
Более 50 лет назад автор популярных статей о математике в журнале Scientific American Мартин Гарднер предложил читателям задачу: «Можете ли вы разместить семь сигарет таким образом, чтобы каждая из них соприкасалась со всеми остальными?»

User
== эквивалентны (как, например, здесь). Часто при этом оговаривается, что приведённые в таблице данные не очень хорошо организованы.

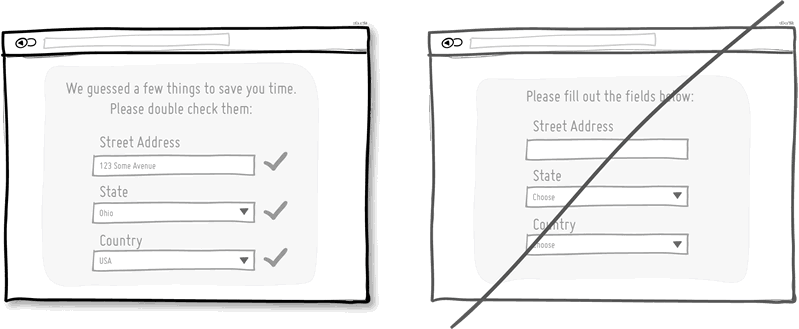

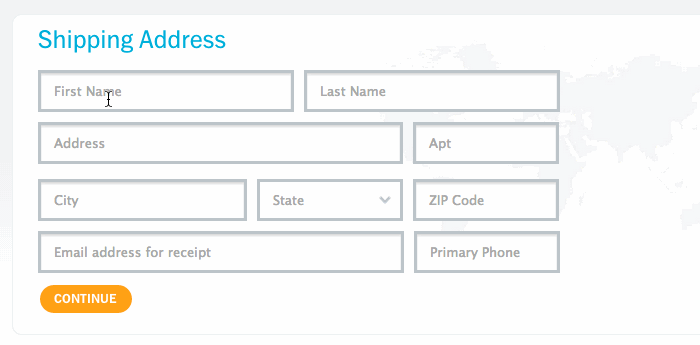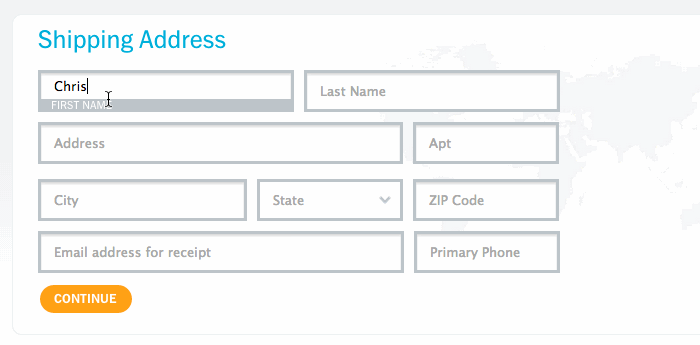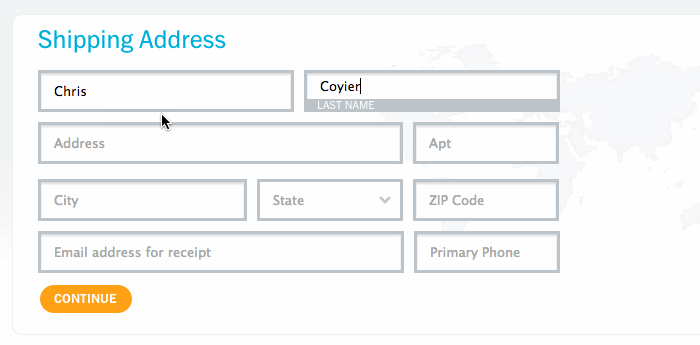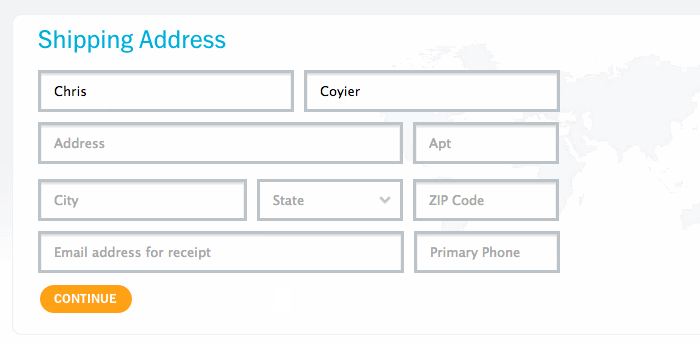


<input required="required" class="email-input" type="email" />
<input required="required" class="password-input" type="password"/>
<div class="go">Login</div>
.email-input:valid ~ .password-input:valid ~ .go {
//стили для активной кнопки Login
}
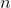 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 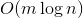 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 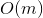 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
 Да, зима — не лучшее время для статьи о молниях. Но время близится! Сезон дождей и гроз всего через каких-то 4-5 месяцев, а работы – хоть отбавляй.
Да, зима — не лучшее время для статьи о молниях. Но время близится! Сезон дождей и гроз всего через каких-то 4-5 месяцев, а работы – хоть отбавляй. Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.
Основная цель, преследуемая в ходе разработки физической модели данных, — создание таких объектов для конкретной платформы/СУБД, которые позволят достигнуть максимальной производительности запросов/приложений, создающих основную нагрузку, сведя при этом дополнительные затраты, такие как необходимость поддерживать дополнительные индексы, выполнять материализацию производных данных и т. п., к минимуму.