Потребовалось мне как то реализовать поддержку Webmoney API (Документация) в проекте. Библиотек на питоне я не нашел, поэтому решил написать свою.

User
Аппаратный сортировщик чисел на verilog-е
5 min
Tutorial
В этой моей статье, как и в предыдущей рассматривается цифровая схемотехника с точки зрения программиста. Но в этот раз будет разобрана «более алгоритмическая» задача сортировки чисел, с разбором verilog-кода. Рассматриваемое аппаратное решение позволяет отсортировать n чисел за время 2*n. На картинке ДПВ показан вывод на монитор от тестового проекта для ПЛИС, там каждой линии соответствует один тик сортировщика, сначала n тиков случайные числа записываются в сортировщик, затем n тиков выводятся числа отсортированные.

Выжимаем максимум из DDMS
6 min
DDMS (Dalvik Debug Monitor Server) — безумно полезный инструмент для отладки приложений, который идет в комплекте с Android SDK, о котором почему-то особо и не сказано на хабре, впрочем как и в примерах google он представлен в очень скромном виде. Я бы хотел раскрыть его возможности и показать на что он способен. Вкратце:
Об этих вещах будет рассказано в рамках данной статьи. И для справки, менее интересное, что довольно тривиально и о чем НЕ будет рассказано в рамках данной статьи:
- изучать информацию о работающих потоках;
- анализировать heap на количество свободной и занятой памяти;
- анализировать какие объекты чаще создаются, их размер и другое (Allocation tracker);
- находить проблемные участки кода, которые долго работают и требуют оптимизации (Method profiling). Это я советую знать всем.
Об этих вещах будет рассказано в рамках данной статьи. И для справки, менее интересное, что довольно тривиально и о чем НЕ будет рассказано в рамках данной статьи:
- работать с файловой системой эмулятора или устройства;
- находить информацию об ошибках (привет LogCat);
- эмулировать звонки/смс/местоположение;
- использовать инструмент Network Statistics.
Как сдать налоговую декларацию за 2013 год электронным способом за несколько дней (РФ)
6 min
Этот пост будет посвящен тому, как легко, просто и быстро (потеряв максимум тридцать минут в налоговой) заполнить и отправить налоговую декларацию за 2013 год (то есть ту, которую надо отправить до 30 апреля 2014 года). Попутно будет разобрано получение доступа в личный кабинет налогоплательщика и какие возможности это даёт. Фактически это пошаговая инструкция как всё это сделать за пару дней.
Всё вышесказанное относится к Налоговой Службе РФ.
Всё вышесказанное относится к Налоговой Службе РФ.
Что происходит в мозгах у нейронной сети и как им помочь
26 min
 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: Перцептрон Розенблатта — что забыто и придумано историей? и Какова роль первого «случайного» слоя в перцептроне Розенблатта. В них, как и во многих других очень много написано о том, что сети справляются с решением задач, и обобщают до некоторой степени свои знания. Но хотелось бы как-то визуализировать эти обобщения и процесс решения. Увидеть на практике, чему там научился перцептрон, и почувствовать, насколько успешно ему это удалось. Возможно, испытать горькую иронию относительно достижения человечества в области ИИ.
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: Перцептрон Розенблатта — что забыто и придумано историей? и Какова роль первого «случайного» слоя в перцептроне Розенблатта. В них, как и во многих других очень много написано о том, что сети справляются с решением задач, и обобщают до некоторой степени свои знания. Но хотелось бы как-то визуализировать эти обобщения и процесс решения. Увидеть на практике, чему там научился перцептрон, и почувствовать, насколько успешно ему это удалось. Возможно, испытать горькую иронию относительно достижения человечества в области ИИ.Языком у нас будет С#, только потому что я недавно решил его выучить. Я разобрал два наиболее простых примера: однослойный перцептрон Розенблатта, обучаемый коррекцией ошибки, и многослойный перцептрон Румельхарта, обучаемый методом обратного распространения ошибки. Для тех, кому, как и мне, стало интересно, чему они там на самом деле обучились, и насколько они на самом деле способны обобщать – добро пожаловать под кат.
ОСТОРОЖНО! Много картинок. Куски кода.
Часть 4.1 Возвращаем зрение. От очков до эксимерного лазера
9 min
Tutorial

Прошу прощения у всех, кто долго ждал этой статьи. Подготовка материалов требует массы времени и труда. В этой статье я постараюсь рассказать обо всех методиках коррекции зрения, которые существуют на данный момент. Мы пройдем путь от первых очков XIII века до современных лазерных методов коррекции, таких как femto-LASIK и ФРК.
Если вы не читали предыдущих статей цикла, то я бы рекомендовал ознакомиться в первую очередь со второй частью. Именно в ней подробно разбираются основные нарушения зрения и биологические основы нашего зрения. Объем статьи получился очень большой, поэтому я решил разбить ее на две части для облегчения восприятия.
Все, кому интересно — добро пожаловать под кат.
Остальные части
Часть 1. Unboxing VisuMax — фемто-лазера для коррекции зрения
Часть 2. Сколько мегабит/с можно пропустить через зрительный нерв и какое разрешение у сетчатки? Немного теории
Часть 3. Знакомьтесь — лазер по имени Amaris. Переезды и первое пробуждение VisuMax
Часть 4.2 Возвращаем зрение. От очков до эксимерного лазера
Всплывающие метки в формах на чистом CSS
3 min
Tutorial
Translation
Возможно, вам уже попадался на глаза этот приём. Это поле ввода, которое выглядит так, как будто в нем есть текстовая подсказка (placeholder), но при начале набора текста она не исчезает, а отодвигается в сторону. Мне нравится эта идея. Брэд Фрост написал очень хорошую статью об этом приёме, подробно рассмотрев все «за» и «против».
Большинство примеров использования этой техники полагаются на JavaScript. В один прекрасный день я зашёл на nest.com, увидел там этот приём и задумался: а нельзя ли реализовать то же самое без JavaScript? И вот что из этого вышло.
Вот так выглядит форма на nest.com:
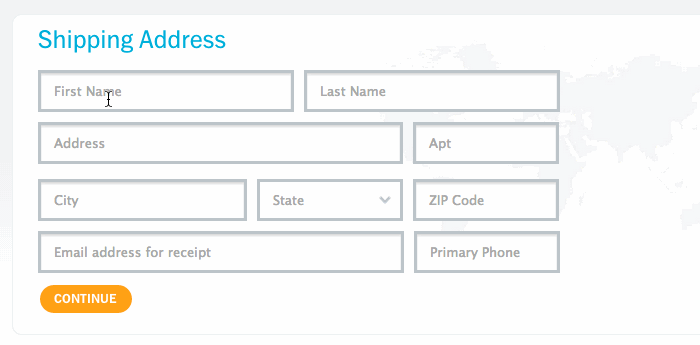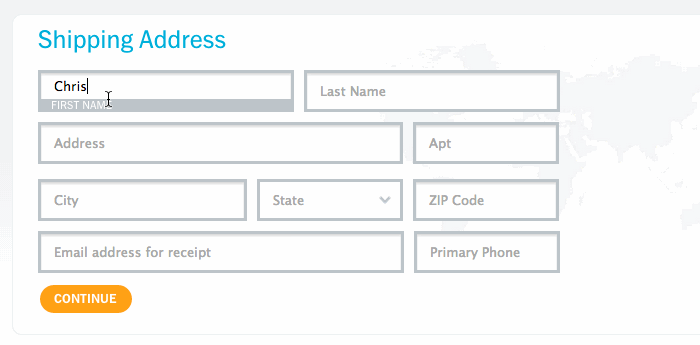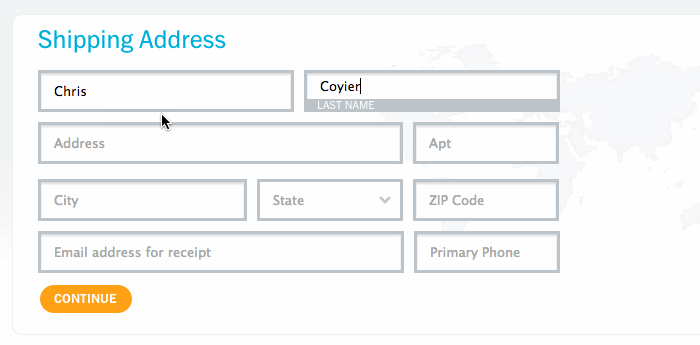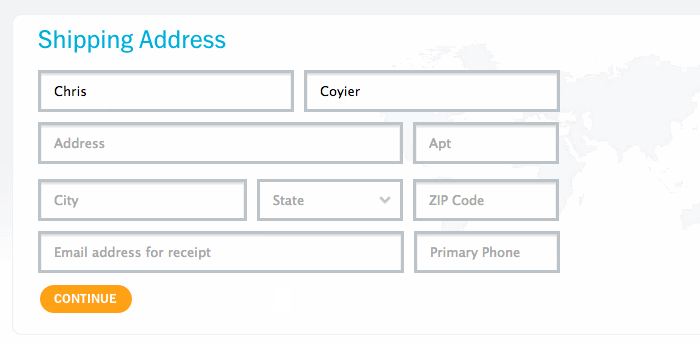
Большинство примеров использования этой техники полагаются на JavaScript. В один прекрасный день я зашёл на nest.com, увидел там этот приём и задумался: а нельзя ли реализовать то же самое без JavaScript? И вот что из этого вышло.
Вот так выглядит форма на nest.com:
TOX: Что произошло в проекте за полгода
4 min

Многие наверно уже слышали о Tox — это мессенджер, который должен заменить Skype, предоставив такой же функционал, как и его проприетарный аналог, подарив такие полезные вещи, как: Шифрования всего и вся, отсутствие слежки, отсутствие рекламы, децентрализация.
Может показаться, что проект
JPHP — Новый движок php для Java VM + JIT
6 min
Представляю вам свой open-source проект — JPHP. Это альтернативная реализация PHP для JavaVM с поддержкой JIT. Я начал проект в одиночку в октябре 2013 года и за 4 месяца реализовал компилятор php в байткод JVM. Язык поддерживается на уровне PHP 5.3, частично поддерживаются возможности PHP 5.4 и 5.5. По своей идеологии проект напоминает JRuby и Jython.
Я подготовил небольшую презентацию, которая расскажет о проекте и не отнимет у вас много времени:
Я подготовил небольшую презентацию, которая расскажет о проекте и не отнимет у вас много времени:
Крошечный Excel на чистом JavaScript (30 строк кода)
2 min
Translation
Особенности:
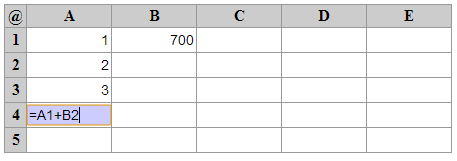
- Около 30 строк обычного JavaScript
- Использованные библиотеки: отсутствуют
- Синтаксис как в Excel (формулы начинаются с "=")
- Поддерживаются произвольные выражения(=A1+B2*C3)
- Обнаруживаются циклические ссылки
- Автоматическое сохранение в localStorage
StarCraft дизассемблировали и запустили на ARM
1 min
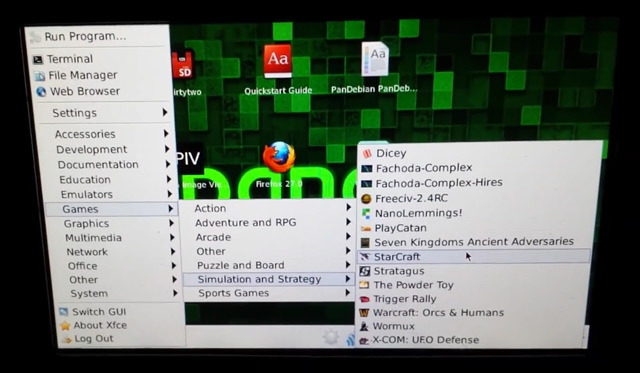
Один из участников проекта OpenPandora провёл реверс-инжиниринг игры StarCraft и портировал её на ARM-платформу. Ему удалось сделать это, несмотря на отсутствие исходного кода в открытом доступе.
В репозитории выложен перекомпилированный бинарник, для установки которого на игровую приставку «Пандора» нужно еще скопировать несколько файлов с ПК-версии игры.
Определение локальных IP-адресов через WebRTC
1 min
Через WebRTC можно получить список всех локальных (находящихся за NAT) интерфейсов в системе.
Пример кода на JavaScript jsfiddle.net/GZurr
Работает только в браузерах поддерживающих WebRTC, на текущий момент это Firefox и Chrome.
Это можно использовать для получения более точного фингерпринта браузера или, например, разоблачения персонажей, сидящих за VPN, чтобыВЫЧИСЛИТЬ ПО АЙПИ И НАБИТЬ Е**ЛЬНИК
Для удобства использования я изготовил js-сниффер, который можно вставить на страницу и удобно просматривать результат его работы: zhovner.com/jsdetector
Достаточно вставить на страницу код:
Где test нужно заменить на слово, по которому будет доступен результат работы сниффера: zhovner.com/jsdetector/test
Пример кода на JavaScript jsfiddle.net/GZurr
Работает только в браузерах поддерживающих WebRTC, на текущий момент это Firefox и Chrome.
Это можно использовать для получения более точного фингерпринта браузера или, например, разоблачения персонажей, сидящих за VPN, чтобы
Для удобства использования я изготовил js-сниффер, который можно вставить на страницу и удобно просматривать результат его работы: zhovner.com/jsdetector
Достаточно вставить на страницу код:
<script src="//zhovner.com/jsdetector.js?name=test"></script>Где test нужно заменить на слово, по которому будет доступен результат работы сниффера: zhovner.com/jsdetector/test
Еще один NAS своими руками, часть 1: из того, что было
23 min
Аннотация
В среднем, очередной пост про NAS появляется примерно раз в полгода, и рассказывает о том, как поставить систему по документации. Мы усложним задачу, привязав ее к реальному проекту и ограничив бюджет. Кроме того, мы еще и попытаемся подстелить себе соломку в тех местах, куда не еще не ступала нога молодого сисадмина, а также разрушим несколько отраслевых мифов.
Эта статья не для специалистов по серверному хранению данных, геймеров и прочих оверклокеров. На вас, коллеги, и так вся индустрия работает. Она для начинающих сисадминов, любителей UNIX-систем и энтузиастов свободного программного обеспечения. У всех накопилось старое железо. Всем нужно хранить большие объемы дома или в офисе. Но далеко не у всех есть простой доступ к серверным технологиям.
Я очень надеюсь, что вы найдете для себя несколько полезных идей и все-таки научитесь на чужих ошибках. Помните: система стоит не столько, сколько вы заплатили за железо, а сколько вы вложите потом времени и сил в тестирование и эксплуатацию.
Если не хотите читать — посмотрите ссылки и выводы в конце; может, и передумаете.
DISCLAIMER
Информация предоставляется AS-IS без какой-либо ответственности за ее использование кем-либо, где-либо и когда-либо. Все ненароком упомянутые торговые марки являются собственностью соответствующих владельцев. Некоторые из них в рекламе уже настолько не нуждаются, что я придумываю им шуточные названия.
Благодарности
Респект Андрею Александровичу Бахметьеву, инженеру и изобретателю. Я горд, что Андрей Александрович преподавал для меня в институте! Желаю ему всяческих успехов в его проектах!
Задача
Итак, есть малый бизнес-стартап, генерирующий порядка 50Гб файлов в неделю, с необходимостью их архивного хранения в течение нескольких лет. Файлы крупные (порядка 10-20 Мб каждый), обычными алгоритмами не сжимаемые. Начальный объем данных порядка 2Тб. Совсем старые данные можно хранить в оффлайне, подключая по требованию.
Нужно уложиться в весьма скромный начальный бюджет решения 500 евро (в ценах лета 2013) и двухнедельный срок на сборку и тестирование.
За эти деньги нужно построить систему, которая позволит работать с файлами небольшой группе в одной локальной сети с разных платформ (Windows, Mac OS). Требуется длительная работа без сисадмина на площадке, защита от отказов и базовые функции управления правами доступа.
Традиционные пути
Безусловно, можно купить сетевое хранилище: их делают NetApp, QNAP, Synology и другие игроки, и притом делают неплохо даже для малого бизнеса. Но наши 500 евро – это только начало разговора для пустой коробки, без самих дисков. Если у вас есть 1000-2000 евро, лучше купите готовое изделие, а мы попробуем максимально заплатить знаниями и минимально — временем и деньгами.
UPD (спойлер ред. 2 от 2014-03-08):
Если собираете из нового железа, а не из хлама
По совокупности этого поста и его комментариев, любезно предоставленных хаброкомьюнити, предлагаю следующий алгоритм для простой четырехдисковой системы:
- Если двойного размера самой ёмкой из доступных моделей диска не хватает для хранимых данных, прекращаем читать спойлер (пример: модель 4Тб, требуется хранить 7Тб данных, тогда продолжаем; если требуется хранить 10Тб, тогда прекращаем)
- Выбираем изделие из линейки MicroServer известного производителя серверов Харлампий-Панкрат; например, n36l, n40l, n54l, с четырьмя отсеками для дисков (главное, чтобы была поддержка ECC-памяти)
- Обязательно комплектуем наш сервер памятью с контролем четности (ECC) из расчета 1Гб на каждый 1Тб хранимых данных, но не менее 8Гб (по рекомендации FreeNAS для дисков до 4Тб получается как раз всего 8Гб)
- Если у нас нет ECC-памяти, немедленно прекращаем читать этот спойлер, читаем пост до конца
- Выбираем производителя дисков, используя актуальный обзор отказов; например, вот этот: http://habrahabr.ru/post/209894
- Выбираем недорогую линейку SATA дисков с обязательным наличием ERC, а зачем, читаем здесь: http://habrahabr.ru/post/92701
- Выбираем ёмкость дисков (2Тб, 3Тб или 4Тб) из расчета, что их будет четыре, и что доступной для данных будет только половина (вторая половина на избыточность RAID)
- Перед закупкой еще раз внимательно и досконально проверяем совместимость железа между собой, количества слотов, отсеков, планок и прочего, но для FreeNAS самое главное — поддержка всего железа актуальным ядром FreeBSD
- Выбираем хорошую загрузочную флэшку, прочитав продолжение данного поста (часть 2: хорошие воспоминания)
- Закупаем, вдыхаем ароматы нового железа, собираем, подключаем, запускаем; для ZFS обязательно выключаем все аппаратные RAID'ы
- Создаем том RAIDZ2 из четырех дисков, обязательно с двойной избыточностью (на размерах тома около 12Тб есть риск повстречать злобного URE, читайте о нем в этом посте; если мы не боимся URE и все-таки собираем RAIDZ на четырех дисках, проверяем размер физического сектора — на современных дисках он 4Кб, и в этом случае получится совершенно нелепый страйп 43Кб, который еще и просадит нам скорость массива: forums.servethehome.com/hard-drives-solid-state-drives/30-4k-green-5200-7200-questions.html)
- Соль, сахар, перец, jail'ы, шары, скрипты и тому подобную сметану добавляем по вкусу
А как же облачное хранение, спросите вы? На момент написания этой статьи популярные облачные хранилища для наших объемов выглядят дороже, чем хотелось бы. Например, стоимость хранения неограниченного объема данных 36 месяцев на известном сервисе Брось Бокс обойдется в пару тысяч долларов с лишним, хотя и выплачивать их можно постепенно. Конечно, есть сервисы вроде Amazon Glacier (благодарю А.М. за подсказку) или Ажурных Окон, но, во-первых, они тарифицируют не только хранение, но и обращение (как его априорно подсчитать?), а во-вторых не будем забывать, что бизнес сидит на Интернет-аплинке 10Мбит, и маневры терабайтами потребуют не только определенных усилий по управлению процессами, но и будут весьма утомительными для пользователей.
Обычно в таких случаях берут старый компьютер, докупают большие диски, ставят Linux (не обязательно, кто-то ухитряется и Windows 7), делают массив RAID5. Отлично. Всё работает хорошо примерно полгода-год, но одним солнечным утром сервер вдруг пропадает из сети без всякого предупреждения. Конечно, сисадмин уже давно работает в другой фирме (текучка кадров), резервной копии нет (объемы слишком велики), а новый сисадмин починить систему не может (при этом на чем свет стоит ругает старого сисадмина и диалект Linux YYY, ведь надо было использовать Linux ZZZ, тогда проблем бы точно не было). Все эти истории повторяются давно и одинаково, меняются только версии ОС и растут объемы данных.
Отраслевые мифы
Миф о RAID5
Самый распространенный миф, в который я и сам верил до недавнего времени – это то, что второго подряд отказа в массиве на практике не может быть по теории вероятности. А вот и может, да еще как! Смоделируем реальную ситуацию: сервер проработал пару лет, после чего в массиве отказывает диск. Пока ничего страшного, ставим новый диск, и что происходит? Ага, реконструкция массива, т.е. длительная максимальная нагрузка на уже порядком изношенные диски. В такой ситуации отказы очень даже возможны и происходят.
Но это не все. Есть еще заложенная производителем методическая вероятность ошибки чтения, которая при определенных обстоятельствах сейчас уже практически гарантирует, что RAID5 после отказа диска обратно не соберется.
Yacy — распределённый не цензурируемый поисковик: три года спустя
2 min

Yacy — это децентрализованная поисковая машина, которая позволяет осуществлять поиск информации в интернете без локальной или глобальной цензуры или любых других ограничений.
Первое и единственное упоминание о нем на хабре было 29 ноября 2011.
Но с того времени многое изменилось, давайте посмотрим на него еще раз.
DevDocs: вся документация разработчика в одном месте, с быстрым и удобным интерфейсом
1 min
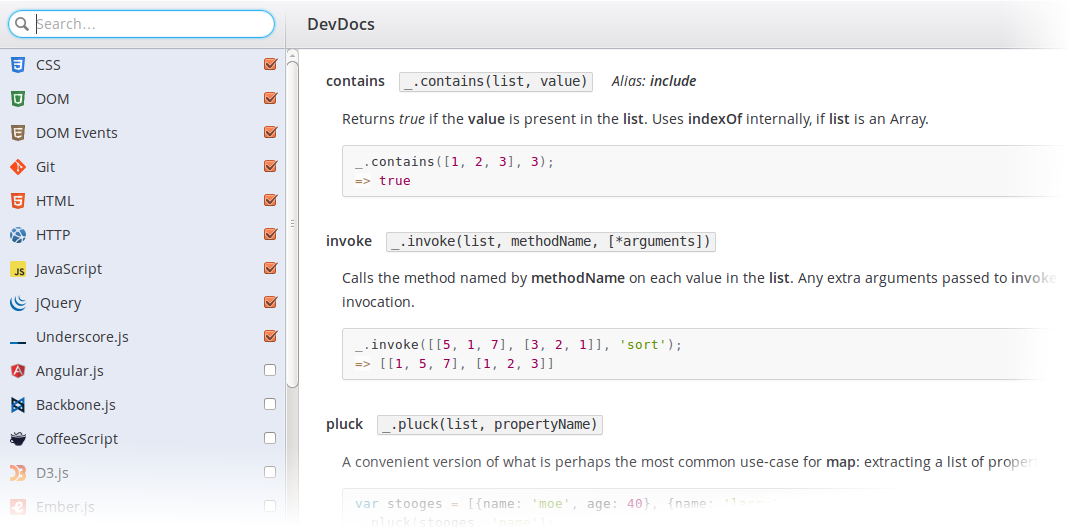
Сайт devdocs.io — проект французского программиста Тибо Курубля. Здесь собрана и упорядочена документация по наиболее популярным веб-технологиям, фреймворкам и API, и многим другим средствам разработки. DOM, HTML, JavaScript, jQuery, Node.js, PHP, Ruby, Python, Git, Angular, Backbone, CoffeScript, Less, Sass, Redis и много чего ещё… Всё оформлено в едином стиле, по всей базе документации работает поиск, в том числе нечёткий. Есть возможность выбрать только необходимые технологии, по которым надо искать. Вообще, интерфейс DevDocs радует — ничего лишнего, всё очень понятно и функционально, доступно множество клавиатурных сокращений.
Шпионские гаджеты от АНБ
10 min
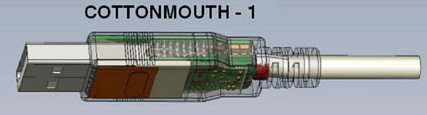 Среди документов опубликованных Эдвардом Сноуденом, бывшим сотрудником ЦРУ и Агентства национальной безопасности США, были обнаружены материалы описывающие некоторые детали технологий шпионажа используемых АНБ. Список программных и аппаратных средств оформлен в виде небольшого каталога. Всего сорок восемь страниц отмеченных грифами «Секретно» и «Совершенно секретно», на которых дано краткое описание той или иной технологии для слежки. Данный список не является исчерпывающим. Представлены техники связанные с получением скрытого доступа к вычислительной технике и сетям, а также способы и устройства радиоэлектронной разведки связанные с мобильной связью и оборудование для наблюдения. В этой статье я расскажу об этих методах шпионажа, далее будет четыре дюжины слайдов(осторожно, трафик).
Среди документов опубликованных Эдвардом Сноуденом, бывшим сотрудником ЦРУ и Агентства национальной безопасности США, были обнаружены материалы описывающие некоторые детали технологий шпионажа используемых АНБ. Список программных и аппаратных средств оформлен в виде небольшого каталога. Всего сорок восемь страниц отмеченных грифами «Секретно» и «Совершенно секретно», на которых дано краткое описание той или иной технологии для слежки. Данный список не является исчерпывающим. Представлены техники связанные с получением скрытого доступа к вычислительной технике и сетям, а также способы и устройства радиоэлектронной разведки связанные с мобильной связью и оборудование для наблюдения. В этой статье я расскажу об этих методах шпионажа, далее будет четыре дюжины слайдов(осторожно, трафик).Испытания boost::lockfree на скорость и задержку передачи сообщения
11 min
Не так давно в boost-1.53 появился целый новый раздел — lockfree реализующий неблокирующие очереди и стек.
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовалии втайне ими гордились. Естественно, у нас немедленно встал вопрос, переходить ли с самодельных библиотек на boost, и если переходить, то когда?
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовали
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
Какой HDD надёжнее? Статистика Backblaze по 27134 накопителям за 4 года работы
3 min
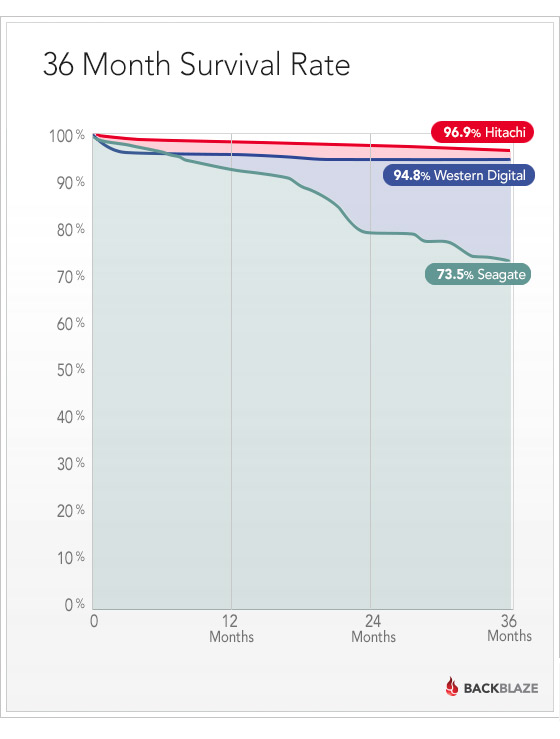
Компания Backblaze опубликовала в своём блоге статистику использования дисковых накопителей в своих серверах. Backblaze предоставляет услугу дешёвого облачного бэкапа. В основе их инфраструктуры — жёсткие диски потребительского класса. За четыре года работы компания собрала порядочную статистику по отказоустойчивости разных типов дисков, использовавшихся в их хранилище. Парк накопителей Backblaze состоит в основном из дисков Seagate и Hitachi — почти по 13 тысяч. Ещё 2838 дисков — производства Western Digital, и по несколько десятков накопителей Samsung и Toshiba. Таким образом, данные Backblaze позволяют сравнить работу дисков потребительского уровня трёх производителей — Seagate, WD и Hitachi — в условиях датацентра.
0day* уязвимости к Новому Году: ICQ, Ebay, Forbes, PayPal и AVG
3 min
В одном из своих постов я пытался привлечь внимание к проблеме безответственного отношения к уязвимостям различных веб-сайтов. Представьте себе ситуацию: вы энтузиаст в области информационной безопасности, нашли уязвимости на каком-нибудь известном сайте и пытаетесь о ней сообщить, но:
В подобных ситуациях чаще всего энтузиасты ждут, а потом раскрывают детали уязвимостей. Но проблема в том, что даже при огласке ничего не меняется. Этот пост — компиляция подобных огласок (т.е. вся представленная информация уже была доступна публично длительное время) об уязвимостях на крупных ресурсах, возможно, что-нибудь да и изменится.
- Невозможно найти никаких контактных данных для связи с тех. поддержкой сайта, а лучше именно со службой безопасности;
- Контактные данные есть, но вам никто не отвечает;
- Или чудо! Контактные данные есть, вам отвечают, но говорят что это не уязвимость и исправлять они ничего не будут.
В подобных ситуациях чаще всего энтузиасты ждут, а потом раскрывают детали уязвимостей. Но проблема в том, что даже при огласке ничего не меняется. Этот пост — компиляция подобных огласок (т.е. вся представленная информация уже была доступна публично длительное время) об уязвимостях на крупных ресурсах, возможно, что-нибудь да и изменится.
Производительный сетевой сервер на PHP
9 min
Вы пробовали заказать в Макдональдсе жаренного на орудийном шомполе поросенка с домашним вином и, на десерт, девушку рядом с вами за столиком, для приятной беседы во время трапезы? Даже не думали об этом?? Вот-вот — статья как раз об этом, о стереотипах программиста и лени, двигающей прогресс. А если серьезно — в статье мы напишем очень полезный многим высокопроизводительный сетевой сервер на PHP за пару часов. Я совершенно серьезно :-)
