Думаю, всем читателям хабра хорошо известны алгоритмы энтропийного сжатия с использованием префиксных кодов (алгоритмы Шеннона-Фано, Хаффмана и др.). Особенностью этих алгоритмов является тот факт, что длина кода определённого символа зависит от частоты этого символа в закодированном сообщении. Соответственно при декодировании сообщения необходимо иметь таблицу частот. Данная статья посвящена рассмотрению малоизученной, но важной задачи – передаче частот исходного алфавита.
В начале давайте рассмотрим основную идею, лежащую в основе энтропийного префиксного кодирования. Пусть у нас есть сообщение, состоящее из букв русского алфавита, например, «КУКУШКАКУКУШОНКУКУПИЛАКАПЮШОН». В этом сообщении встречается всего десять различных символов {К, У, Ш, А, О, Н, П, И, Л, Ю}, а значит, каждый символ может быть закодирован с использованием четырёх бит.
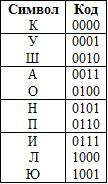
То есть всё сообщение при таком наивном блочном кодировании будет занимать 116 бит.
Но символам можно поставить в соответствие другие коды, например:
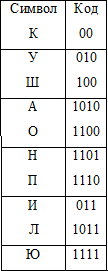
При использовании кодов из Табл. 2 длина сообщения составит уже 90 бит, а выигрыш более 22%. Внимательный читатель заметит, что коды в Табл. 1 имеют постоянную длину, а значит могут быть легко декодированы. В Табл. 2 коды имеют переменную длину, но они обладают другим важным свойством – префиксностью. Свойство префиксности означает, что ни один код не является началом никакого другого кода. Для любого префиксного кода может быть построено соответствующее дерево, с помощью которого можно однозначно выполнить декодирование сообщения:
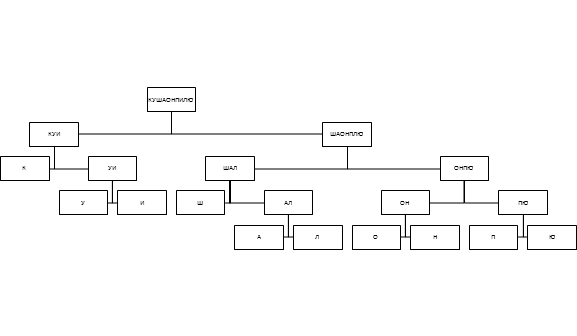
Если договориться, что считанный из закодированного сообщения нулевой бит соответствует движению по дереву влево, а единичный бит – движению вправо, процесс декодирования становится очевидным.
Тут же возникает вопрос, существует ли алгоритм, позволяющий построить кодовое дерево с минимальной избыточностью. Хаффман в своей работе не просто доказал, что такой алгоритм существует, но и предложил его. С тех пор алгоритм построения кодового дерева с минимальной избыточностью носит его имя. Основные шаги алгоритма Хаффмана приведены ниже:
Для нашего сообщение дерево Хаффмана будет выглядеть следующим образом:
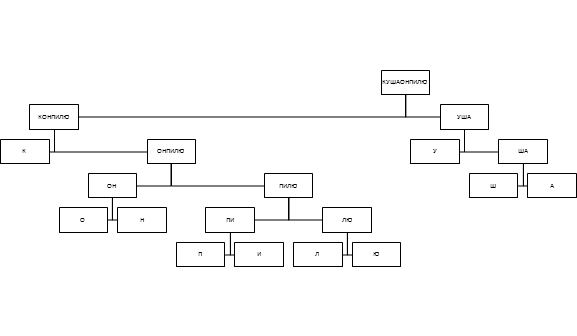
Закодированное с помощью алгоритма Хаффмана сообщение будет занимать всего 87 бит (выигрыш 25% по сравнению с блочным кодом).
Во всех наших выкладках мы молчаливо подразумевали, что в процессе декодирования таблица соответствия символ-код известна, но на практике это условие не выполняется, поэтому вместе с закодированным сообщением передаётся и сама таблица. В большинстве случаев эта таблица мала по сравнению с объёмом закодированного сообщения, и факт её передачи мало влияет на эффективность сжатия.
Тем не менее иногда встречаются ситуации, когда вес таблицы становится существенным. Например, в моей диссертации, посвящённой сжатию видео без потерь, эта ситуация встречается постоянно. При этом мощность алфавита составляет десятки и сотни миллионов записей.
Если использовать традиционный подход, когда передаётся таблица элемент – соответствующий код, накладные расходы становятся настолько большими, что об эффективном сжатии можно забыть. Передача вида элемент – частота тоже не лишена недостатков:
В результате исследований было принято решение позволяющее передавать не всю базу, а непосредственно элементы и небольшой объём дополнительной информации, описывающий структуру дерева. При этом на каждый элемент базы дополнительно передаётся только два дополнительных бита.
Договоримся о порядке обхода построенного кодового дерева, например, будем использовать обход в ширину. Если в процессе обхода встречается делящий узел дерева, то передаётся бит 0, если же в процессе обхода был обнаружен лист, то передаётся бит 1 и k бит, кодирующих соответствующий элемент базы. В итоге на каждый элемент базы передаётся всего 2 дополнительных бита.
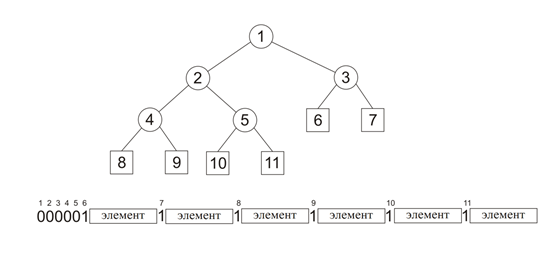
Указанное представление обратимо: то есть для каждой строки, построенной описанным способом, можно построить исходное кодовое дерево. Помимо очевидной экономии памяти предложенный способ передачи избавляет от необходимости строить кодовое дерево при декодировании тем самым существенно повышая скорость декодирования. На рисунке показано представление двоичного дерева в виде битовой строки с помощью описанного метода:
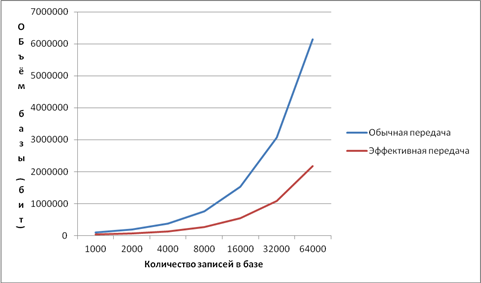
При описанном способе кодирования объём передачи значительно сокращается. На рисунке показаны объёмы передач при использовании описанных способов передачи базы:
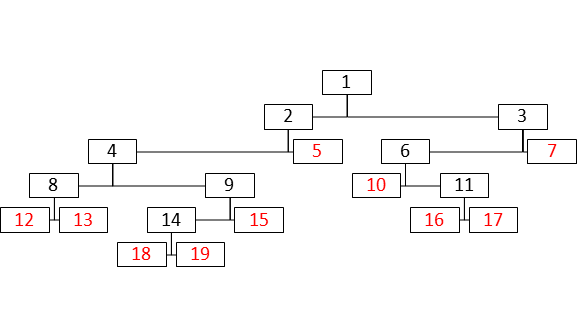
Но даже этот метод можно существенно улучшить. При кодировании и декодировании нам абсолютно не важно относительное (в пределах уровня) расположение узлов, поэтому можно выполнять процедуру перетасовки узлов, заключающуюся в перемещении всех листьев в левую часть дерева, а делящих узлов в правую. То есть дерево:
Преобразуется в дерево
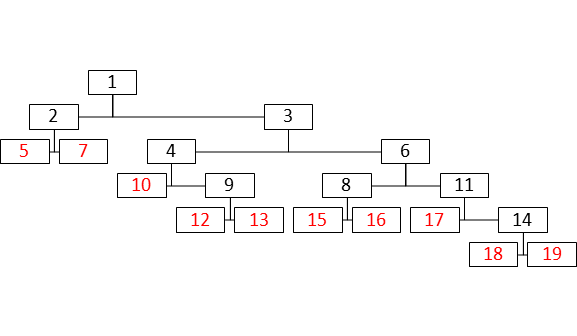
После такого преобразования единичный бит, означает не просто делящий узел, а то, что все узлы левее обрабатываемого на данном уровне тоже делящие.
Может вам такие оптимизации и кажутся несущественными, но именно они позволили добиться лучшего в мире (на большинстве тестовых видеопоследовательностей) коэффициента сжатия без потерь.
P.S. Даже в случае полностью построенного дерева Хаффмана, задача получения кода элемента из элементарной в случае небольших массивов превращается в практически неосуществимую, что в конечном итоге привело к возникновению принципиально нового вида бинарных деревьев. Если кому-то это будет интересно, я с удовольствием напишу ещё один топик.
P.P.S. О предложенном методе сжатия видео я тоже обязательно расскажу, но чуть позже.
В начале давайте рассмотрим основную идею, лежащую в основе энтропийного префиксного кодирования. Пусть у нас есть сообщение, состоящее из букв русского алфавита, например, «КУКУШКАКУКУШОНКУКУПИЛАКАПЮШОН». В этом сообщении встречается всего десять различных символов {К, У, Ш, А, О, Н, П, И, Л, Ю}, а значит, каждый символ может быть закодирован с использованием четырёх бит.
То есть всё сообщение при таком наивном блочном кодировании будет занимать 116 бит.
Но символам можно поставить в соответствие другие коды, например:
При использовании кодов из Табл. 2 длина сообщения составит уже 90 бит, а выигрыш более 22%. Внимательный читатель заметит, что коды в Табл. 1 имеют постоянную длину, а значит могут быть легко декодированы. В Табл. 2 коды имеют переменную длину, но они обладают другим важным свойством – префиксностью. Свойство префиксности означает, что ни один код не является началом никакого другого кода. Для любого префиксного кода может быть построено соответствующее дерево, с помощью которого можно однозначно выполнить декодирование сообщения:
Если договориться, что считанный из закодированного сообщения нулевой бит соответствует движению по дереву влево, а единичный бит – движению вправо, процесс декодирования становится очевидным.
Тут же возникает вопрос, существует ли алгоритм, позволяющий построить кодовое дерево с минимальной избыточностью. Хаффман в своей работе не просто доказал, что такой алгоритм существует, но и предложил его. С тех пор алгоритм построения кодового дерева с минимальной избыточностью носит его имя. Основные шаги алгоритма Хаффмана приведены ниже:
- Все символы алфавита представляются в виде свободных узлов, при этом вес узла пропорционален частоте символа в сообщении;
- Из множества свободных узлов выбираются два узла с минимальным весом и создаётся новый (родительский) узел с весом, равным сумме весов выбранных узлов;
- Выбранные узлы удаляются из списка свободных, а созданный на их основе родительский узел добавляется в этот список;
- Шаги 2-3 повторяются до тех пор, пока в списке свободных больше одного узла;
- На основе построенного дерева каждому символу алфавита присваивается префиксный код.
Для нашего сообщение дерево Хаффмана будет выглядеть следующим образом:
Закодированное с помощью алгоритма Хаффмана сообщение будет занимать всего 87 бит (выигрыш 25% по сравнению с блочным кодом).
Во всех наших выкладках мы молчаливо подразумевали, что в процессе декодирования таблица соответствия символ-код известна, но на практике это условие не выполняется, поэтому вместе с закодированным сообщением передаётся и сама таблица. В большинстве случаев эта таблица мала по сравнению с объёмом закодированного сообщения, и факт её передачи мало влияет на эффективность сжатия.
Тем не менее иногда встречаются ситуации, когда вес таблицы становится существенным. Например, в моей диссертации, посвящённой сжатию видео без потерь, эта ситуация встречается постоянно. При этом мощность алфавита составляет десятки и сотни миллионов записей.
Если использовать традиционный подход, когда передаётся таблица элемент – соответствующий код, накладные расходы становятся настолько большими, что об эффективном сжатии можно забыть. Передача вида элемент – частота тоже не лишена недостатков:
- На плечи декодера ложится вычислительно сложная задача построения кодового дерева;
- Разброс частот составляет несколько порядков, и стандартная вещественная арифметика не всегда позволяет точно его отобразить.
В результате исследований было принято решение позволяющее передавать не всю базу, а непосредственно элементы и небольшой объём дополнительной информации, описывающий структуру дерева. При этом на каждый элемент базы дополнительно передаётся только два дополнительных бита.
Договоримся о порядке обхода построенного кодового дерева, например, будем использовать обход в ширину. Если в процессе обхода встречается делящий узел дерева, то передаётся бит 0, если же в процессе обхода был обнаружен лист, то передаётся бит 1 и k бит, кодирующих соответствующий элемент базы. В итоге на каждый элемент базы передаётся всего 2 дополнительных бита.
Указанное представление обратимо: то есть для каждой строки, построенной описанным способом, можно построить исходное кодовое дерево. Помимо очевидной экономии памяти предложенный способ передачи избавляет от необходимости строить кодовое дерево при декодировании тем самым существенно повышая скорость декодирования. На рисунке показано представление двоичного дерева в виде битовой строки с помощью описанного метода:
При описанном способе кодирования объём передачи значительно сокращается. На рисунке показаны объёмы передач при использовании описанных способов передачи базы:
Но даже этот метод можно существенно улучшить. При кодировании и декодировании нам абсолютно не важно относительное (в пределах уровня) расположение узлов, поэтому можно выполнять процедуру перетасовки узлов, заключающуюся в перемещении всех листьев в левую часть дерева, а делящих узлов в правую. То есть дерево:
Преобразуется в дерево
После такого преобразования единичный бит, означает не просто делящий узел, а то, что все узлы левее обрабатываемого на данном уровне тоже делящие.
Может вам такие оптимизации и кажутся несущественными, но именно они позволили добиться лучшего в мире (на большинстве тестовых видеопоследовательностей) коэффициента сжатия без потерь.
P.S. Даже в случае полностью построенного дерева Хаффмана, задача получения кода элемента из элементарной в случае небольших массивов превращается в практически неосуществимую, что в конечном итоге привело к возникновению принципиально нового вида бинарных деревьев. Если кому-то это будет интересно, я с удовольствием напишу ещё один топик.
P.P.S. О предложенном методе сжатия видео я тоже обязательно расскажу, но чуть позже.
