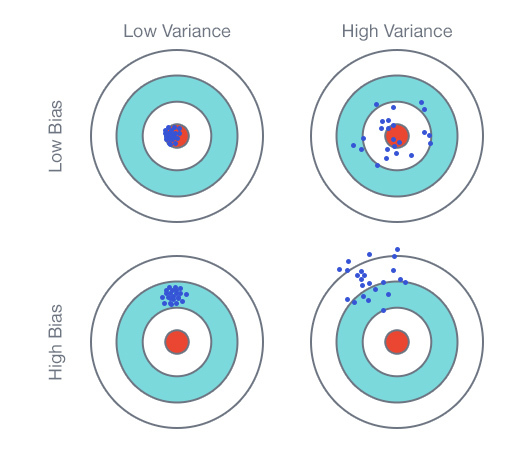
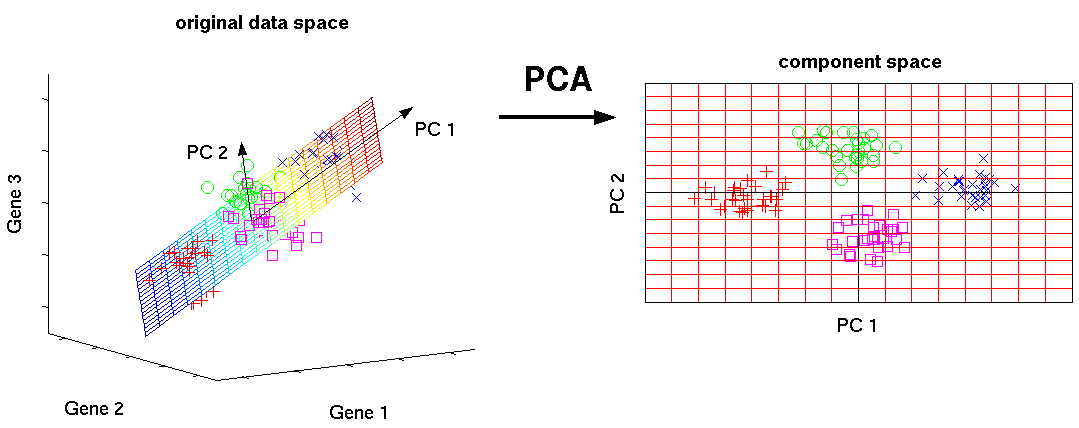
Привет, читатель.
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Представляю пост который идёт строго (!) в закладки и передаётся коллегам. Он с подборкой примечательных файлов формата Jupyter Notebook по Machine Learning, Data Science и другим сферам, связанным с анализом данных. Эти блокноты Jupyter, будут наиболее полезны специалистам по анализу данных — как обучающимся новичкам, так и практикующим профи.

Итак, приступим.
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Представляю пост который идёт строго (!) в закладки и передаётся коллегам. Он с подборкой примечательных файлов формата Jupyter Notebook по Machine Learning, Data Science и другим сферам, связанным с анализом данных. Эти блокноты Jupyter, будут наиболее полезны специалистам по анализу данных — как обучающимся новичкам, так и практикующим профи.
Итак, приступим.
 Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.
Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.