Всем привет!
Меня зовут Лидия, я тимлид небольшой DataScience-команды в QIWI.
Мы с ребятами довольно часто сталкиваемся с задачей исследования потребностей клиентов, и в этом посте мне бы хотелось поделиться мыслями о том, как начать тему с сегментацией и какие подходы могут помочь разобраться в море неразмеченных данных.
Кого сейчас удивишь персонализацией? Отсутствие персональных предложений в продукте или сервисе уже кажется моветоном, и мы ждем те самые, отобранные только для нас, сливки везде – от ленты в Instagram до личного тарифного плана.
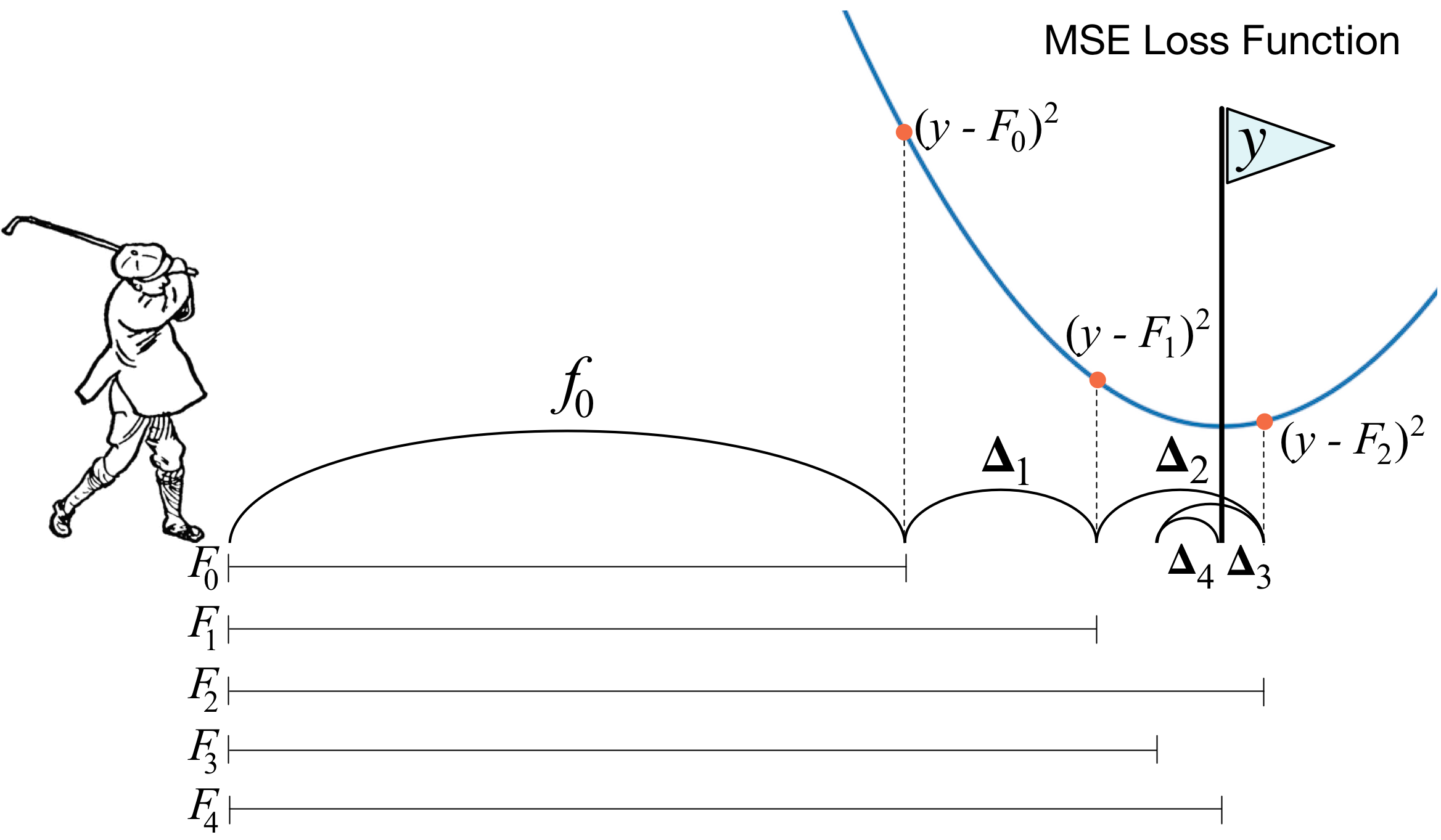
Однако, откуда берется тот самый контент или предложение? Если вы впервые погружаетесь в темные воды машинного обучения, то наверняка столкнетесь с вопросом – с чего начать и как выявить те самые интересы клиента. Чаще всего при наличии большой базы пользователей и отсутствии знаний об оных возникает желание пойти по двум популярным путям:
1. Разметить вручную выборку пользователей и обучить на ней модель, которая позволит определять принадлежность к этому классу или классам – в случае мультиклассового таргета.
Вариант неплохой, но на начальном этапе может заманить в ловушку – ведь мы еще не знаем, какие в принципе сегменты у нас есть и насколько они будут полезны для продвижения новых продуктовых фич, коммуникаций и прочего. Не говоря уже о том, что ручная разметка клиентов – дело достаточно затратное и иногда непростое, ведь чем больше у вас сервисов, тем большее количество данных нужно просмотреть для понимания, чем живет и дышит этот клиент. Большая вероятность, что получится нечто такое:
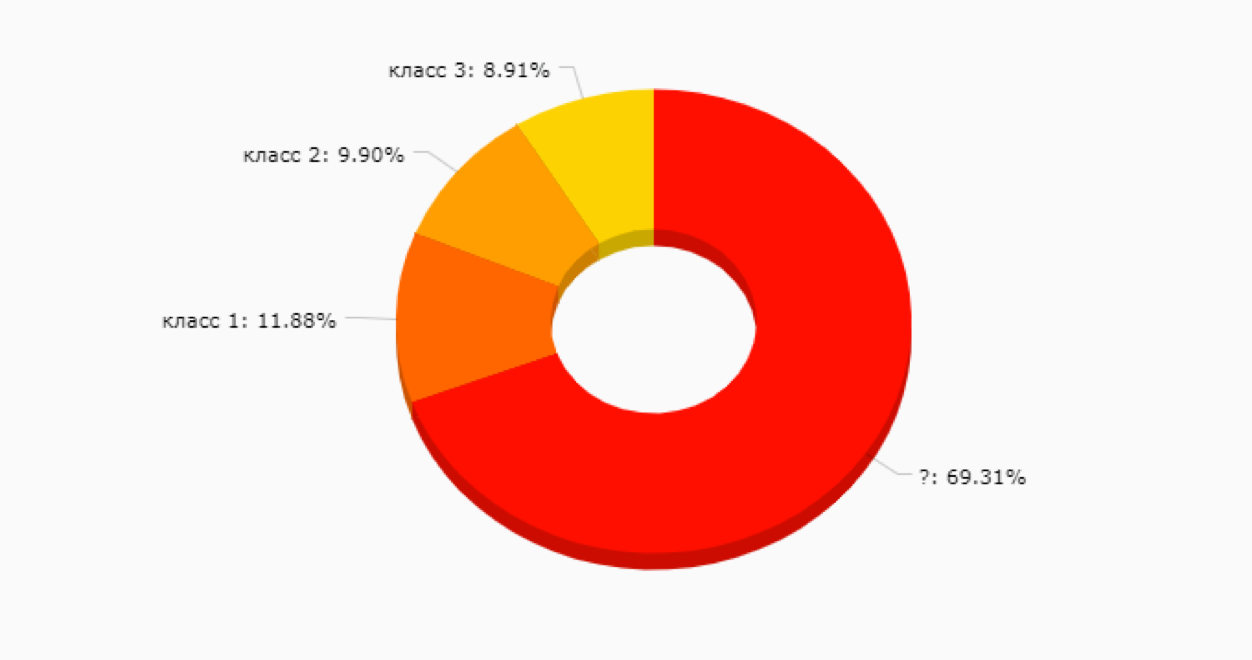 2.
2. Обжегшись на варианте #1, часто выбирают вариант
unsupervised-анализа без обучающей выборки.