В данной теме я затрону 6 нормальных форм и методы приведения таблиц в эти формы.
Процесс проектирования БД с использование метода НФ является итерационным и заключается в последовательном переводе отношения из 1НФ в НФ более высокого порядка по определенным правилам. Каждая следующая НФ ограничивается определенным типом функциональных зависимостей и устранением соответствующих аномалий при выполнении операций над отношениями БД, а также сохранении свойств предшествующих НФ.
Процесс проектирования БД с использование метода НФ является итерационным и заключается в последовательном переводе отношения из 1НФ в НФ более высокого порядка по определенным правилам. Каждая следующая НФ ограничивается определенным типом функциональных зависимостей и устранением соответствующих аномалий при выполнении операций над отношениями БД, а также сохранении свойств предшествующих НФ.




 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.

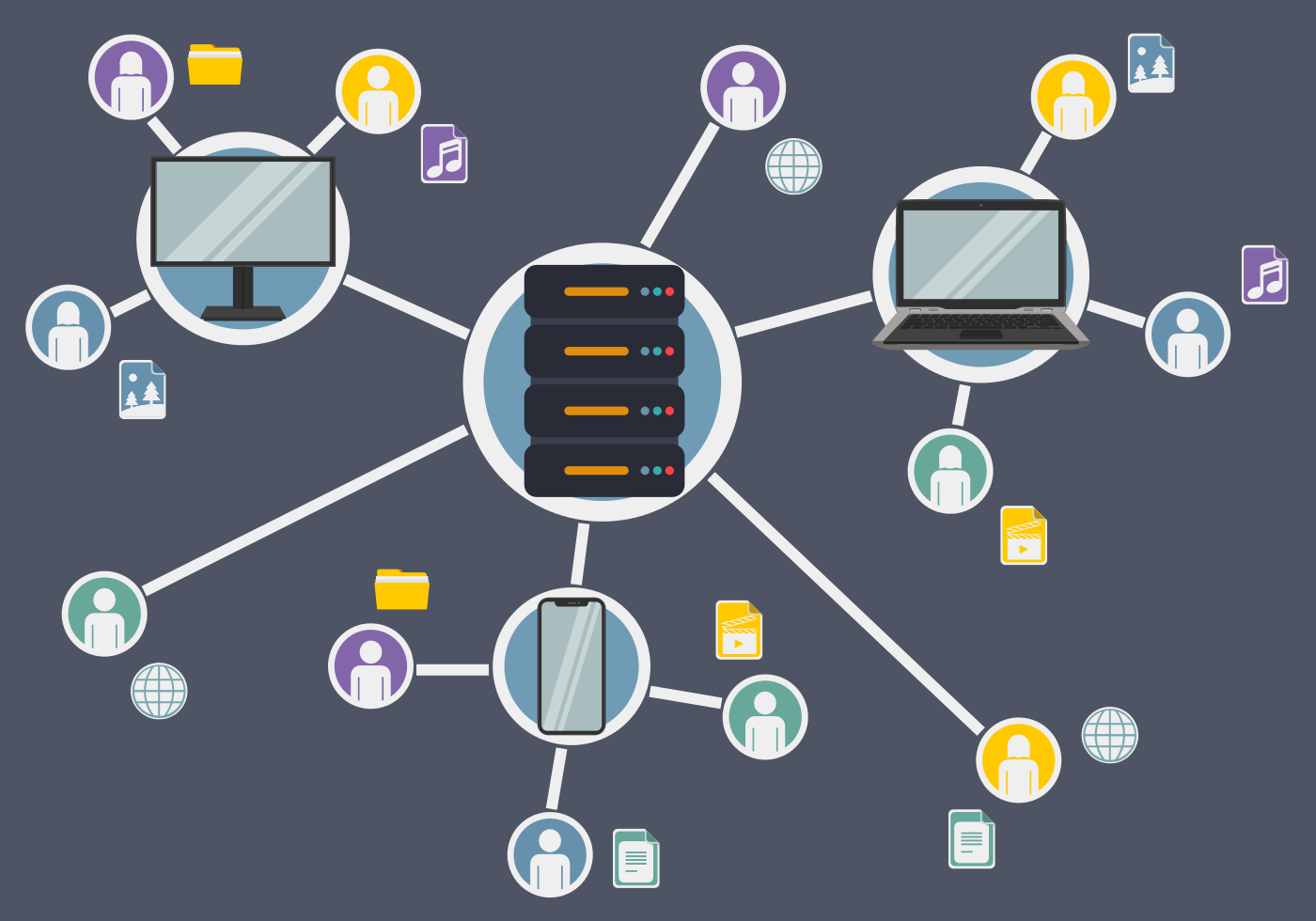
 Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».
Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».