Хотя в SQLite и нет возможности прочитать удаленные данные после завершения транзакции, сам формат файла позволяет отчасти сделать это. Подробности — под катом.


User
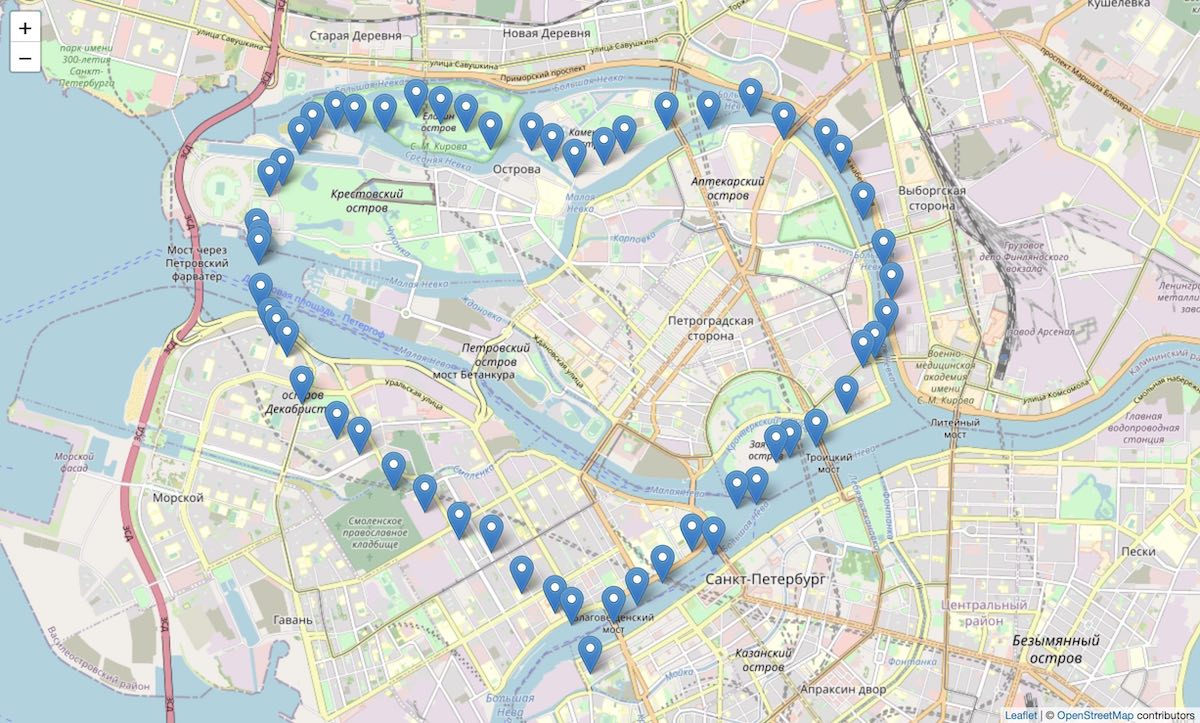
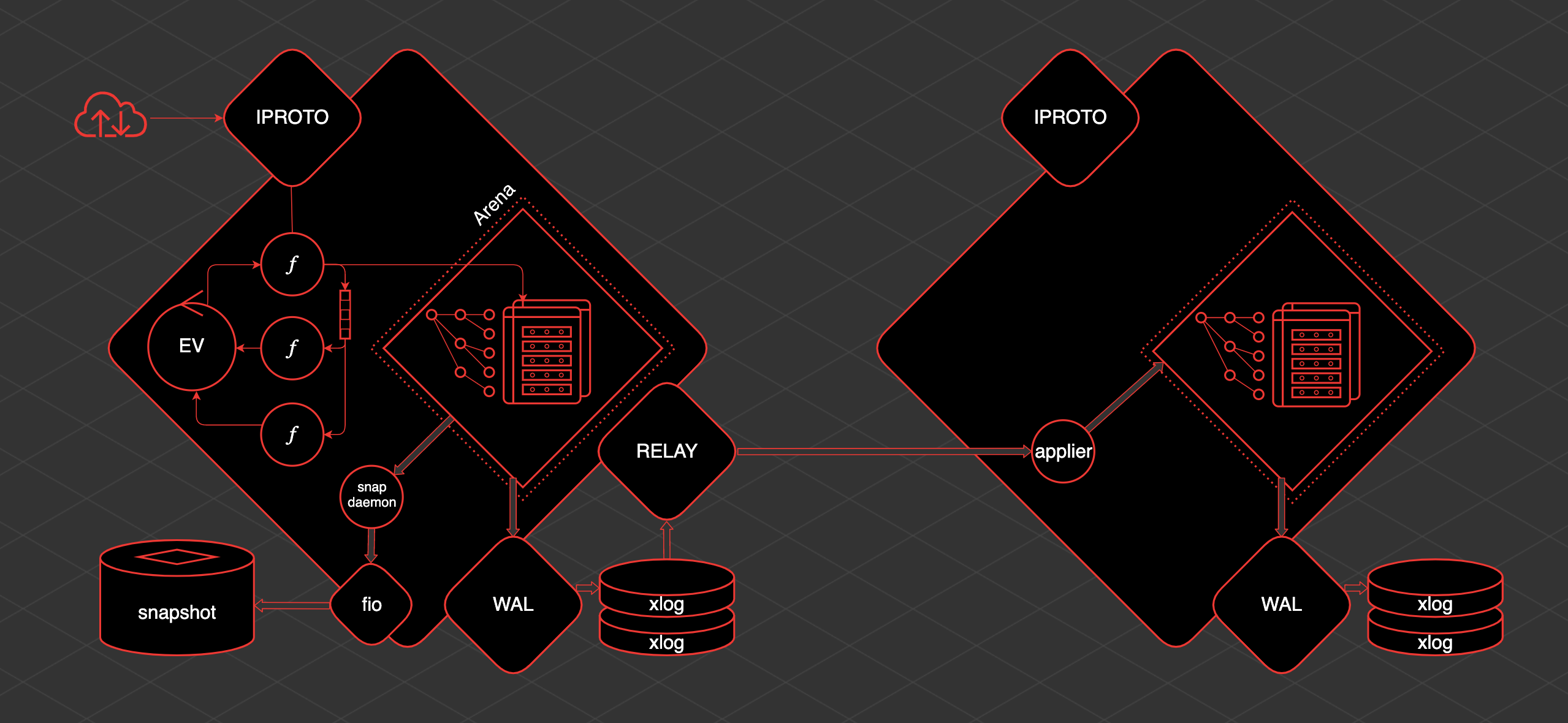
Ядро Tarantool-а написано на C, а вся бизнес-логика создаётся на Lua. Это не самый сложный язык, но и не самый популярный. Поэтому сегодня я расскажу, как начать работать с Tarantool, написав всего три строчки кода на Lua. А всё остальное приложение написано на Golang. Чтобы было еще интереснее, я даю альтернативный вариант на Python. Что за проект? Делаем приложение, которое позволяет ставить метки на карте: дом, работа, первое свидание, первый Hello World, первый "too long wal write" Tarantool.
Поехали!
Это вольный перевод поста одного из сильных разработчиков Postgres - Andres Freund. Кроме того что разработчик сильный, так еще и статья довольно интересная и раскрывает детали того как работает ОС Linux.
Довольно часто можно слышать заявления что постгресовые соединения используют слишком много памяти. Об этом часто упоминают сравнивая процессную модель обработки клиентских соединений с другой моделью, где каждое соединение обслуживается в отдельном потоке (thread).
Как по мне, здесь есть что обсудить...
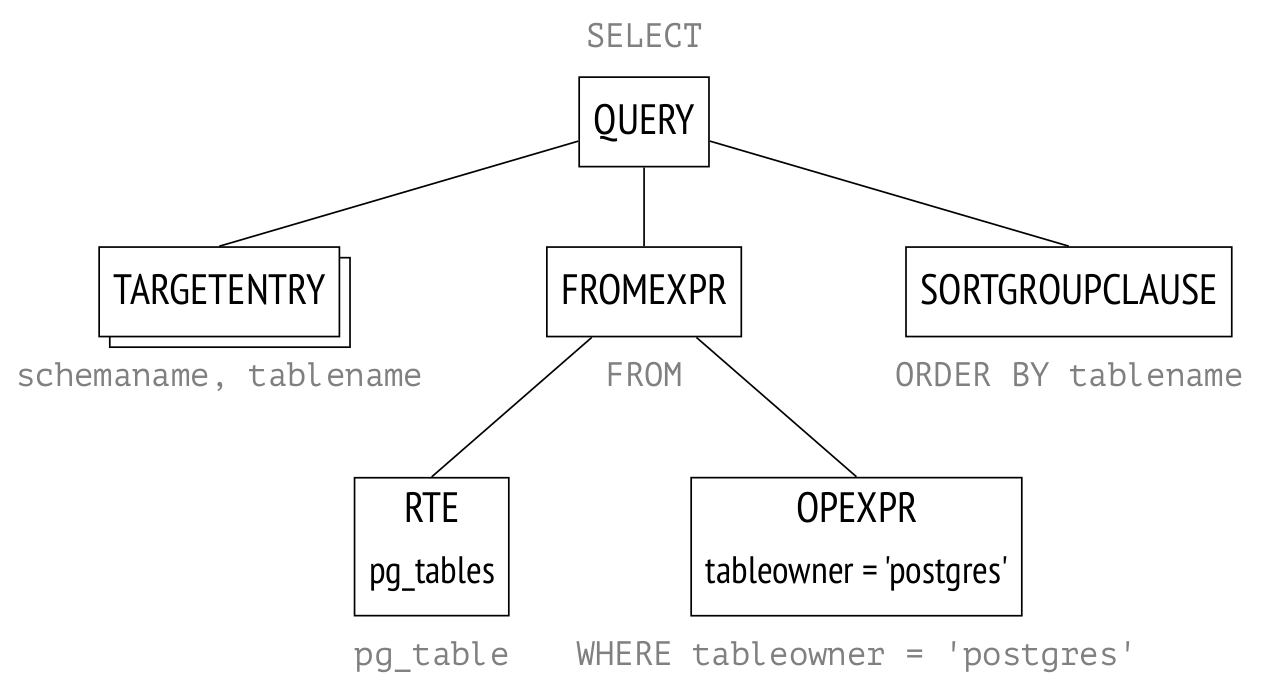
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
Предыдущие циклы были посвящены изоляции и многоверсионности, журналированию и блокировкам.
В этом цикле я собираюсь рассмотреть этапы выполнения запросов, статистику, последовательное сканирование, индексное сканирование, соединение вложенным циклом, соединение хешированием, сортировку и соединение слиянием.
Материал перекликается с нашим учебным курсом QPT «Оптимизация запросов», но ограничивается только подробностями внутреннего устройства и не затрагивает оптимизацию как таковую. Кроме того, я ориентируюсь на еще не вышедшую версию PostgreSQL 14. А курс мы тоже скоро обновим (правда, на версию 13; приходится бежать со всех ног, чтобы только оставаться на месте).

В этом переводе к старту курса по Fullstack-разработке на Python напоминаем о том, насколько важно знать технологии в деталях, грамотно применять их и планировать работу в целом. Цифра 2850 в заголовке — не преувеличение: ранее занимавший две минуты запрос в базе данных компании Affinity сегодня выполняется за 42 миллисекунды. Подробности, как всегда, под катом. А если вам нужен план развития навыков с большим количеством практики, вы можете обратить внимание на наши курсы.

Привет! Меня зовут Александр Петровский, я инженер в DINS. Я работаю в команде, которая участвует в разработке сервисов облачной телефонии и видеоконференций. Каждый из них состоит из большого количества микросервисов.
Когда мы мигрировали один из наших микросервисов с CentOS 7 с ядром 4.19 на Oracle Linux 7 с ядром 5.4, мы заметили рост утилизации процессора на наших stress/performance-тестах. В статье я расскажу, как мы исследовали причины роста утилизации процессора сначала в user-space, а потом и в kernel-space и о том, к какому результату это нас привело.
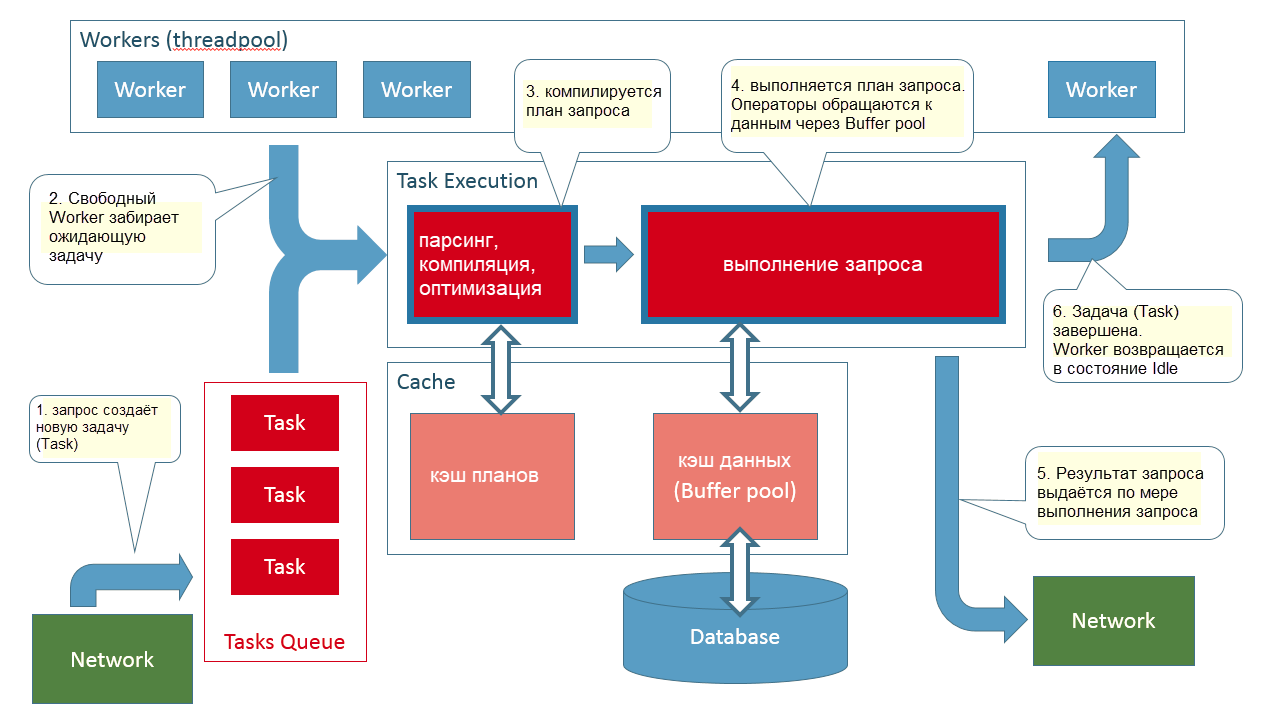
Если вы разработчик, работаете над приложением, которое взаимодействует с SQL Server, и вам интересно, что в действительности происходит, когда вы «выполняете» запрос из своего приложения – что ж, я надеюсь, эта статья поможет лучше писать код запросов, а также может стать отправной точкой для расследования проблем производительности.

От корректного функционирования базы данных (БД) может зависеть не только скорость, но и надежность приложения. Для глубокого погружения в задачи специалисту, как правило, нужно освоить работу с транзакциями – об этом и пойдет речь ниже. Рассмотрим виды и свойства транзакций, а также постараемся понять, как устроен этот механизм. Надеемся, что статья может быть полезна начинающим разработчикам и всем, кто хочет лучше разобраться в теме.

Статья подготовлена на основе уроков из открытой темы "Установка LEMP стека с помощью Ansible" курса по Ansible от Слёрм. Автор – Всеволод Севостьянов, Lead Engineer в Vene.io (Affiliate marketing solution). Первые две темы курса доступны на Youtube.
Материал этого урока будет интересен тем, кто разобрался с установкой Ansible и готов написать свой первый плейбук. Результатом будет плейбук, устанавливающий nginx на удалённой машине.

Представляем текстовую версию недавнего разговора с коллегами из Data Egret — компании, которая специализируется на поддержке PostgreSQL. Ведущий инженер команды Okmeter Владимир Гурьянов пообщался с Ильей Космодемьянским (CEO Data Egret) и Алексеем Лесовским (senior DBA Data Egret). Обсудили, как мониторить PostgreSQL, какие бывают ошибки при выборе и настройке систем мониторинга, кто такие DBA и какие soft skills для них важны, а также затронули более хардкорные темы. Пост объемный, но он того стоит.

Приветствую всех любителей Infrastructure as Code.
Как я уже писал в предыдущей статье, я люблю заниматься автоматизацией инфраструктуры. Сегодня представляю вашему вниманию вариант построения GitOps для реализации подхода Monitoring as Code.
 Савва Демиденко
Савва Демиденко Илья Сильченков
Илья Сильченков
Всем привет!
Сегодня расскажем о сравнительно новой для нас теме — про перевод приложения с Oracle на Postgres Pro (далее в тексте везде сокращу до PG). В общем смысле тема не столь уж нова — многие компании этим также занимаются или даже уже прошли этот путь. Так, например, на ежегодной конференции pgConf всегда есть несколько интересных докладов по этой теме (https://pgconf.ru/). Если говорить о формальностях, то мы реализуем инициативу согласно (Приказ Министерства связи «Об утверждении плана по импортозамещению программного обеспечения» от 01.02.2015 № 96). По факту — ещё и денег экономим, слезая с "лицензионной иглы". На эту тему можно отдельную статью написать, а в этой речь пойдёт о программной стороне вопроса. Кому интересно, добро пожаловать под кат.
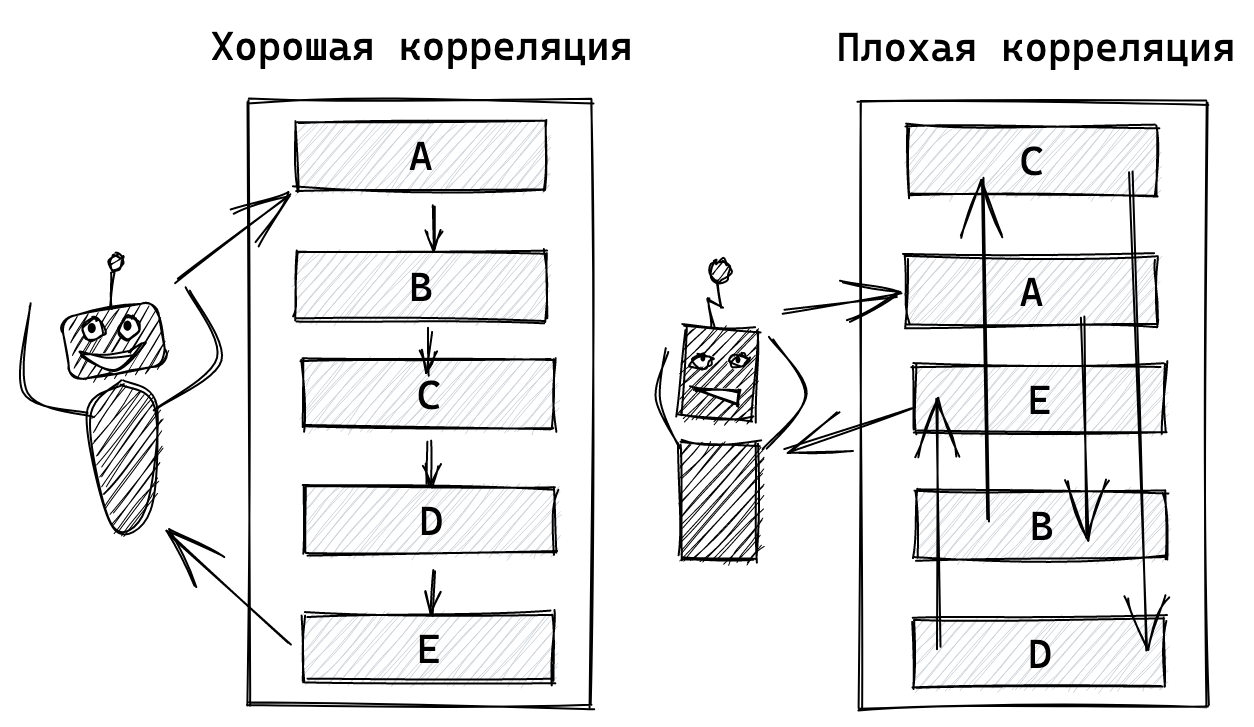
"Хочешь ускорить запросы, построй индекс" – классический первый шаг по увеличению производительности в PostgreSQL. Вот только на практике можно встретить ситуацию, когда индексы в PostgreSQL есть, но тормоза никуда не делись. Не все индексы являются эффективными. Одна из возможных причин тормозов индексов – это отсутствие корреляции данных. Давайте поговорим о пенальти на производительность, которое дает расположение данных: почему это происходит и как это можно предотвратить.

Привет Хабр!
Сегодня я сниму костюм аниматора и вместо развлечений расскажу вам немного за питон.
Я довольно посредственный программист, но иногда мне удаётся усыпить что-нибудь бдительность, и меня считают сеньором. И вот как-то так получилось, что я стал делать много код ревью. Просматривая файл за файлом, я вдруг увидел, что люди и проекты меняются, а вот моменты, к которым я, зануда такая, придираюсь, остаются теми же. Поэтому я решил собрать самые частые паттерны в эту сумбурную статью и надеюсь, что они помогут вам писать более чистый и эффективный питон-код.
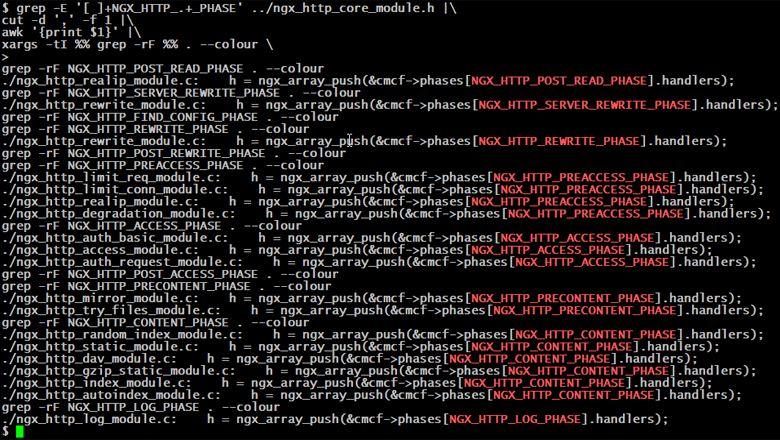
Эта статья родилась случайно. Слоняясь по книжному фестивалю и наблюдая, как дочка пытает консультантов, заставляя их искать Иэна Стюарта, мой глаз зацепился за знакомые буквы на обложке: "Nginx".
Надо же, на полках нашлось целых три книги - не полистать их было бы преступлением. Первая, вторая, третья... Ощущение, будто что-то не так. Ну вроде страниц много, текст связный, но каково содержание? Установка nginx, список переменных и модулей, а дальше docker, ansible. Открываем вторую: wget, лимиты запросов и памяти, балансировка, kubernetes, AWS. Третья: GeoIP, авторизация, потоковое вещание, puppet, Azure. Ребята, а где про то, как вообще работает nginx? На кого рассчитаны ваши книги? На состоявшегося админа, который и так знает архитектуру этого веб-сервера? Да он вроде с базовыми настройками и сам справится. На новичка, который не знает как пользоваться wget? Вы уверены, что ему знание о существовании ngx_http_degradation_module и тем паче "облака" важнее порядка прохождения запроса?
Итак. О чем не пишут в книгах.
(здесь и дальше мы говорим только о NGX_HTTP_)