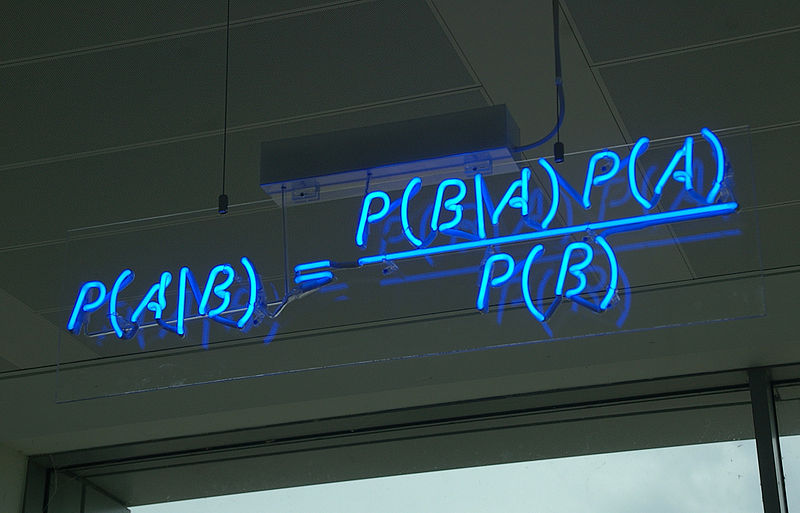Примечание переводчика 1. Я наткнулся на этот блог в одном из обзоров материалов по машинному обучению. Если вы хорошо разбираетесь в машинном обучении, то в этой статье вы не найдете для себя ничего интересного. Она достаточно поверхностная и затрагивает только основы. Если же вы, как и я, только начинаете интересоваться данной темой, то добро пожаловать под кат.
Примечание переводчика 2. Кода будет мало, а тот что есть написан на языке R, но не стоит отчаиваться, если вы его до сих пор никогда в глаза не видели. До этой статьи я тоже ничего о нем не знал, поэтому я специально отдельно написал «шпору» по языку, включив туда все, что вам встретится в статье. Если хотите сами разобраться, то начать рекомендую c маленького курса на CodeSchool. На хабре тоже есть интересная информация и полезные ссылки. И наконец вот тут есть большая шпаргалка.
Примечание переводчика 3. Статья из двух частей, однако самое интересное начинается только во второй части, поэтому я позволил себе объединить их в одну статью.

В этой серии статей, я собираюсь шаг за шагом построить и оттестировать простую стратегию управления активом, основанную на машинном обучении. Первая часть будет посвящена базовым концепциям машинного обучения и их применению к финансовым рынкам.
Машинное обучение является одним из наиболее многообещающих направлений в финансовой математике, в последние годы получившее репутацию изощренного и сложного инструмента. В действительности все не так сложно.
Примечание переводчика 2. Кода будет мало, а тот что есть написан на языке R, но не стоит отчаиваться, если вы его до сих пор никогда в глаза не видели. До этой статьи я тоже ничего о нем не знал, поэтому я специально отдельно написал «шпору» по языку, включив туда все, что вам встретится в статье. Если хотите сами разобраться, то начать рекомендую c маленького курса на CodeSchool. На хабре тоже есть интересная информация и полезные ссылки. И наконец вот тут есть большая шпаргалка.
Примечание переводчика 3. Статья из двух частей, однако самое интересное начинается только во второй части, поэтому я позволил себе объединить их в одну статью.
Часть 1
В этой серии статей, я собираюсь шаг за шагом построить и оттестировать простую стратегию управления активом, основанную на машинном обучении. Первая часть будет посвящена базовым концепциям машинного обучения и их применению к финансовым рынкам.
Машинное обучение является одним из наиболее многообещающих направлений в финансовой математике, в последние годы получившее репутацию изощренного и сложного инструмента. В действительности все не так сложно.