Космодром Вэньчан на о. Хайнань, запуск ракеты CZ-5 и будущее этого космодрома
Космическая польза от экватора
Для чего космодромы размещают у экватора? Вкратце: из-за облегчения достижения полезной нагрузкой (ПН) нужной скорости на орбите Земли. И для уменьшения затрат топлива при изменении/уменьшении наклонения орбиты, приведения наклонения орбиты к нулю (например для запуска на геостационарную орбиту). Подробнее здесь:
https://habr.com/ru/post/393423/
Радиус Земли составляет R=6378 км (на экваторе). Длина экватора Земли равна
За сутки любая точка на экваторе прокручивается именно на такое расстояние, один такой оборот нашей планеты занимает 24 часа. Поделив длину экватора в км на
24*3600 секунд мы получим, что линейная скорость земной поверхности на экваторе равна
0.464 км/cек, почти полкилометра в секунду. Это горизонтальная скорость никак не может подкинуть ракету вверх, но эта скорость добавляется к горизонтальной (точнее орбитальной) скорости верхней ступени и ПН, летящих уже не вверх, а параллельно земной поверхности на восток вдоль экватора (в конце вывода ПН на орбиту). Конечно это идеальный случай, характерный для вывода спутника на геостационарную орбиту (которая проходит точно над экватором), с космодрома тоже расположенного точно на экваторе. Для орбит с наклонением к плоскости экватора (чем дальше от экватора космодром, тем больше, увы, наклонение) не вся скорость, полученная при старте ракеты от вращения земной поверхности, будет полезной добавкой. Полезна только та часть скорости, которая параллельна плоскости будущей орбиты.
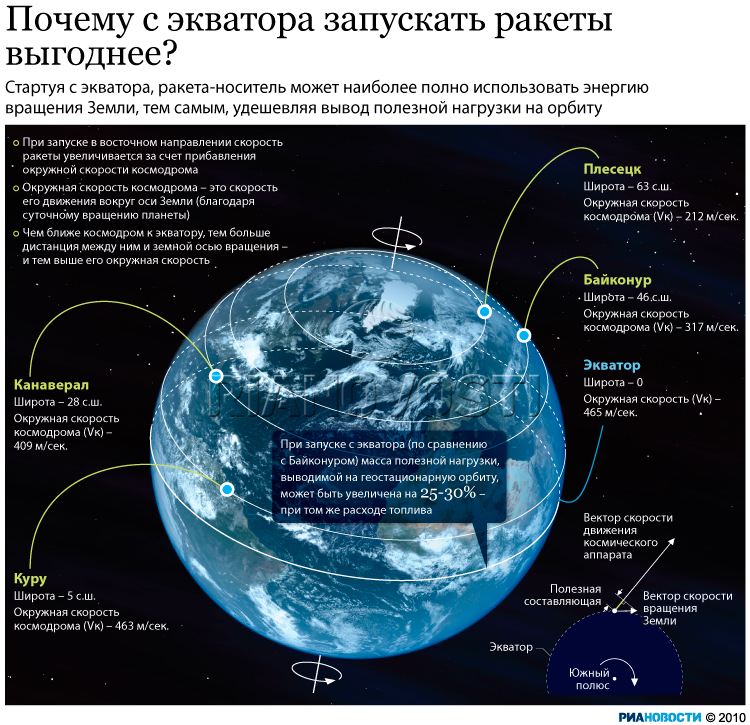
(иконографика основана на
данном оригинале)
На широте Байконура окружность Земли по данной широте имеет меньшую длину, но оборачивается точка на этой окружности за те же 24 часа, потому в районе Байконура линейная скорость равна 0.316 км/cек, а на широте Плесецка всего 0.212 км/сек — в два с лишним раза медленнее, чем на экваторе.