
Кратко расписал об основных методах для работы с телеграм-ботами на NodeJS: текстовые сообщения, видео, фото и аудио-сообщения, контакты, геолокация, платежная система и проверка подписки на канал.

User
Кратко расписал об основных методах для работы с телеграм-ботами на NodeJS: текстовые сообщения, видео, фото и аудио-сообщения, контакты, геолокация, платежная система и проверка подписки на канал.

Предыстория
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много "мусора".
Поиск по содержанию файла даёт не самый релевантный результат. Может выдать бесполезные результаты с содержанием содержащие ключевые слова, но не относящиеся к тому, что действительно необходимо найти.
Более того по содержанию можно искать только текстовые файлы.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт "девственный". Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню, есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты или там продаются.

Вообще, я люблю опенсорс - мой голосовой помощник Ирина тому подтверждение.
Тем не менее, в текстовых нейросетях пока опенсорс решений уровня GPT-4 нет - а пользоваться им при написании кода, честно говоря, правда полезно.
Если честно, меня несколько утомило решать вопросы доступа и оплаты OpenAI аккаунта, необходимого для доступа к GPT-4 и API (да, я провожу эксперименты, и API мне нужен).
Я бы с удовольствием поэкспериментировал и с другими сетями - например, Claude, о которой говорят гораздо меньше, но которая, по-видимому, не намного хуже (спойлер: я пробовал - по моему мнению, Claude 2 вполне на уровне GPT-4).
Постепенно реализовывая свои "хотелки", я создал сервис VseGPT.ru, который решает мои основные проблемы - предоставляет общий интерфейс в виде чата и OpenAI API к разным топовым нейросетям - ChatGPT, Claude, Google Palm и опенсорсным Llama 70b, 34b Code и пр.
Конечно, сервис я делал в основном под свои профессиональные потребности, так что давайте посмотрим, чего хотел я, и насколько это подойдёт вам:
Всем привет! Это моя первая публикация на хабре, поэтому буду благодарен за любую обратную связь, которая поможет мне писать ещё лучше.
В статье вас ждёт "сборка" очень простой связки из распознавания и синтеза речи, а также запросов в модель YandexGPT на Node.js. Наш телеграм бот будет получать голосовое сообщение, а затем распознавать его, скармливать в модель GPT и синтезировать полученный ответ в голосовое сообщение.
Хочется начать с небольшого предисловия. В ходе написания этого простейшего решения я потратил кучу времени на попытку интегрироваться с популярным OpenAI ChatGPT, но мои нервы вышли из чата (обход блокировки, HTTPS прокси и т.п.), поэтому я перешёл к Яндексу. Он встречает нас дружелюбной консолью, понятной документацией и грантом на тестирование. В целом, если гранта по каким-либо причинам нет, то мне на все тесты хватило 20 рублей.
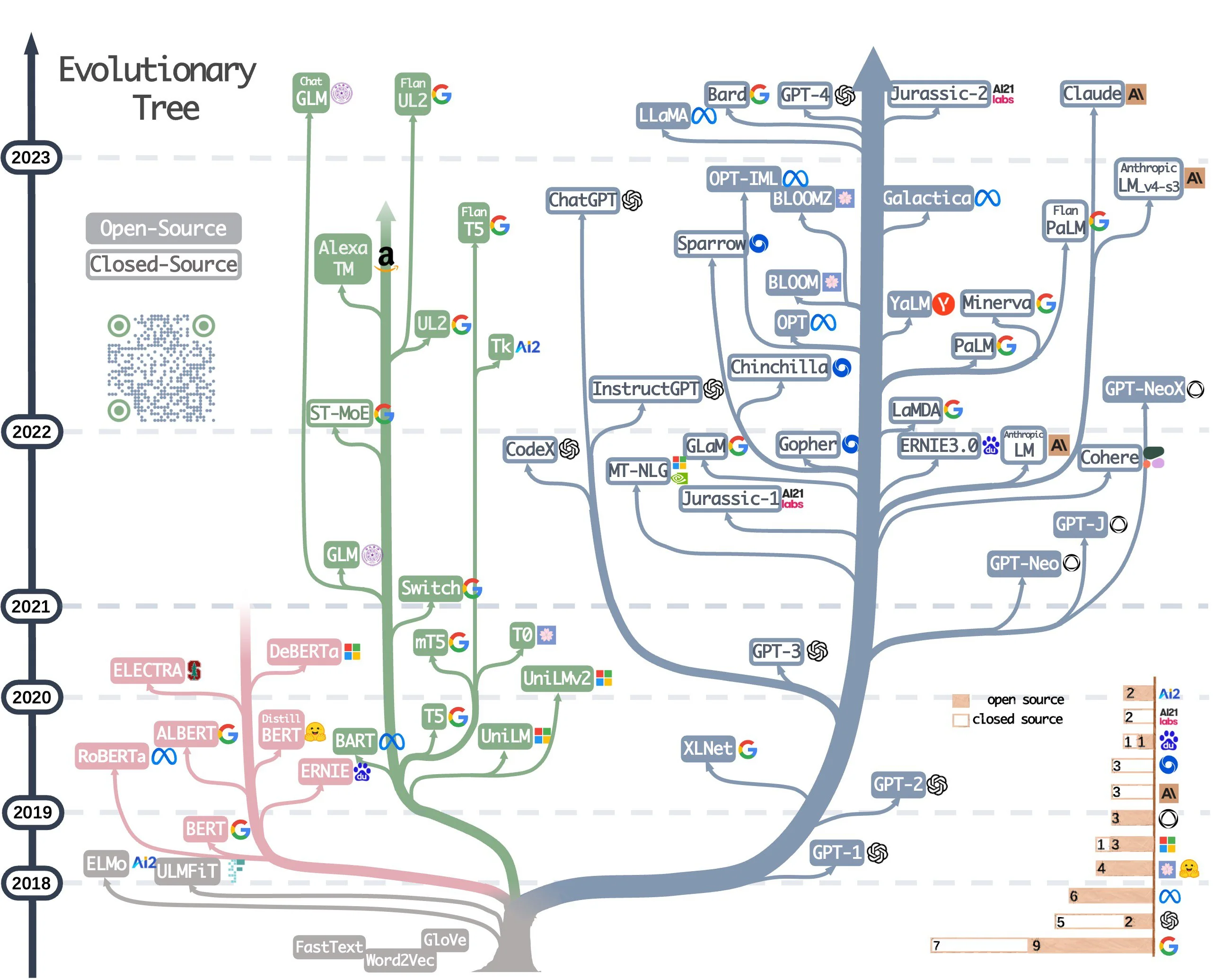
В прошлом году(2023) в мире больших языковых моделей(LLM) произошло много нового и нитересного. В новостях появились фразы о гонке искусственных интеллектов, а многие ведущие IT компании включились в эту гонку. Рассмотрим как все начиналось, кто сейчас занимает лидирующие позиции в гонке и когда роботы захватят мир.

Я понимаю, что пока, за использования VPN, аннонимайзеров и/или tor не применяют уголовные статьи, поэтому гораздо проще скачать какое нибудь приложение из магазина приложений и бесплатно воспользоваться им. Но где гарантия, что завтра они будут работать?
Я понимаю (программисты, сисадмины, DevOps'ы и т.д.) данный способ нельзя назвать уникальным, оптимальным и вообще, так лучше не делать, но согласитесь - это достаточно простой способ туннелирования трафика, который позволяет обойти (если не все), то огромное количество разнообразных сетевых блокировок.
О туннелирование через SSH на хабре написана не одна статья, но в виде инструкции, которую можно дать любому домохозяйкеину (ведь в рф запретили феминитивы) лично я не нашел. Поэтому добро пожаловать подкат.
Так же, этот способ - достаточно дешевый (меньше чашки кофе в день) и очень быстрый с точки зрения реализации (буквально 5 минут).
Интересно?

Всем привет! После прочтения постов про голосового ассистента и сервис Silero, мне стало интересно поиграться с offline распознаванием аудио в текст, а также с обратным преобразованием текст в аудио. И как все начинающие разработчики я сделал своего Telegram бота. Просто Telegram – это удобный и мобильный интерфейс для взаимодействия с чем угодно.
В своем пет-проекте я использовал aiogram, vosk, silero и ffmpeg.

В этой статье я расскажу как я смог бесплатно и без мощного железа дообучить LLaMA на диалогах с друзьями в ВК, чтобы сделать чат бота, который копирует наш стиль общения, оживляет разговор в чате и просто пишет странные и смешные вещи. В статье будет мало терминов, тут я простым языком расскажу как вы можете обучить большую языковую модель.

Цель данной статьи — простым языком объяснить ключевые технологии, необходимые для начала разработки приложений на основе LLM. Oна подойдёт как и разработчикам, так и специалистам по машинному обучению, у которых есть базовое понимание концепций и желание заглянуть поглубже. Также я прикрепил множество полезных ссылок для дальнейшего изучения. Давайте начинать!

Данная статья описывает работу пакета nnhelper, предназначенного для создания и использования нейронных сетей в программах на языке Go.
Если Вы уже знакомы с машинным обучением и используете его в своей работе, то эта статья и описанные в ней примеры могут показаться вам слишком простыми. Если Вы в начале пути и хотите познакомиться с этой темой или вам хотелось бы научиться использовать нейроматрицу в ваших программах на языке Go, то вы попали точно по адресу.
Go пакет nnhelper разработан для быстрого создания нейронной сети и использовании ее в приложениях, написанных на языке Go. Для использования nnhelper не потребуется ничего дополнительного, кроме Go. Пакет nnhelper является надстройкой над пакетом gonn. И это единственная внешняя зависимость.

В нашей прошлой статье про синтез речи мы дали много обещаний: убрать детские болячки, радикально ускорить синтез еще в 10 раз, добавить новые "фишечки", радикально улучшить качество.
Сейчас, вложив огромное количество работы, мы наконец готовы поделиться с сообществом своими успехами:
Это по-настоящему уникальное и прорывное достижение и мы не собираемся останавливаться. В ближайшее время мы добавим большое количество моделей на разных языках и напишем целый ряд публикаций на эту и смежные темы, а также продолжим делать наши модели лучше (например, еще в 2-5 раз быстрее).
Попробовать модель как обычно можно в нашем репозитории и в колабе.

В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами скрытую марковскую модель можно объяснить на примере.

Эта история началась в начале марта этого года. ChatGPT тогда был в самом расцвете. Мне в Telegram пришёл Саша Кукушкин, с которым мы знакомы довольно давно. Спросил, не занимаемся ли мы с Сашей Николичем языковыми моделями для русского языка, и как можно нам помочь.
И так вышло, что мы действительно занимались, я пытался собрать набор данных для обучения нормальной базовой модели, rulm, а Саша экспериментировал с существующими русскими базовыми моделями и кустарными инструктивными наборами данных.
После этого мы какое-то время продолжали какое-то время делать всё то же самое. Я потихоньку по инерции расширял rulm новыми наборами данных. Посчитав, что обучить базовую модель нам в ближайшее время не светит, мы решили сосредоточиться на дообучении на инструкциях и почти начали конвертировать то, что есть, в формат инструкций по аналогии с Flan. И тут меня угораздило внимательно перечитать статью.

Меня зовут Денис (tg: @chckdskeasfsd), и это история о том почему в опенсурсе нет TTS с нормальными ударениями и как я пытался это исправить.