиденного в gdb — хорошая проверка понимания.
В C и C++ есть особенности, о которых вас вряд ли спросят на собеседовании (вернее, не спросили бы до этого момента). Почему не спросят? Потому что такие аспекты имеют мало практического значения в повседневной работе или попросту малоизвестны.
Целью статьи является не освещение какой-то конкретной особенности языка или подготовка к собеседованиям, и уж тем более нет цели рассказать все потайные смыслы языка, т. к. для этого не хватит одной статьи и даже книги. Напротив, статья нужна для того, чтобы показать малоизвестные и странные решения, принятые в языках C и C++. Своего рода солянка из фактов. Вопрос “что делать с этими знаниями?” я оставляю читателю.
Если вы, как и я, любите и интересуетесь C/C++, и эти языки являются неотъемлемой частью вашей жизни, в том числе и его углубленного изучения, то эта статья для вас. По большей части я надеюсь, что эта статья сможет развлечь и заставить поработать головой. И если получится, рассказать что-то, чего вы, возможно, еще не знали.

Игры бывают разные, большие и маленькие, триA и супер инди, в компаниях с сотнями разработчиков и что создаются самородками-одиночками. Редко их делают с нуля и пишут код только игры, чаще пишут игровые тулы, редактор и параллельно пишут саму игру. За всей этой многомиллиардной индустрией стоит код, много кода, очень много кода. Игровые движки и фреймворки – мощные инструменты, которые помогают разработчику творить его идеи и создавать увлекательные игровые миры. Это каркас, на котором строятся все игровые вселенные, они включают в себя сотни инструментов, библиотек и ресурсов, позволяя разработчикам превратить строчки кода в театр для одного зрителя.
Существует более сотни игровых движков, каждый из них содержит как минимум одну фичу которой нет ни в каком другом. Всех возможностей вместе нет ни в одном, и это прекрасно - иначе бы такой движок монополизировал рынок. Хм, Unreal5 ты ли это? Иногда полезно пробежать по release notes движка, чтобы оставаться в курсе последних новостей. Возможно вы разрабатываете свое решение и эта статья натолкнет вас на новые идеи. Готовы узнать что ваша любимая игры была сделана не на Unity, а на православном SDL?

В рамках данной статьи я постарался написать полноценное руководство по разработке простого драйвера под операционную систему Windows 10. Всем новичкам, заинтересованным в системном программировании рекомендую ознакомиться. Это поможет вам сделать первые шаги в разработке драйверов.
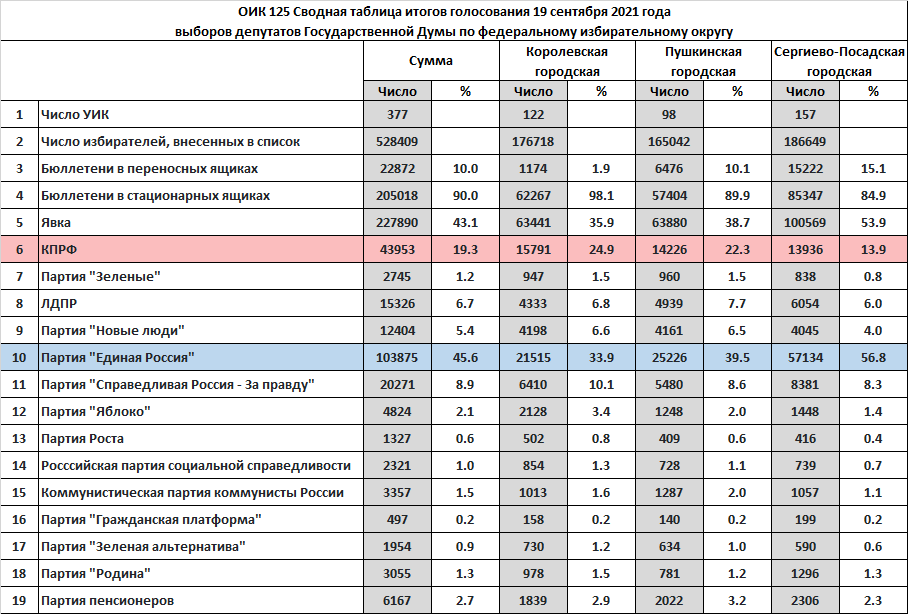
Статистика 377 участковых избирательных комиссий Королёва, Пушкино, Сергиева Посада, входящих 125 ОИК по голосованию 19 сентября 2021 года по выборам депутатов Государственной Думы РФ. Диаграммы явки и результативности партий, поиск критерия определения "предполагаемых" фальсификаций. Расчет скорректированного результата.
Три частично перекрывающихся кластера УИК.
Первый: явка 20-45% при доле Единой России 20-40%, условно его обозначим “гладкое голосование”.
Второй: явка 40-65% при доле Единой России 35-65%, условно его обозначим “административная мобилизация”.
Третий: явка более 65% при доле Единой России более 60%, условно его обозначим “предполагаемые грубые фальсификации”.

Привет, Хабр! Сегодня хочу предложить вашему вниманию перевод на русский язык статьи моего коллеги и хорошего приятеля Dunfan Lu. Он создал taichi.js - open-source фреймворк для программирования графики на WebGPU, и написал подробный туториал как его использовать на примере знаменитой "Игры жизни". Уверен, эта сложная и красивая работа на стыке технологий рендеринга и компиляции не оставит вас равнодушными. - пр. переводчика.