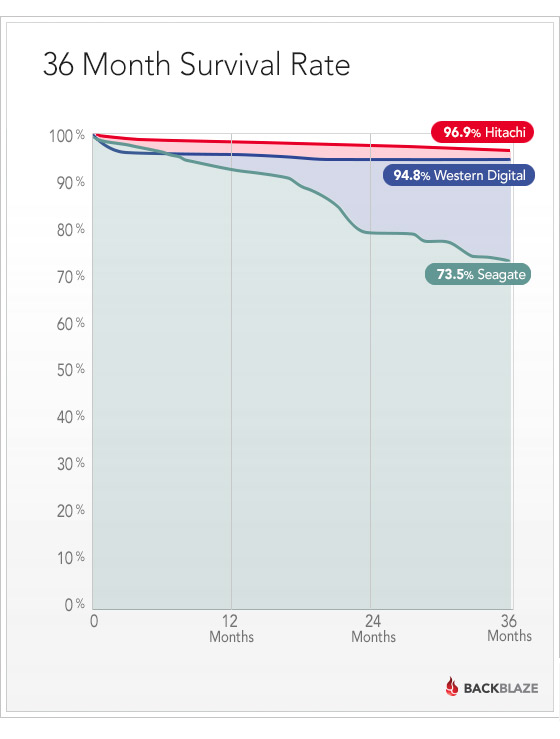
От переводчика: Это перевод второй статьи из цикла «Networking for game programmers». Мне очень нравится весь цикл статей, плюс всегда хотелось попробовать себя в качестве переводчика. Возможно, опытным разработчикам статья покажется слишком очевидной, но, как мне кажется, польза от нее в любом случае будет.
Первая статья — http://habrahabr.ru/post/209144/
Прием и передача пакетов данных
Введение
Привет, меня зовут Гленн Фидлер и я приветствую вас в своей второй статье из цикла “Сетевое программирование для разработчиков игр”.
В
предыдущей статье мы обсудили различные способы передачи данных между компьютерами по сети, и в конце решили использовать протокол UDP, а не TCP. UDP мы решили использовать для того, чтобы иметь возможность пересылать данные без задержек, связанных с ожиданием повторной пересылки пакетов.
А сейчас я собираюсь рассказать вам, как на практике использовать UDP для отправки и приема пакетов.
BSD сокеты
В большинстве современных ОС имеется какая-нибудь реализация сокетов, основанная на BSD сокетах (сокетах Беркли).
Сокеты BSD оперируют простыми функциями, такими, как “socket”, “bind”, “sendto” и “recvfrom”. Конечно, вы можете обращаться к этим функциями напрямую, но в таком случае ваш код будет зависим от платформы, так как их реализации в разных ОС могут немного отличаться.
Поэтому, хоть я далее и приведу первый простой пример взаимодействия с BSD сокетами, в дальнейшем мы не будем использовать их напрямую. Вместо этого, после освоения базового функционала, мы напишем несколько классов, которые абстрагируют всю работу с сокетами, чтобы в дальнейшем наш код был платформонезависимым.