Google использует своего «паука» FeedFetcher для кэширования любого контента в Google Spreadsheet, вставленного через формулу
=image(«link»).
Например, если в одну из клеток таблицы вставить формулу
=image("http://example.com/image.jpg")
Google отправит паука FeedFetcher скачать эту картинку и закэшировать для дальнейшего отображения в таблице.
Однако если добавлять случайный параметр к URL картинки, FeedFetcher будет скачивать её каждый раз заново. Скажем, для примера, на сайте жертвы есть PDF-файл размером в 10 МБ. Вставка подобного списка в таблицу приведет к тому, что паук Google скачает один и тот же файл 1000 раз!
=image("http://targetname/file.pdf?r=1")
=image("http://targetname/file.pdf?r=2")
=image("http://targetname/file.pdf?r=3")
=image("http://targetname/file.pdf?r=4")
...
=image("http://targetname/file.pdf?r=1000")
Все это может привести к исчерпанию лимита трафика у некоторых владельцев сайтов. Кто угодно, используя лишь браузер с одной открытой вкладкой, может запустить массированную HTTP GET FLOOD-атаку на любой веб-сервер.
Атакующему даже необязательно иметь быстрый канал. Поскольку в формуле используется ссылка на PDF-файл (т.е. не на картинку, которую можно было бы отобразить в таблице), в ответ от сервера Google атакующий получает только
N/A. Это позволяет довольно просто многократно усилить атаку
[Аналог DNS и NTP Amplification – прим. переводчика], что представляет серьезную угрозу.
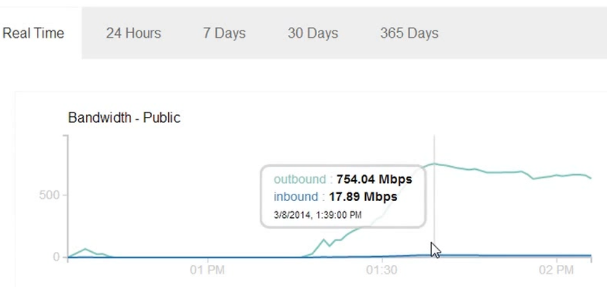
С использованием одного ноутбука с несколькими открытыми вкладками, просто копируя-вставляя списки ссылок на файлы по 10 МБ, паук Google может скачивать этот файл со скоростью более 700 Мбит/c. В моем случае, это продолжалось в течение 30-45 минут, до тех пор, пока я не вырубил сервер. Если я все правильно подсчитал, за 45 минут ушло примерно 240GB трафика.

 Практически любое веб-приложение предоставляет возможность авторизации пользователя с использованием учетной записи пользователя, в каком либо из известных социальных сервисов.
Практически любое веб-приложение предоставляет возможность авторизации пользователя с использованием учетной записи пользователя, в каком либо из известных социальных сервисов.




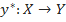 , значения которой известны только на объектах конечной обучающей выборки
, значения которой известны только на объектах конечной обучающей выборки 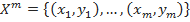 . Требуется построить алгоритм
. Требуется построить алгоритм 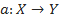 , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений
, способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений  Привет, Хабр! Полагаю, многие слышали о системе Wolfram Mathematica, однако, судя по тому что на Хабре нет даже отдельного хаба, посвященного технологиям Wolfram, не многие осознают их реальный потенциал. Но, похоже это скоро изменится, так как Wolfram близки к окончательному релизу технологии, которую они разрабатывали 30 лет. Она называется Wolfram Language и представляет собой совершенно новую парадигму программирования, намного более мощную, чем все существующие.
Привет, Хабр! Полагаю, многие слышали о системе Wolfram Mathematica, однако, судя по тому что на Хабре нет даже отдельного хаба, посвященного технологиям Wolfram, не многие осознают их реальный потенциал. Но, похоже это скоро изменится, так как Wolfram близки к окончательному релизу технологии, которую они разрабатывали 30 лет. Она называется Wolfram Language и представляет собой совершенно новую парадигму программирования, намного более мощную, чем все существующие.

 Изначально хотел назвать статью «HTML по ГОСТ`у», но потом выяснилось что у большинства программистов не было предмета «Метрология и стандартизация» и о «стандартизации», «сертификации», «унификации» не все слышали.
Изначально хотел назвать статью «HTML по ГОСТ`у», но потом выяснилось что у большинства программистов не было предмета «Метрология и стандартизация» и о «стандартизации», «сертификации», «унификации» не все слышали.