OSWE — сертификация продвинутого уровня, идеально подходящая для пентестера и аудитора веб-систем. Это был один из самых сложных экзаменов в моей жизни: куча оставленного здоровья, из 48 часов удалось поспать часов 12, и я даже не знал, что могу так “выражаться”. Состояние было “быстрее бы сдохнуть”. Но обо всем по порядку.

Alexander @speshuric
Пользователь
Визуальная теория информации (часть 2)
10 min
Translation
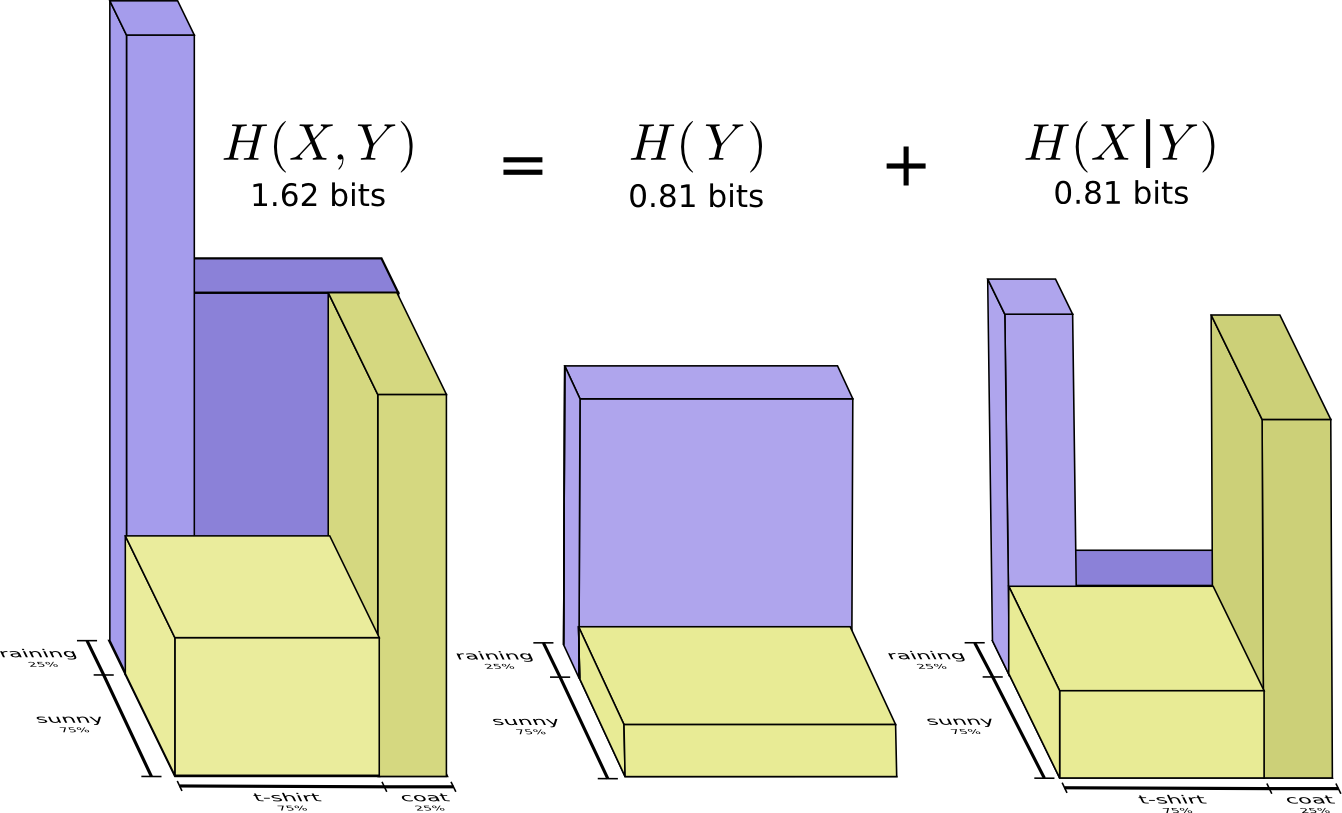
Вторая часть перевода лонгрида посвященного визуализации концепций из теории информации. Во второй части рассматриваются энтропия, перекрестная энтропия, дивергенция Кульбака-Лейблера, взаимная информация и дробные биты. Все концепции снабжены прекрасными визуальными объяснениями.
Для полноты восприятия, перед чтением второй части, рекомендую ознакомиться с первой.
Визуальная теория информации (часть 1)
12 min
Translation
Перевод интересного лонгрида посвященного визуализации концепций из теории информации. В первой части мы посмотрим как отобразить графически вероятностные распределения, их взаимодействие и условные вероятности. Далее разберемся с кодами фиксированной и переменной длины, посмотрим как строится оптимальный код и почему он такой. В качестве дополнения визуально разбирается статистический парадокс Симпсона.
Теория информации дает нам точный язык для описания многих вещей. Сколько во мне неопределенности? Как много знание ответа на вопрос А говорит мне об ответе на вопрос Б? Насколько похож один набор убеждений на другой? У меня были неформальные версии этих идей, когда я был маленьким ребенком, но теория информации кристаллизует их в точные, сильные идеи. Эти идеи имеют огромное разнообразие применений, от сжатия данных до квантовой физики, машинного обучения и обширных областей между ними.
К сожалению, теория информации может казаться пугающей. Я не думаю, что есть какая-то причина для этого. Фактически, многие ключевые идеи могут быть объяснены визуально!
Достижение максимальной производительности Быстрого Преобразования Фурье на основе управления данными
1 min
Recovery Mode
Статья поддерживается здесь:
[3] Caterpillar Implementation Based on Generated Code
// не вижу смысла писать на ресурсе а) с цензурой тэгов б) где каждый проходящий бот, набравший рейтинг галиматьей, сносит твой рейтинг и объяснение причины с него не требуется
[3] Caterpillar Implementation Based on Generated Code
// не вижу смысла писать на ресурсе а) с цензурой тэгов б) где каждый проходящий бот, набравший рейтинг галиматьей, сносит твой рейтинг и объяснение причины с него не требуется
Карта средств защиты ядра Linux
3 min
Защита ядра Linux — очень сложная предметная область. Она включает большое количество сложно взаимосвязанных понятий, и было бы полезным иметь ее графическое представление. Поэтому я разработал карту средств защиты ядра Linux. Вот легенда:

Быстрорастворимое проектирование
25 min
Люди учатся архитектуре по старым книжкам, которые писались для Java. Книжки хорошие, но дают решение задач того времени инструментами того времени. Время поменялось, C# уже больше похож на лайтовую Scala, чем Java, а новых хороших книжек мало.
В этой статье мы рассмотрим критерии хорошего кода и плохого кода, как и чем измерять. Увидим обзор типовых задач и подходов, разберем плюсы и минусы. В конце будут рекомендации и best practices по проектированию web-приложений.
Эта статья является расшифровкой моего доклада с конференции DotNext 2018 Moscow. Кроме текста, под катом есть видеозапись и ссылка на слайды.

В этой статье мы рассмотрим критерии хорошего кода и плохого кода, как и чем измерять. Увидим обзор типовых задач и подходов, разберем плюсы и минусы. В конце будут рекомендации и best practices по проектированию web-приложений.
Эта статья является расшифровкой моего доклада с конференции DotNext 2018 Moscow. Кроме текста, под катом есть видеозапись и ссылка на слайды.
«Библиотеки для C++ нередко похожи на русскую классику: страдает либо их автор, либо пользователь, либо архитектура». Автор этой цитаты, Сергей Садовников из «Лаборатории Касперского», прошел свой путь от страданий к просветлению и узнал о метапрограммировании в С++ нечто важное и нужное. Сочувствующих приглашаем в волшебный мир макросов, шаблонов, boost и прочих loki.
MVCC-2. Слои, файлы, страницы
12 min
В прошлый раз мы поговорили о согласованности данных, посмотрели на отличие между разными уровнями изоляции транзакций глазами пользователя и разобрались, почему это важно знать. Теперь мы начинаем изучать, как в PostgreSQL реализованы изоляция на основе снимков и механизм многоверсионности.
В этой статье мы посмотрим на то, как данные физически располагаются в файлах и страницах. Это уводит нас в сторону от темы изоляции, но такое отступление необходимо для понимания дальнейшего материала. Нам потребуется разобраться, как устроено хранение данных на низком уровне.
Если заглянуть внутрь таблиц и индексов, то окажется, что они устроены схожим образом. И то, и другое — объекты базы, которые содержат некоторые данные, состоящие из строк.
То, что таблица состоит из строк, не вызывает сомнений; для индекса это менее очевидно. Тем не менее, представьте B-дерево: оно состоит из узлов, которые содержат индексированные значения и ссылки на другие узлы или на табличные строки. Вот эти узлы и можно считать индексными строками — фактически, так оно и есть.
На самом деле есть еще некоторое количество объектов, устроенных похожим образом: последовательности (по сути однострочные таблицы), материализованные представления (по сути таблицы, помнящие запрос). А еще есть обычные представления, которые сами по себе не хранят данные, но во всех остальных смыслах похожи на таблицы.
Все эти объекты в PostgreSQL называются общим словом отношение (по-английски relation). Слово крайне неудачное, потому что это термин из реляционной теории. Можно провести параллель между отношением и таблицей (представлением), но уж никак не между отношением и индексом. Но так уж сложилось: дают о себе знать академические корни PostgreSQL. Мне думается, что сначала так называли именно таблицы и представления, а остальное наросло со временем.
В этой статье мы посмотрим на то, как данные физически располагаются в файлах и страницах. Это уводит нас в сторону от темы изоляции, но такое отступление необходимо для понимания дальнейшего материала. Нам потребуется разобраться, как устроено хранение данных на низком уровне.
Отношения (relations)
Если заглянуть внутрь таблиц и индексов, то окажется, что они устроены схожим образом. И то, и другое — объекты базы, которые содержат некоторые данные, состоящие из строк.
То, что таблица состоит из строк, не вызывает сомнений; для индекса это менее очевидно. Тем не менее, представьте B-дерево: оно состоит из узлов, которые содержат индексированные значения и ссылки на другие узлы или на табличные строки. Вот эти узлы и можно считать индексными строками — фактически, так оно и есть.
На самом деле есть еще некоторое количество объектов, устроенных похожим образом: последовательности (по сути однострочные таблицы), материализованные представления (по сути таблицы, помнящие запрос). А еще есть обычные представления, которые сами по себе не хранят данные, но во всех остальных смыслах похожи на таблицы.
Все эти объекты в PostgreSQL называются общим словом отношение (по-английски relation). Слово крайне неудачное, потому что это термин из реляционной теории. Можно провести параллель между отношением и таблицей (представлением), но уж никак не между отношением и индексом. Но так уж сложилось: дают о себе знать академические корни PostgreSQL. Мне думается, что сначала так называли именно таблицы и представления, а остальное наросло со временем.
MVCC-1. Изоляция
25 min
Привет, Хабр! Этой статьей я начинаю серию циклов (или цикл серий? в общем, задумка грандиозная) о внутреннем устройстве PostgreSQL.
Материал будет основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov. Смотреть видео не все любят (я точно не люблю), а читать слайды, пусть даже с комментариями, — совсем «не то».
Конечно, статьи не будут повторять содержание курсов один в один. Я буду говорить только о том, как все устроено, опуская собственно администрирование, зато постараюсь делать это более подробно и обстоятельно. И я верю в то, что такие знания полезны прикладному разработчику не меньше, чем администратору.
Ориентироваться я буду на тех, кто уже имеет определенный опыт использования PostgreSQL и хотя бы в общих чертах представляет себе, что к чему. Для совсем новичков текст будет тяжеловат. Например, я ни слова не скажу о том, как установить PostgreSQL и запустить psql.
Вещи, о которых пойдет речь, не сильно меняются от версии к версии, но использовать я буду текущий, 11-й «ванильный» PostgreSQL.
Первый цикл посвящен вопросам, связанным с изоляцией и многоверсионностью, и план его таков:
Ну, поехали.
Материал будет основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov. Смотреть видео не все любят (я точно не люблю), а читать слайды, пусть даже с комментариями, — совсем «не то».
Конечно, статьи не будут повторять содержание курсов один в один. Я буду говорить только о том, как все устроено, опуская собственно администрирование, зато постараюсь делать это более подробно и обстоятельно. И я верю в то, что такие знания полезны прикладному разработчику не меньше, чем администратору.
Ориентироваться я буду на тех, кто уже имеет определенный опыт использования PostgreSQL и хотя бы в общих чертах представляет себе, что к чему. Для совсем новичков текст будет тяжеловат. Например, я ни слова не скажу о том, как установить PostgreSQL и запустить psql.
Вещи, о которых пойдет речь, не сильно меняются от версии к версии, но использовать я буду текущий, 11-й «ванильный» PostgreSQL.
Первый цикл посвящен вопросам, связанным с изоляцией и многоверсионностью, и план его таков:
- Изоляция, как ее понимают стандарт и PostgreSQL (эта статья);
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Ну, поехали.
Прерывания от внешних устройств в системе x86. Часть 1. Эволюция контроллеров прерываний
8 min
Tutorial
В данной статье хотелось бы рассмотреть механизмы доставки прерываний от внешних устройств в системе x86 и попытаться ответить на вопросы:
Если на какой-то из этих вопросов вам интересно получить ответ или вы просто хотите ознакомиться с эволюцией контроллеров прерываний в системе x86, добро пожаловать под кат.
- что такое PIC и для чего он нужен?
- что такое APIC и для чего он нужен? Для чего нужны LAPIC и I/O APIC?
- в чём отличия APIC, xAPIC и x2APIC?
- что такое MSI? В чём отличия MSI и MSI-X?
- как с этим связаны таблицы $PIR, MPtable, ACPI?
Если на какой-то из этих вопросов вам интересно получить ответ или вы просто хотите ознакомиться с эволюцией контроллеров прерываний в системе x86, добро пожаловать под кат.
«Проще ответить, чем продолжать молчать» — большое интервью с отцом транзакционной памяти, Морисом Херлихи
33 min

Морис Херлихи — обладатель целых двух премий Дейкстры. Первая — за работу по «Wait-Free Synchronization» (Brown University) и вторая, более свежая, — «Transactional Memory: Architectural Support for Lock-Free Data Structures» (Virginia Tech University). Премию Дейкстры дают за работы, значимость и влияние которых были заметны на протяжении не менее десяти лет и, очевидно, Морис — один из самых известных специалистов в области. На данный момент он работает профессором в Брауновском университете и имеет множество достижений на целый абзац длиной. Сейчас он занимается исследованиями блокчейна в контексте классических распределенных вычислений.
Ранее Морис уже приезжал в Россию на SPTCC (видеозапись) и cделал отличную встречу сообщества Java-разработчиков JUG.ru в Питере (видеозапись).
Этот хабрапост — большое интервью с Морисом Херлихи. В нем обсуждаются следующие темы:
- Взаимодействие академической сферы и индустрии;
- Фундамент для исследований блокчейна;
- Откуда берутся прорывные идеи. Влияние популярности;
- PhD под руководством Барбары Лисков;
- Мир в ожидании многоядерности;
- Новому миру – новые проблемы. NVM, NUMA и взлом архитектуры;
- Компиляторы против процессоров, RISC vs CISC, shared memory vs message passing;
- Искусство написания хрупкого многопоточного кода;
- Как обучить студентов написанию сложного многопоточного кода;
- Новое издание книги «The Art of Multiprocessor Programming»;
- Как изобреталась транзакционная память;
- Почему стоит проводить исследования в области распределенных вычислений;
- Остановилось ли развитие алгоритмов, и как жить дальше;
- Работа в Брауновском Университете;
- Разница между исследованиями в университете и внутри корпорации;
- Hydra и SPTDC.
Сказ об опасном std::enable_shared_from_this, или антипаттерн «Зомби» — разбор полётов
31 min
В настоящей статье приводится разбор вариантов устранения антипаттерна «Зомби», описанного в первой части: Сказ об опасном std::enable_shared_from_this, или антипаттерн «Зомби».
Целостность данных в микросервисной архитектуре — как её обеспечить без распределенных транзакций и жёсткой связности
9 min
Всем привет. Как вы, возможно, знаете, раньше я все больше писал и рассказывал про хранилища, Vertica, хранилища больших данных и прочие аналитические вещи. Сейчас в область моей ответственности упали и все остальные базы, не только аналитические, но и OLTP (PostgreSQL), и NOSQL (MongoDB, Redis, Tarantool).
Эта ситуация позволила мне взглянуть на организацию, имеющую несколько баз данных, как на организацию, имеющую одну распределенную гетерогенную (разнородную) базу. Единую распределенную гетерогенную базу, состоящую из кучи PostgreSQL, Redis-ов и Монг… И, возможно, из одной-двух баз Vertica.
Работа этой единой распределенной базы порождает кучу интересных задач. Прежде всего, с точки зрения бизнеса важно, чтобы с данными, движущимися по такой базе, все было нормально. Я специально не использую здесь термин целостность, consistency, т.к. термин это сложный, и в разных нюансах рассмотрения СУБД (ACID и CAP теорема) он имеет разный смысл.
Ситуация с распределенной базой обостряется, если компания пытается перейти на микросервисную архитектуру. Под катом я рассказываю, как обеспечить целостность данных в микросервисной архитектуре без распределенных транзакций и жесткой связности. (А в самом конце объясняю, почему выбрал для статьи такую иллюстрацию).

Самодельный сборщик мусора для OpenJDK
22 min
Translation
Это перевод статьи Алексея Шипилёва «Do It Yourself (OpenJDK) Garbage Collector», публикуется с согласия автора. О любых опечатках и других багах сообщайте в личку — мы их поправим.
Процесс создания чего-нибудь в рантайме языка — весёлое упражнение. По крайней мере, создание первой версии! Построить надежную, высокопроизводительную, устойчивую к отказам подсистему рантайма, поведение которой можно удобно наблюдать и отлаживать — очень, очень сложная задача.
Сделать простой сборщик мусора — обманчиво просто, и вот этим хочется заняться в данной статье. Роман Кеннке на FOSDEM 2019 сделал доклад и демо под названием «Пишем GC за 20 минут», используя более раннюю версию этого патча. Несмотря на то, что реализованный там код многое демонстрирует и обильно откомментирован, ощущается необходимость в хорошем высокоуровневом описании происходящего — именно так и появилась эта статья.
Базовое понимание работы сборщиков мусора сильно поможет в понимании написанного здесь. В статье будут использоваться специфика и идеи в конкретной реализации HotSpot, но вводного курса по конструированию GC здесь не будет. Возьмите GC Handbook и прочитайте первые главы про самые основы GC, а ещё быстрей позволит начать статья на Википедии.

Замыкание обобщенного типа в Rust
5 min

В этой короткой статье я расскажу о паттерне в Rust, который позволяет "сохранять" для последующего использования тип, переданный через обобщенный метод. Этот паттерн встречается в исходниках Rust-библиотек и я тоже иногда его использую в своих проектах. Мне не удалось найти в сети публикаций о нем, поэтому я дал ему свое название: "Замыкание обобщенного типа", и в этой статье хочу рассказать, что он из себя представляет, зачем и как его можно использовать.
.NET Core на Linux, DevOps на коне
14 min
Мы развивали DevOps как могли. Нас было 8 человек, и Вася был самым крутым по Windows. Внезапно Вася ушел, а у меня появилась задача вывести новый проект, который поставляет Windows-разработка. Когда я высыпал на стол весь стек Windows-разработки, то понял, что ситуация — боль…
Так начинается история Александра Синчинова на DevOpsConf. Когда из компании ушел ведущий специалист по Windows, Александр задался вопросом, что теперь делать. Переходить на Linux, конечно же! Александр расскажет, как ему удалось создать прецедент и перевести часть Windows разработки на Linux на примере реализованного проекта на 100 000 конечных пользователей.

Как легко и непринужденно доставлять проект в RPM, используя TFS, Puppet, Linux .NET core? Как поддерживать версионирование БД проекта, если разработка впервые слышит слова Postgres и Flyway, а дедлайн послезавтра? Как интегрировать с Docker? Как мотивировать .NET-разработчиков отказаться от Windows и смузи в пользу Puppet и Linux? Как решать идеологические конфликты, если обслуживать Windows в продакшн нет ни сил, ни желания, ни ресурсов? Об этом, а также о Web Deploy, тестировании, CI, о практиках использования TFS в существующих проектах, и, конечно, о сломанных костылях и работающих решениях, в расшифровке доклада Александра.
Так начинается история Александра Синчинова на DevOpsConf. Когда из компании ушел ведущий специалист по Windows, Александр задался вопросом, что теперь делать. Переходить на Linux, конечно же! Александр расскажет, как ему удалось создать прецедент и перевести часть Windows разработки на Linux на примере реализованного проекта на 100 000 конечных пользователей.
Как легко и непринужденно доставлять проект в RPM, используя TFS, Puppet, Linux .NET core? Как поддерживать версионирование БД проекта, если разработка впервые слышит слова Postgres и Flyway, а дедлайн послезавтра? Как интегрировать с Docker? Как мотивировать .NET-разработчиков отказаться от Windows и смузи в пользу Puppet и Linux? Как решать идеологические конфликты, если обслуживать Windows в продакшн нет ни сил, ни желания, ни ресурсов? Об этом, а также о Web Deploy, тестировании, CI, о практиках использования TFS в существующих проектах, и, конечно, о сломанных костылях и работающих решениях, в расшифровке доклада Александра.
Десять лет программирования на Erlang
14 min
Translation
Я присоединился к сообществу Erlang около 10 лет назад, посреди первой фазы хайпа. Нам говорили, что Erlang — это будущее конкурентности и параллелизма. Реализовать их на этом языке проще и быстрее всего, и вы ещё получите бесплатную распределённость. В то время будущее казалось невероятным. Виртуальная машина недавно получила поддержку SMP, но чтобы действительно использовать все процессоры, приходилось запускать на одном компьютере несколько виртуальных машин.
Я хочу поразмышлять о прошедшем десятилетии. В этой статье я расскажу о фазах хайпа в отношении Erlang, о лестнице идей в языке и о её возможном влиянии на распространение языка, о том, через какие перемены я прошёл за эти 10 лет. И в заключение поделюсь своими мыслями о том, что Erlang ещё предстоит привнести в сообщество программистов в целом.
Пишем на Rust + CUDA C
6 min
Tutorial
Всем привет!
В данном руководстве хочу рассказать как подружить CUDA C/С++ и Rust. И в качестве примера напишем небольшую программу на Rust для вычисления скалярного произведения векторов, вычисление скалярного произведения будет производиться на GPU с использованием CUDA C.
Кому интересно под кат!
От High Ceph Latency к Kernel Patch с помощью eBPF/BCC
9 min

В Linux есть большое количество инструментов для отладки ядра и приложений. Большинство из них негативно сказываются на производительности приложений и не могут быть использованы в продакшене.
Логи не нужны?
10 min
Разработка сильно изменилась за последние годы. Вместо монолитных приложений пришли микросервисы и функции. Базы данных из универсальных промышленных монстров переродились в узконаправленные. Docker изменил взгляд на деплой. Но изменилось ли наше представление о логах?
Одна из больших проблем в Яндекс.Вертикалях были логи — 18 ТБ в день и 250 000 логов в секунду, все пишется в файлы. Логи разнородные, потому что много языков: Scala, Java, Python, Go. Потом их собирает Fluent Bit, пишет в Kafka, на одной железной машине работают обработчики, собирают из Kafka и пишут всё на диск. При этом это уже вторая версия логов.

Как следствие, возникает проблема долгого поиска. По этим логам поиск идет с помощью grep. На некоторых сервисах grep может достигать часов. Если у вас есть проблемы в продакшн, вы не будете часами искать свои логи. Чтобы решить проблему, в Яндекс решили написать свой велосипед доставки логов для поиска. Что из этого получилось, расскажет Алексей Данилов (danevge) — разработчик команды инфраструктуры в Яндекс.Вертикалях. Разрабатывает, пишет и поддерживает проекты auto.ru и Яндекс.Недвижимость.
Дисклеймер. Статья рассказывает о современной разработке и подходит для микросервисной архитектуры. Здесь представлены различные продукты — это инструменты, которые используют в Яндекс.Вертикалях. Под другие условия возможны аналоги удачнее, но они выполняют практически те же функции.
Одна из больших проблем в Яндекс.Вертикалях были логи — 18 ТБ в день и 250 000 логов в секунду, все пишется в файлы. Логи разнородные, потому что много языков: Scala, Java, Python, Go. Потом их собирает Fluent Bit, пишет в Kafka, на одной железной машине работают обработчики, собирают из Kafka и пишут всё на диск. При этом это уже вторая версия логов.
Как следствие, возникает проблема долгого поиска. По этим логам поиск идет с помощью grep. На некоторых сервисах grep может достигать часов. Если у вас есть проблемы в продакшн, вы не будете часами искать свои логи. Чтобы решить проблему, в Яндекс решили написать свой велосипед доставки логов для поиска. Что из этого получилось, расскажет Алексей Данилов (danevge) — разработчик команды инфраструктуры в Яндекс.Вертикалях. Разрабатывает, пишет и поддерживает проекты auto.ru и Яндекс.Недвижимость.
Дисклеймер. Статья рассказывает о современной разработке и подходит для микросервисной архитектуры. Здесь представлены различные продукты — это инструменты, которые используют в Яндекс.Вертикалях. Под другие условия возможны аналоги удачнее, но они выполняют практически те же функции.