Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман
Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
cmd1 | cmd2 | .... | cmdN
Например:
$ grep -i “error” ./log | wc -l
43
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Утилита strace позволяет отследить системные вызовы в процессе выполнения программы:
$ strace -f bash -c ‘/bin/echo foo | grep bar’
....
getpid() = 13726 <– PID основного процесса
...
pipe([3, 4]) <– системный вызов для создания конвеера
....
clone(....) = 13727 <– подпроцесс для первой команды конвеера (echo)
...
[pid 13727] execve("/bin/echo", ["/bin/echo", "foo"], [/* 61 vars */]
.....
[pid 13726] clone(....) = 13728 <– подпроцесс для второй команды (grep) создается так же основным процессом
...
[pid 13728] stat("/home/aikikode/bin/grep",
...
Видно, что для создания конвеера используется системный вызов pipe(), а также, что оба процесса выполняются параллельно в разных потоках.


 Статья посвящена работой с потоками данных в bash. Я постарался написать ее наиболее доступным и простым языком, чтобы было понятно даже новичкам в Linux.
Статья посвящена работой с потоками данных в bash. Я постарался написать ее наиболее доступным и простым языком, чтобы было понятно даже новичкам в Linux.
 Средства для резервного копирования информации можно разделить на несколько категорий:
Средства для резервного копирования информации можно разделить на несколько категорий:



 На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется
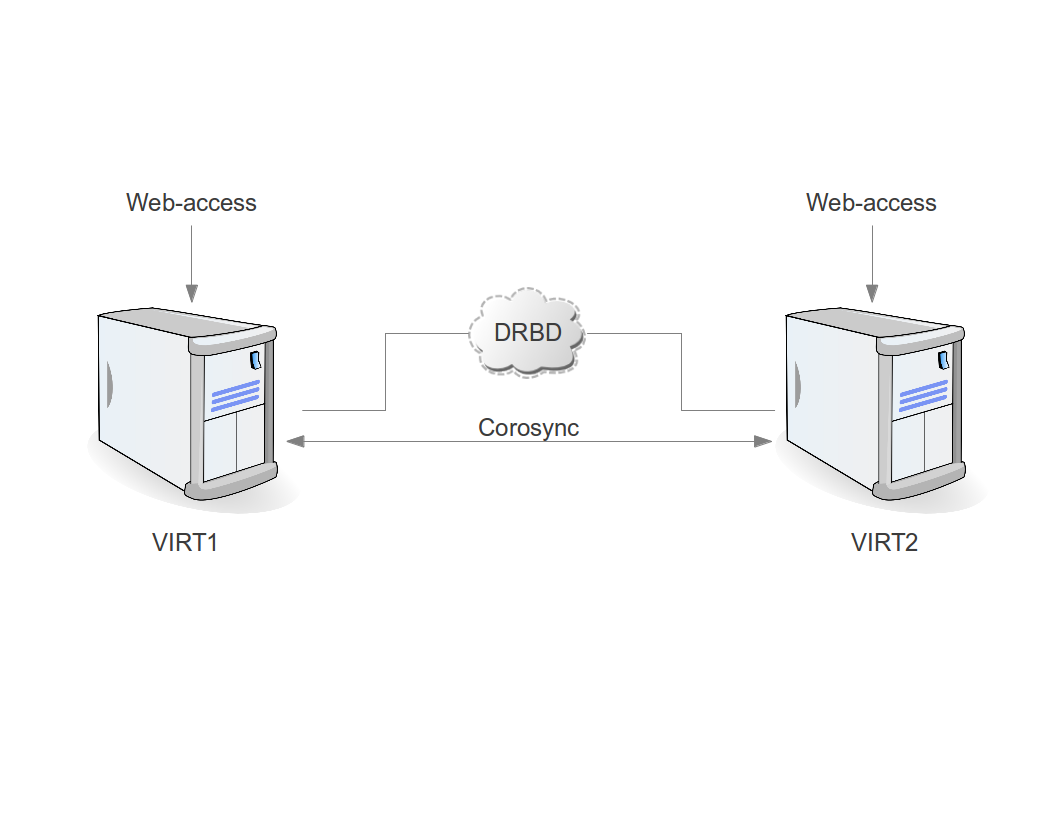
На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется  Друзья, не мне вам рассказывать, да и сами вы знаете о том, как делается backend для серверных/клиент-серверных приложений. В нашем идеальном мире всё начинается с проектирования архитектуры, затем выбираем площадку, затем прикидываем нужное количество машин, как виртуальных, так и нет. Затем происходит сам процесс поднятия архитектуры для разработки/тестирования. Всё готово? Ну поехали писать код, делать первый коммит, обновлять код на сервере из репозитория. Открыли консоль/браузер проверили и поехало. Пока всё просто, а что дальше?
Друзья, не мне вам рассказывать, да и сами вы знаете о том, как делается backend для серверных/клиент-серверных приложений. В нашем идеальном мире всё начинается с проектирования архитектуры, затем выбираем площадку, затем прикидываем нужное количество машин, как виртуальных, так и нет. Затем происходит сам процесс поднятия архитектуры для разработки/тестирования. Всё готово? Ну поехали писать код, делать первый коммит, обновлять код на сервере из репозитория. Открыли консоль/браузер проверили и поехало. Пока всё просто, а что дальше?