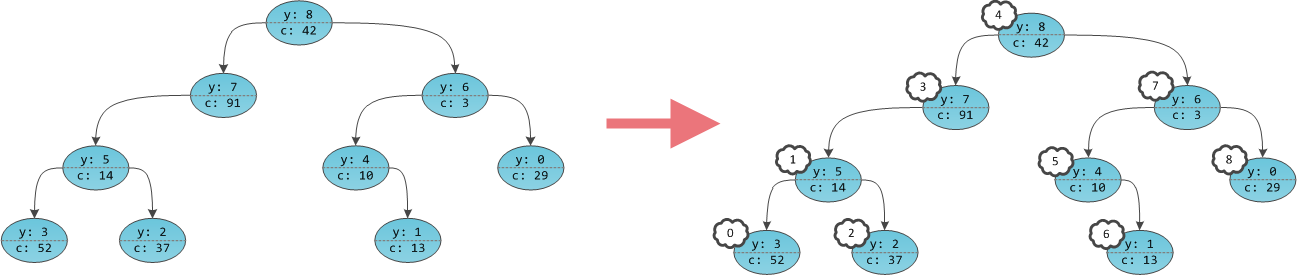
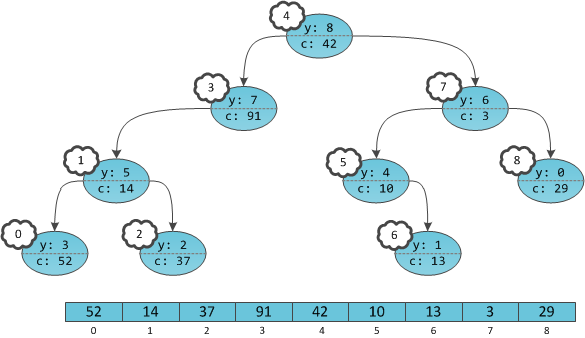
Одна из внезапных проблем при использовании
GPT — (если мы хотим увидеть приличную скорость записи) необходимость руками подстраивать положение раздела на дисках WD с Advanced format. Суть Advanced Format проста: внутри диск имеет 4к сектора, наружу они эмулируются как 512-байт. Если мы делаем запись двух секторов в пределах одного 4к блока, он записывается один раз. Если мы делаем запись двух секторов так, что задеваем два 4к-сектора — диску приходится читать два сектора, обновлять информацию и записывать их обратно. Плохо и медленно. Современные ОС используют 4к блоки для записи, так что если мы попадём правильно, то каждая операция записи будет просто записью, без чтения. Если же мы попадём неровно (например, 2кб из первого сектора и 2кб из второго), то мы получим огромные тормоза (см ссылку внизу на сайт IBM с статистикой «торможения» при ошибках в разметке).
WD, когда размышляла насчёт 512 VS 4k, не учла, что помимо MBR есть ещё GPT. В случае 2Тб дисков MBR ещё терпит, однако, впереди диски на 3Тб, и в них MBR просто математически не сможет обеспечить разделы и переход на GPT неизбежен.
Так что проблему GPT и WD нужно учитывать уже сегодня. Основным инструментом для манипуляций с GPT в настоящий момент является parted и его графическая версия gparted. К сожалению, gparted не умеет того, что нам нужно, так что всё последующее описывает использование parted.
Основная мысль: Все величины (начало, конец раздела) должны быть кратны 4кБ, или, что чуть проще, 8 секторам. Это требование WD advanced format.
Сама GPT занимает некоторый объём (33 сектора: 32 сектора GPT, 1 сектор — фальшивый MBR-затычка), так что первое кратное 8 число, с которым мы можем работать — 40 секторов. Оконечное число зависит от ёмкости диска, но тоже, желательно, кратное 8. Кроме того, GPT дублируется в конце диска, так что место в конце диска так же будет «обкусано».
Для наилучшей производительности нужно учесть размер PE для LVM — 4Mb (8192 сектора) и установить размер тома кратным количеству PE. В результате всех этих манипуляций мы потеряем чуть-чуть места (меньше 8Мб), но зато получим быстрый том, у которого будут отсутствовать «unused» килобайты в описании в LVM.
Помимо этого есть ещё мнение самого gparted, о том, что лучшее положение тома — кратно мегабайтам. Таким образом, итоговые требования звучат так: том должен начинаться и заканчиваться на величинах, кратных 4Мб.
Итак, создание LVM тома на WD'шном диске с Advanced Format:


 Современные поисковые системы способны самостоятельно упорядочивать огромные объемы информации, позволяя быстро находить материалы по любой теме. Но когда дело касается поиска товаров в интернет-магазинах или вакансий в базах рекрутинговых агентств, или предложений автомобилей по сайтам автосалонов, в общем поиска любой каталогизированной информации в Интернет, о самостоятельности поисковых систем говорить не приходится, потому что для удовлетворения таких запросов в большинстве случаев они требуют от сайтов-источников выгрузки (
Современные поисковые системы способны самостоятельно упорядочивать огромные объемы информации, позволяя быстро находить материалы по любой теме. Но когда дело касается поиска товаров в интернет-магазинах или вакансий в базах рекрутинговых агентств, или предложений автомобилей по сайтам автосалонов, в общем поиска любой каталогизированной информации в Интернет, о самостоятельности поисковых систем говорить не приходится, потому что для удовлетворения таких запросов в большинстве случаев они требуют от сайтов-источников выгрузки (