Движущая сила микросервисов
Возможность разрабатывать, развертывать и масштабировать различные бизнес-функции независимо друг от друга — это одно из самых разрекламированных преимуществ перехода на микросервисную архитектуру.
Пока властители дум всё ещё не могут определиться, справедливо ли это утверждение или нет, микросервисы уже успели войти в моду — причем до такой степени, что для большинства стартапов они де-факто стали архитектурой, выбираемой по умолчанию.
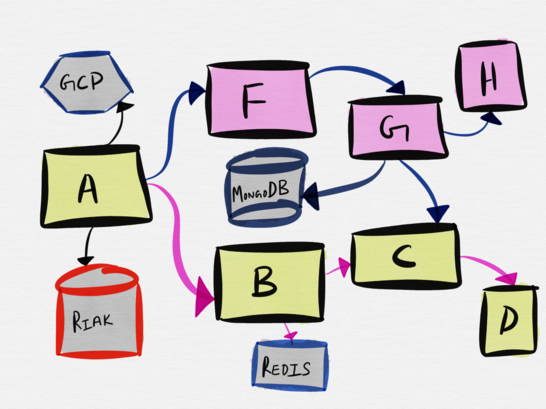
Однако, когда дело доходит до тестирования (или, чего похуже, разработки) микросервисов, выясняется, что большинство компаний по-прежнему испытывает привязанность к допотопному способу тестирования всех компонентов вместе. Создание сложной инфраструктуры считается обязательным условием для проведения сквозного (end-to-end) тестирования, при котором набор тестов для каждого сервиса обязательно должен быть выполнен — делается это для того, чтобы убедиться, что в сервисах не появилось регрессий или несовместимых изменений.