Cоревнование по определению костного возраста. Заметки участника
6-го октября на радары
Володи Игловикова попал очень интересный
конкурс, организованный американскими рентгенологами из The Radiological Society of North America (
RSNA) и Radiology Informatics Committee (
RIC), и он бросил клич в сообществе
ODS.ai
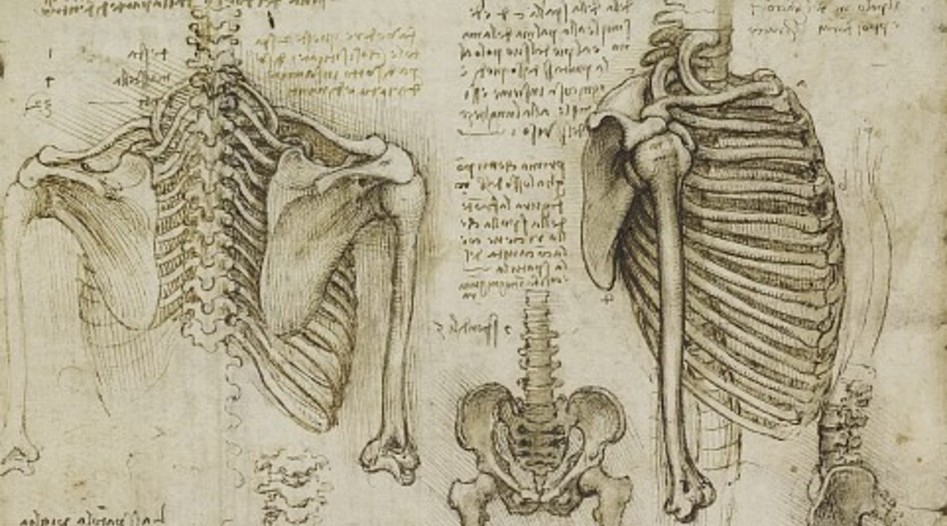
Целью конкурса было создание автоматической системы для определения костного возраста по рентгеновским снимкам руки. Костный возраст используется в педиатрии для комплексной оценки физического развития детей, и его отклонение от хронологического помогает выявить нарушения в работе различных систем организма. Когда дело касается медицинских проектов, меня уговаривать не надо, но это соревнование стартовало в августе и вступать в него за 8 дней до окончания выглядело авантюрой. Чтобы хотя бы начать препроцессинг снимков, требовались маски рук, и Володя сделал их за несколько дней, отличного качества, и поделился с остальными. Как он так быстро справился с этой тяжёлой задачей, включавшей ручную разметку – загадка, и об этом он, возможно, напишет сам. С масками затея уже не выглядела безнадёжной, я решился участвовать и в конечном счёте успел реализовать почти все планы.
Задача
 Костный возраст
Костный возраст (bone age) — это условный возраст, которому соответствует уровень развития костей детей и подростков. Формирование скелета происходит в несколько стадий. Это используется в педиатрии для сравнения костного возраста с хронологическим, что позволяет вовремя заметить нарушения в работе эндокринной системы и системы обмена веществ.
Для определения костного возраста в основном используются две методики — GP Грейлиха и Пайла (Greulich and Pyle) и TW2 Таннера, Уайтхауза и Хили (Tanner, Whitehouse, Healy), разработанные во второй половине XX века. Обе методики основаны на рентгенограмме кисти и лучезапястного сустава. Благодаря большому количеству участков растущей ткани в костях и ядер окостенения,






 Листая страницы хаба «Алгоритмы», наткнулся на
Листая страницы хаба «Алгоритмы», наткнулся на 

 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В 
 От переводчика:
От переводчика:
 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но 
