Здравствуйте!
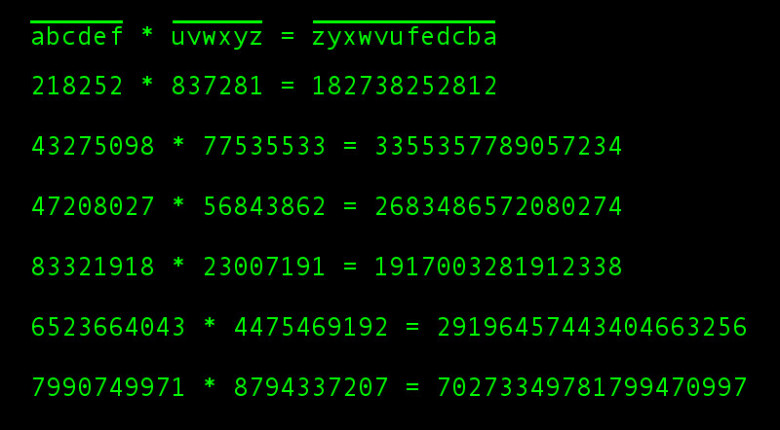
Расскажу о серии задач, которая случайно возникла в процессе решения другой задачи. Мне на глаза попалось равенство:
81 * 27 = 2187
– Интересно, – подумал я. – А бывают ли ещё такие числа, чтобы цифры слева и справа повторялись?

Визуализация данных и frontend в ИСИЭЗ НИУ ВШЭ
Здравствуйте!
Расскажу о серии задач, которая случайно возникла в процессе решения другой задачи. Мне на глаза попалось равенство:
81 * 27 = 2187
– Интересно, – подумал я. – А бывают ли ещё такие числа, чтобы цифры слева и справа повторялись?

Когда-то давно, году в 2013-м, на глаза мне попался следующий код:
>>>+[[-]>>[-]++>+>+++++++[<++++>>++<-]++>>+>+>+++++[>++>++++
++<<-]+>>>,<++[[>[->>]<[>>]<<-]<[<]<+>>[>]>[<+>-[[<+>-]>]<[[
[-]<]++<-[<+++++++++>[<->-]>>]>>]]<<]<]<[[<]>[[>]>>[>>]+[<<]
<[<]<+>>-]>[>]+[->>]<<<<[[<<]<[<]+<<[+>+<<-[>-->+<<-[>+<[>>+
<<-]]]>[<+>-]<]++>>-->[>]>>[>>]]<<[>>+<[[<]<]>[[<<]<[<]+[-<+
>>-[<<+>++>-[<->[<<+>>-]]]<[>+<-]>]>[>]>]>[>>]>>]<<[>>+>>+>>
]<<[->>>>>>>>]<<[>.>>>>>>>]<<[>->>>>>]<<[>,>>>]<<[>+>]<<[+<<
]<]
Это интерпретатор языка Brainfuck, написанный на самом Brainfuck. Ссылки на оригинал у меня не осталось, только код, так что автора я назвать не смогу.
Мне всегда было безумно интересно узнать, как он работает. И теперь я решил наконец-то это сделать!

ChatGPT генерирует разнообразный и привлекательный для человека текст. Но что делает текст «хорошим»? Это субъективно и зависит от контекста. Например, если вы попросите сочинить историю, нужен творческий подход. Если вы запрашиваете информацию, то хотите, чтобы она была правдивой. А если вы просите написать код, то ожидаете, что он будет исполняемым.
Вы наверняка слышали о том, что OpenAI привлекали сотрудников из Африки для помощи в разметке токсичности их ассистента. Менее известен факт найма реальных разработчиков, чтобы подготовить данные с пояснениями к коду на человечском языке.
Именно данные с фидбеком от людей позволили дообучить их языковую модель и сделать продукт таким «человечным».
Разберем алгоритм, который позволяет согласовать модель машинного обучения со сложными человеческими ценностями.

Прим. Wunder Fund: В статье описан относительно новый подход к ускорению обучения больших моделей. Сами мы его не применяем, но над скоростью обучения моделей работаем постоянно, и если вам интересна эта тема, будем рады с вами пообщаться)
Обучение крупномасштабных ИИ-моделей — это не так уж и просто. Помимо того, что для этого нужны серьёзные вычислительные мощности и ресурсы, задачи обучения очень больших моделей сопряжены с немалыми технологическими сложностями. Мы, в команде Facebook AI Research (FAIR), работаем над созданием инструментов и инфраструктурных решений, нацеленных на упрощение обучения больших моделей. Среди наших недавних проектов в этой области можно отметить модели с внутрислойным параллелизмом, модели с конвейерным параллелизмом, модели с шардингом состояния оптимизатора и данных, относящихся к вычислению градиента, архитектуру «смесь экспертов». Всё это — лишь часть нашей работы, направленной на то, чтобы сделать более эффективным обучение продвинутых ИИ-моделей для любого количества задач.
В этой статье рассмотрим "Алгоритм X" Кнута и его применение для решения судоку. Прелесть алгоритма в том, что судоку при этом решается быстро без программирования каких-то продвинутых техник решения.
Мы так привыкли к типам, что редко задаёмся вопросом, что же они такое на самом деле? А главное - почему возникла необходимость в их использовании? Этот поверхностный обзор сделан для того, чтобы продемонстрировать, как типы и другие связанные абстракции являются следствием из обобщения условий различных задач.

В минувшем году все только и говорили об ИИ и о том, как он может всё за вас сделать.
Мне нравится, когда кто-то или что-то работает за меня. Поэтому решил: попрошу-ка ChatGPT написать за меня новогодний пост:
«Эй, ChatGPT. А ты можешь реализовать большую языковую модель на SQL?»
«Нет, SQL не подходит для реализации больших языковых моделей. Язык SQL предназначен для выполнения запросов к данным, хранящимся в РСУБД и для управления этими запросами. Для реализации большой языковой модели требуются сложные алгоритмы, обширные датасеты, а зачастую — и фреймворки для глубокого обучения. SQL всеми этими возможностями не обладает.»
Что ж, лишний раз убеждаешься, что, если хочешь что‑то сделать хорошо – сделай это сам.
Давайте же воодушевимся этим оптимистическим планом и реализуем большую языковую модель на языке SQL.
X11 это тот механизм на чем работает весь графический интерфейс Unix подобных ОС.
Но мало кто знает как он работает на самом деле. Потому что с годами он оброс слоями и слоями библиотек, которые стремятся скрыть саму сущность протокола.
А протокол в своей сути прекрасен. Он лаконичен и почти совершенен.
В Интернете есть полная документация по протоколу. Но дело в том, что эта документация большая, написана не совсем ясным языком и, по сути, является просто спецификацией. Важные моменты никак не обозначены, а как использовать – тоже оставлено на фантазию читателя.
А все книги и статьи по использованию X11 описывают это через библиотеки прокладки типа XLib и XCB, и даже, что хуже, GTK или Qt.
Так что документацию приходится читать всю и самому выделять что важно, а что не очень. Придумывать сценарии использования и писать хотя бы короткие программы чтобы испробовать как все работает на самом деле.
Как бы то ни было, если кому-то интересно как все работает на самом деле, пожалуйста под кат.
 Источник
ИсточникChaturvedi: «Может, откроете исходный код проекта?»
Andrej Karpathy: «Даже не знаю. Он такой страшный, что мне стыдно».




«HAL 4000» – исполняемая программа для Windows размером ровно 4000 байт. Лучшая работа в номинации 4 kb intro фестиваля Chaos Constructions 2017, второе место в чартах портала pouet.net. «HAL 4000» попала в плейлист Best of Demoscene 2017 наряду с работами Farbrausch, Fairlight, Conspiracy, Alcatraz, Byterapers, обсуждалась на вебинаре анимационной студии, демонстрировалась на различных фестивалях.
Необычная история создания этой работы изложена ниже.


Аэропоника — перспективный и эффективный способ выращивания растений. Такие выводы я сделал, начитавшись статей. Я только что успешно вырастил на балконе клубнику и полон энтузиазма двигаться дальше. Я берусь за аэропонику. Кажется, что это не сложно, надо, всего лишь, вместо размещения растений в земле, разместить их в каких-нибудь ёмкостях и распылять раствор на корни. Это привело меня к эпопее с клубникой в контейнере (1, 2, 3) и ряду экспериментов с аэропоникой, о которых я ещё не писал. За это время у меня накопился некоторый багаж знаний относительно аэропоники, им я и буду делиться в этом посте.
С аэропоникой не всё так перспективно и радужно, как это часто рисуют в статьях. Я надеюсь, что этот пост немного приземлит начинающих энтузиастов и даст больше понимания решившим ввязаться в эту тему. Несмотря на сложности, я всё ещё верю, что когда-нибудь аэропоника займет прочное место в растениеводстве.

Разработчик веб-приложений и распределённых систем под псевдонимом chreke* убеждён: «малые языки», то есть специализированные языки, созданные для решения конкретных задач, являются будущим программирования. Это убеждение укрепилось в нём после прочтения статьи Габриэллы Гонсалес «Конец истории программирования» и просмотра лекции Алана Кея «Программирование и масштабирование».
Под катом автор объясняет, что подразумевает под «малыми языками», и почему они так важны.
*Обращаем ваше внимание, что позиция автора может не всегда совпадать с мнением МойОфис.

Бунтарём себя можно считать только тогда, когда люди на самом деле защищают противоположную вашей позицию. Я не согласен с одной из best practices, недавно представленной в Google Testing Blog . Обычно это очень хороший ресурс, ведь этот пост не случайно попал в мою читалку новостей!
Авторы представили две версии функции и спросили, какая из них более читаема.

Как разработчик TeaVM, компилятора байт-кода JVM в JavaScript и WebAssembly, я часто рекомендую пользователям, почему-то жаждущим сгенерировать WebAssembly, начать с JavaScript. Если честно, бэкэнд WebAssembly я очень давно не развиваю, не реализую в нём недостающих фич и не фикшу баги. Меня спрашивают: а почему так? Обычно, я просто игнорирую подобные вопросы, потому что в двух предложениях ответить на них невозможно, а для того, чтобы писать больше предложений, у меня нет времени. Обычно если я встречаю чьи‑то попытки объяснить, чем WebAssembly плох для реализации JVM (а так же, CLR, JavaScript и прочих динамических сред), то они сводятся к следующему: «Java (.NET, JavaScript, ваш вариант) — это управляемый язык со сборкой мусора и исключениями, так что приходится тащить с собой гигантский рантайм». Что же, на самом деле, ситуация несколько сложнее, а размер рантайма вовсе не такой страшный и не является основным источником бед.