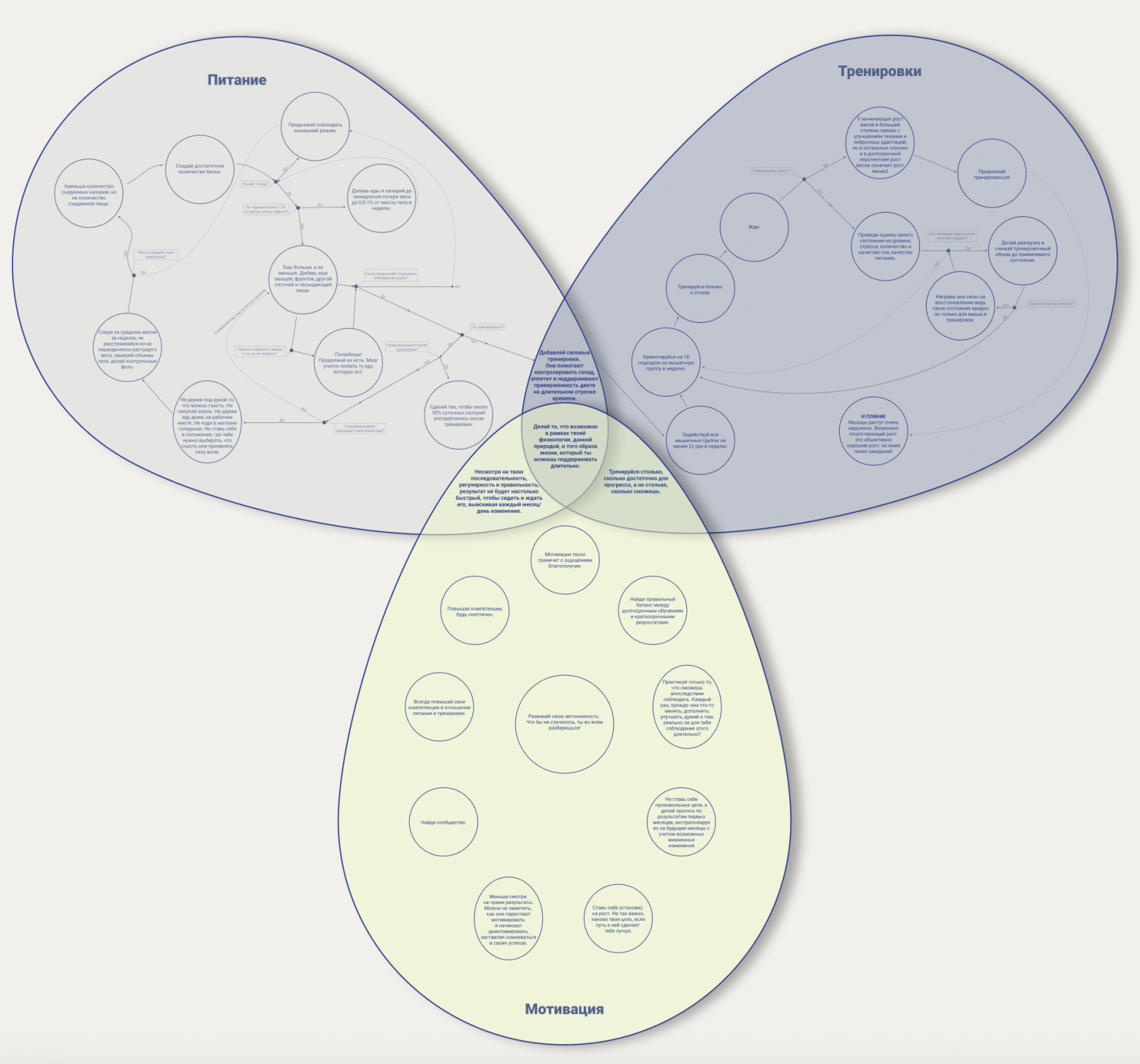
Попробую внести ясность в этот вопрос.
Бывает, читая статью про похудение, не так интересна статья, как комментарии к ней, где каждый отчасти соглашаясь с автором «да это же очевидно, чтобы похудеть, нужно меньше есть», добавляет что-то со своей колокольни «но как можно худеть, если плохие гормоны/замедленный метаболизм/тяга на сладкое/» и т.д.
Я тренирую онлайн и один из частых запросов подопечных — это снижение веса. Я не диетолог, и не составляю рацион для людей с заболеваниями ЖКТ и прочее. Я не нутрициолог, и не составляю рационы по микроэлементам, чтобы восполнить дефициты веществ etc. Я — тренер и мотивирую (заставляю) подопечных тренироваться под моим контролем до тех пор, пока это не войдет в устойчивую привычку, а чтобы тренинг не сопровождался упадком сил, травмами, недовосстановлением, помогаю корректировать питание. Да и яркие результаты в тренировках возможны только при правильно подобранном рационе. Когда все эти условия выполняются, мой подопечный неизбежно худеет, даже тогда, когда такой задачи не ставилось.
Так что накопившийся опыт позволяет порассуждать в этом направлении и разобрать частые заблуждения относительно процесса снижения веса, которые очередной раз встретились в комментариях.