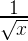Библиотека быстрого поиска путей на графе
8 min
Привет, Друзья!
Я написал библиотеку поисков путей на произвольных графах, и хотел бы поделиться ей с вами.
Пример использования на огромном графе:
Поиграться с демо можно здесь
В библиотеке используется мало-известный вариант A* поиска, который называется NBA*. Это двунаправленный поиск, с расслабленными требованиями к функции-эвристике, и очень агрессивным критерием завершения. Не смотря на свою малоизвестность у алгоритма отличная скорость сходимости к оптимальному решению.
Описание разных вариантов A* уже не раз встречалось на хабре. Мне очень понравилось вот это, потому повторяться в этой статье я не буду. Под катом расскажу подробнее почему библиотека работает быстро и о том, как было сделано демо.









 Здравствуйте, коллеги. В конце 1960-ых годов прошлого века
Здравствуйте, коллеги. В конце 1960-ых годов прошлого века