
Использование потенциальных полей в сценарии стратегии реального времени
8 мин
Перевод
Реализация поведения юнитов в RTS играх может стать серьезной проблемой. Компьютер, зачастую, контролирует огромное количество юнитов, в том числе и принадлежащих игроку, которые должны передвигаться в большом динамическом мире, попутно избегая столкновения друг с другом, выискивая врагов, защищая собственные базы и координируя атаки для истребления противника. Стратегии реального времени работают в реальном времени, что делает довольно сложным слежение за планированием действий и навигацией.
Этот урок описывает метод планирования течения игры и навигации юнитов, который использует многоагентные потенциальные поля. Он основан на работах под номерами [1, 2, 3]. (Смотри в конце статьи ссылки на используемые материалы)

Этот урок описывает метод планирования течения игры и навигации юнитов, который использует многоагентные потенциальные поля. Он основан на работах под номерами [1, 2, 3]. (Смотри в конце статьи ссылки на используемые материалы)
 Эта книга французского профессора Кристиана Кеннека об интерпретаторах Лиспа и Scheme довольно хорошо известна в англоязычном мире. Даже пару раз проскакивала на Хабре. Но в русскоязычном сообществе Scheme чаще всего ассоциируется со «Структурой и интерпретацией компьютерных программ» (aka SICP). Это хороший учебник для новичков, где целых две главы посвящены реализации используемого языка, однако в нём не рассматривается реализация довольно интересных и важных для Лиспа вещей вроде макросов, продолжений, динамических вычислений.
Эта книга французского профессора Кристиана Кеннека об интерпретаторах Лиспа и Scheme довольно хорошо известна в англоязычном мире. Даже пару раз проскакивала на Хабре. Но в русскоязычном сообществе Scheme чаще всего ассоциируется со «Структурой и интерпретацией компьютерных программ» (aka SICP). Это хороший учебник для новичков, где целых две главы посвящены реализации используемого языка, однако в нём не рассматривается реализация довольно интересных и важных для Лиспа вещей вроде макросов, продолжений, динамических вычислений.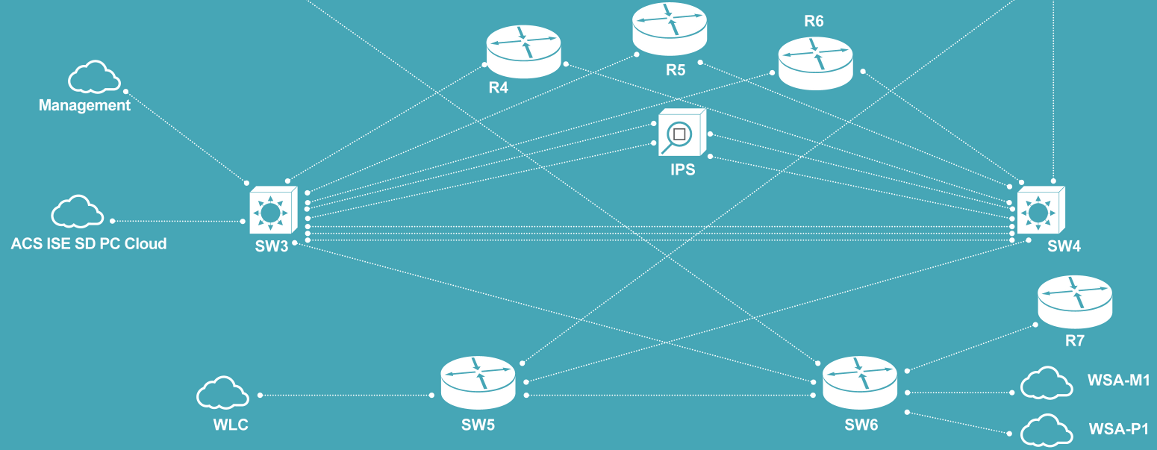






 По состоянию на июль прошлого года Apple продала более 800 миллионов устройств, работающих под управлением iOS. Более половины из них — различные модели iPhone. При таком количестве устройств в обращении совершенно не удивительно, что они часто становятся объектами компьютерно-технической экспертизы (forensics). На рынке представлены различные решения для автоматизации подобных экспертиз, но ценник на них зачастую делает их недоступными. Поэтому сегодня мы поговорим о том, как можно провести такую экспертизу с минимальными затратами или, проще говоря, используя бесплатные и/или open source инструменты.
По состоянию на июль прошлого года Apple продала более 800 миллионов устройств, работающих под управлением iOS. Более половины из них — различные модели iPhone. При таком количестве устройств в обращении совершенно не удивительно, что они часто становятся объектами компьютерно-технической экспертизы (forensics). На рынке представлены различные решения для автоматизации подобных экспертиз, но ценник на них зачастую делает их недоступными. Поэтому сегодня мы поговорим о том, как можно провести такую экспертизу с минимальными затратами или, проще говоря, используя бесплатные и/или open source инструменты.
 Данная статья является продолжением предыдущей,
Данная статья является продолжением предыдущей, 
 Когда-то, впервые встретив Unix, я был очарован логической стройностью и завершенностью системы. Несколько лет после этого я яростно изучал устройство ядра и системные вызовы, читая все что удавалось достать. Понемногу мое увлечение сошло на нет, нашлись более насущные дела и вот, начиная с какого-то времени, я стал обнаруживать то одну то другую фичу про которые я раньше не знал. Процесс естественный, однако слишком часто такие казусы обьединяет одно — отсутствие авторитетного источника документации. Часто ответ находится в виде третьего сверху комментария на stackoverflow, часто приходится сводить вместе два-три источника чтобы получить ответ на именно тот вопрос который задавал. Я хочу привести здесь небольшую коллекцию таких плохо документированных особенностей. Ни одна из них не нова, некоторые даже очень не новы, но на каждую я убил в свое время несколько часов и часто до сих пор не знаю систематического описания.
Когда-то, впервые встретив Unix, я был очарован логической стройностью и завершенностью системы. Несколько лет после этого я яростно изучал устройство ядра и системные вызовы, читая все что удавалось достать. Понемногу мое увлечение сошло на нет, нашлись более насущные дела и вот, начиная с какого-то времени, я стал обнаруживать то одну то другую фичу про которые я раньше не знал. Процесс естественный, однако слишком часто такие казусы обьединяет одно — отсутствие авторитетного источника документации. Часто ответ находится в виде третьего сверху комментария на stackoverflow, часто приходится сводить вместе два-три источника чтобы получить ответ на именно тот вопрос который задавал. Я хочу привести здесь небольшую коллекцию таких плохо документированных особенностей. Ни одна из них не нова, некоторые даже очень не новы, но на каждую я убил в свое время несколько часов и часто до сих пор не знаю систематического описания.