Привет, Хабр! Представляю вашему вниманию авторский перевод статьи Microservices – Combinatorial Explosion of Versions.
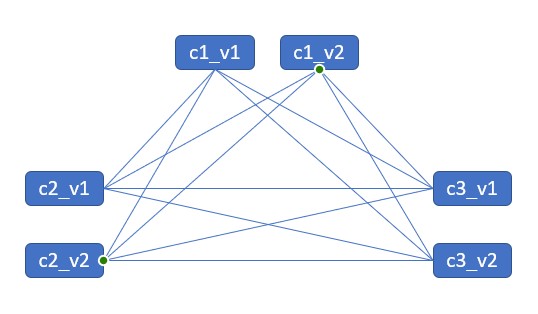
Во времена когда мир IT постепенно переходит на микросервисы и инструменты вроде Kubernetes, все более заметной становится лишь одна проблема. Эта проблема — комбинаторный взрыв версий микросервисов. Все же IT сообщество полагает, что сегодняшняя ситуация значительно лучше, чем «Dependency hell» предыдущего поколения технологий. Тем не менее, управление версиями микросервисов весьма сложная проблема. Одним из доказательств этому могут служить статьи вроде «Верните мне мой монолит».
Во времена когда мир IT постепенно переходит на микросервисы и инструменты вроде Kubernetes, все более заметной становится лишь одна проблема. Эта проблема — комбинаторный взрыв версий микросервисов. Все же IT сообщество полагает, что сегодняшняя ситуация значительно лучше, чем «Dependency hell» предыдущего поколения технологий. Тем не менее, управление версиями микросервисов весьма сложная проблема. Одним из доказательств этому могут служить статьи вроде «Верните мне мой монолит».