
What's up guys!
В этой статье мы поговорим о полезных материалах для изучения тем глубокого обучения и немного ИИ. В статье я дам список полезных ресурсов и немного советов по.

User
What's up guys!
В этой статье мы поговорим о полезных материалах для изучения тем глубокого обучения и немного ИИ. В статье я дам список полезных ресурсов и немного советов по.

Сегодня мы хотим поделиться новостью для всех, кто занимается анализом данных в области лингвистики и машинного обучения. Яндекс выкладывает в открытый доступ крупнейший русскоязычный датасет отзывов об организациях, опубликованных на Яндекс Картах. Это 500 тысяч отзывов со всей России с января по июль 2023 года.
В этой статье я расскажу, чем полезны отзывы с точки зрения исследований, в чём особенность этого датасета, а также покажу примеры задач, которые можно решать с его помощью.


Вам надоело каждый раз разбираться какую гипотезу, а главное с какими ограничениями к имеющимся данным проверяет бесчисленное множество статистических тестов?
Тогда бутстрап — это ваш выбор. Он не требует никаких параметрических предположений о данных или какой-либо нетривиальной математики и, вместе с тем, может быть применен к широкому спектру статистических оценок.


Мы школа онлайн-образования, которая уже три года делает курсы по Data Science и разработке. Одна из наших целей – собрать коммьюнити классных специалистов и делиться крутыми и неочевидными знаниями. Так был рождён Симулятор ML – место, в котором начинающие и опытные специалисты решают задачи разной сложности, разрабатывают проекты в командах, осваивают новые инструменты, развивают продуктовое мышление и постоянно растут в профессии.
А, как это свойственно коммьюнити, горящему идеей, студенты и авторы хотят делиться своими инсайтами и открытиями, которые дадут свежий взгляд на устоявшиеся практики. Сегодня хотим поделиться статьей автора Симулятора ML Богдана Печёнкина о том, как лучше использовать анализ ошибок для разработки ML систем.

Всем привет! Меня зовут Валентин Малых, я — руководитель направления NLP-исследований в MTS AI, вот уже 6 лет я читаю курс по NLP. Он проходит на платформе ODS, а также в нескольких университетах. Каждый раз при запуске курса студенты спрашивают меня про книги, которые можно почитать на тему обработки естественного языка. Поскольку я все время отвечаю одно и то же, появилась идея сделать пост про мой список книг, заодно описав их.

Книга, как раньше, так и сейчас, — основной источник знаний. Во всяком случае, один из основных. И читать книги нужно специалисту любого профиля и уровня. Сегодня публикуем относительно небольшую подборку книг для специалистов по машинному обучению. Как всегда, просьба: если у вас есть собственные предпочтения по книгам в этой отрасли, расскажите о них в комментариях.
В заметке приведены некоторые актуальные аналитические задачи индустрии. С помощью этого списка вы можете оценить насколько вам может быть интересно учиться на DA/DS, а если у вас уже есть опыт, то обогатите свои знания задачами из фармацевтической отрасли.

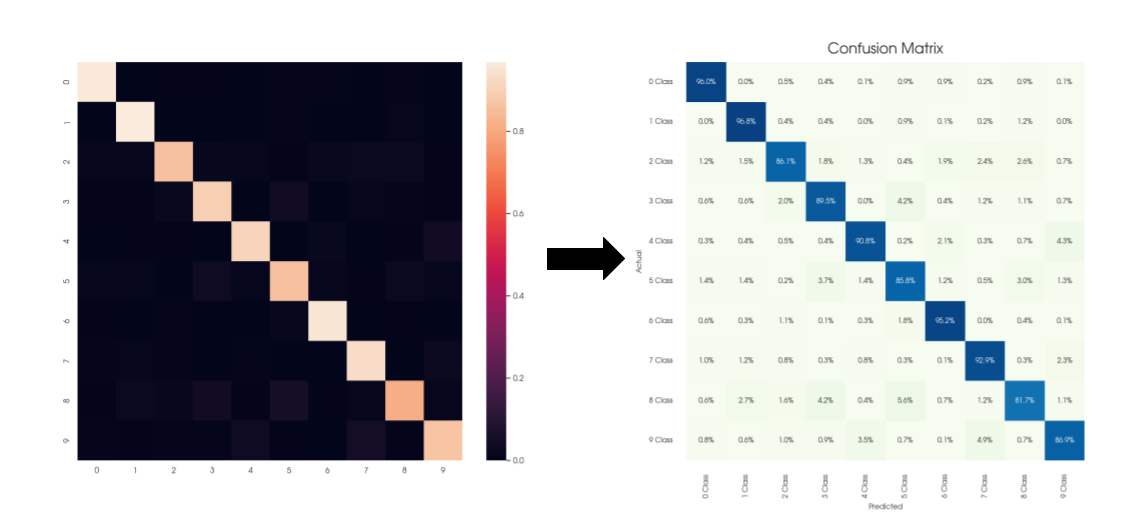
Понятие Confusion Matrix является довольно простым в объяснении, но при этом начинающим Data Scientist-специалистам бывает порой нелегко разобраться в отношениях True Positive (TP), False Positive (FP), True Negative (TN), False Negative (FN) — кирпичиками, составляющими данную матрицу. Цель этой статьи познакомить читателя с альтернативным представлением Матрицы Ошибок. Данный способ, по мнению автора, является наиболее наивным методом графического восприятия самой Матрицы Несоответствий, не предполагающий запоминания самой таблицы матрицы. Данный подход позволит легко ориентироваться в выводах, основанных на комбинации элементов Confusion Matrix, глубже понять проблему дисбаланса классов в задачах классификации.
Привет, Хабр!
Часто в работе аналитика данных при подготовке очередного отчета или презентации, колоссальное количество времени уходит именно на графическую составляющую подготовки.
Ведь все хотят сделать отчет не только информативным, но и визуально привлекательным.
В этой статье мы разберем основные шаги, которые помогут сделать ваши матрицы стильными и продающими ваши результаты, используя лишь две основные библиотеки визуализации в Python - Seaborn и Matplotlib.

В этой статье рассмотрим, как можно использовать глубокое обучение для оценки различных негативных окрасок текста, таких как угрозы, непристойности, оскорбления.

Уменьшение размерности данных широко используется в области машинного обучения и анализа данных. Его цель состоит в том, чтобы упростить обработку данных за счет уменьшения количества объектов в наборе данных при сохранении ключевой информации. Когда мы сталкиваемся с данными большой размерности, уменьшение размерности может помочь нам снизить вычислительную сложность, повысить производительность и результативность модели.

Всем привет. Меня зовут Артур. Готовясь к выступлению на внутреннем митапе по теме особенности алгоритмов у CatBoost и LightGBM, я понял, что не смог найти единого места, где были бы понятным языком рассказаны основные особенности того, что алгоритмически работает под капотом у CatBoost и LightGBM. Причём не формальные записи алгоритмов на псевдокоде, а понятные пошаговые инструкции. Так появилась эта статья.

Те, кто когда-нибудь хотел обучить своего диалогового чат-бота, непременно сталкивались с отсутствием датасетов с адекватными диалогами. В открытом доступе, в основном, лишь наборы комментариев с Пикабу и Хабра, парсинг телеграм чатов, и диалоги из литературы. Мягко говоря, всё это "не очень". Поэтому, мы решили использовать ChatGPT для генерации подходящего датасета.

Для Python существует более 137 тысяч библиотек с открытым исходным кодом, автоматизирующих работу в разных областях — от отдельных рутинных рабочих процессов в компаниях до создания сложных многофункциональных приложений. Одна из самых популярных областей применения «змеиного языка» — наука о данных, а также задачи, связанные с искусственным интеллектом и машинным обучением.
В этой обширной «шпаргалке» для начинающих AI/ML специалистов мы собрали опенсорсные библиотеки Python, сгруппированные по областям практического применения. Этот список с кратким описанием функций каждого инструмента будет полезен всем, кто постоянно работает с «Питоном» и ищет эффективные инструменты для решения возникающих задач.

Специалисты по анализу данных используют много разных инструментов, причем новые технологии (фреймворки, библиотеки и т.д.) появляются так часто, что у начинающих свой путь в отрасли постоянно возникает вопрос, что им нужно изучать в первую очередь. Здесь вы найдете обзор базовых инструментов. В следующих постах мы продолжим тему и расскажем об инструментах, не вошедших в этот обзор.
 Привет, Хаброжители!
Привет, Хаброжители!
Книги — отличный источник знаний, это верно. Но как определить, где хорошая книга, а где не очень? Лучше всего воспользоваться рекомендательными сервисами либо же посмотреть обзоры на разные книги в сети. Именно поэтому сегодня публикуем подборку хороших изданий, которые в основном пригодятся начинающим разработчикам. Но, вероятно, они будут полезны и более опытным коллегам. Под катом — самое интересное!

Привет, Хабр!
Меня зовут Серов Александр, я участник профессионального сообщества NTA.
Параллелизм играет важную роль в задачах Data Science, так как может значительно ускорить вычисления и обработку больших объемов данных. В посте расскажу о возможностях применения параллельных вычислений в интерактивной среде Jupyter notebook языка Python.