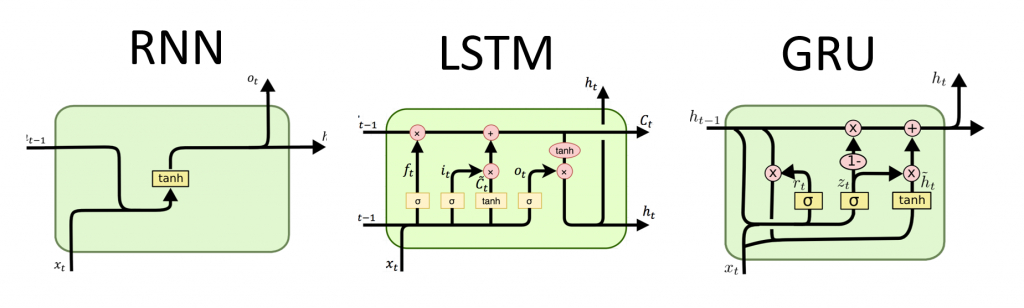
9 ключевых алгоритмов машинного обучения простым языком
15 мин
Привет, Хабр! Представляю вашему вниманию перевод статьи «9 Key Machine Learning Algorithms Explained in Plain English» автора Nick McCullum.
Машинное обучение (МО) уже меняет мир. Google использует МО предлагая и показывая ответы на поисковые запросы пользователей. Netflix использует его, чтобы рекомендовать вам фильмы на вечер. А Facebook использует его, чтобы предложить вам новых друзей, которых вы можете знать.
Машинное обучение никогда еще не было настолько важным и, в тоже время, настолько трудным для изучения. Эта область полна жаргонов, а количество разных алгоритмов МО растет с каждым годом.
Эта статья познакомит вас с фундаментальными концепциями в области машинного обучения. А конкретнее, мы обсудим основные концепции 9ти самых важных алгоритмов МО на сегодняшний день.
Машинное обучение (МО) уже меняет мир. Google использует МО предлагая и показывая ответы на поисковые запросы пользователей. Netflix использует его, чтобы рекомендовать вам фильмы на вечер. А Facebook использует его, чтобы предложить вам новых друзей, которых вы можете знать.
Машинное обучение никогда еще не было настолько важным и, в тоже время, настолько трудным для изучения. Эта область полна жаргонов, а количество разных алгоритмов МО растет с каждым годом.
Эта статья познакомит вас с фундаментальными концепциями в области машинного обучения. А конкретнее, мы обсудим основные концепции 9ти самых важных алгоритмов МО на сегодняшний день.
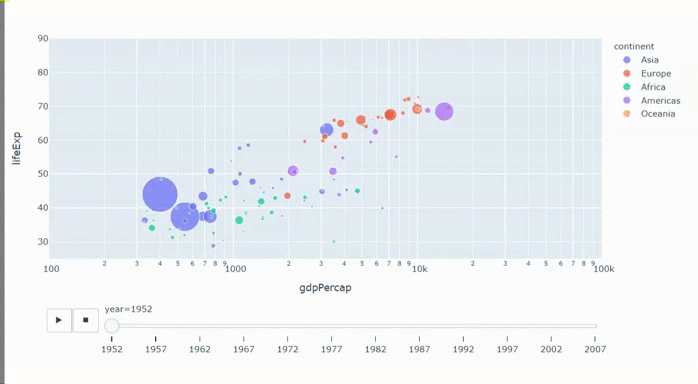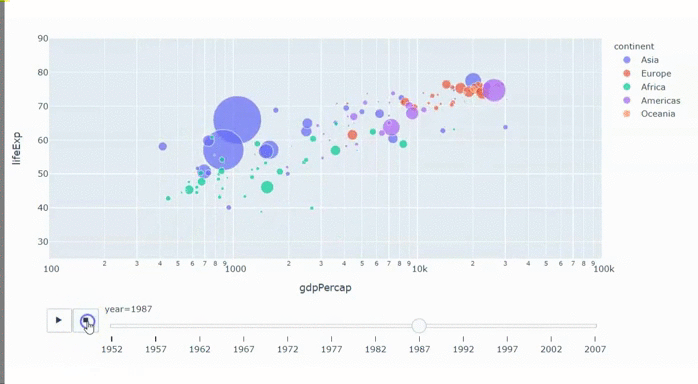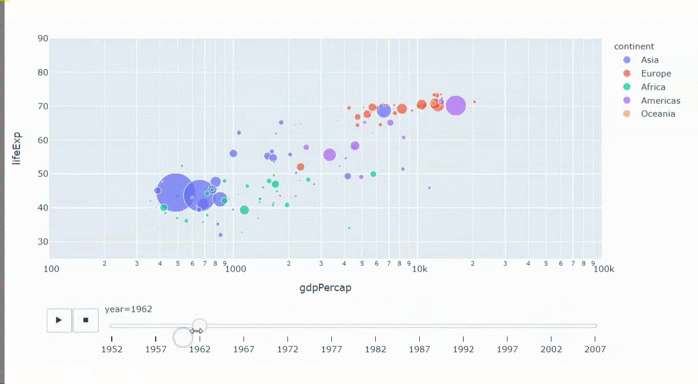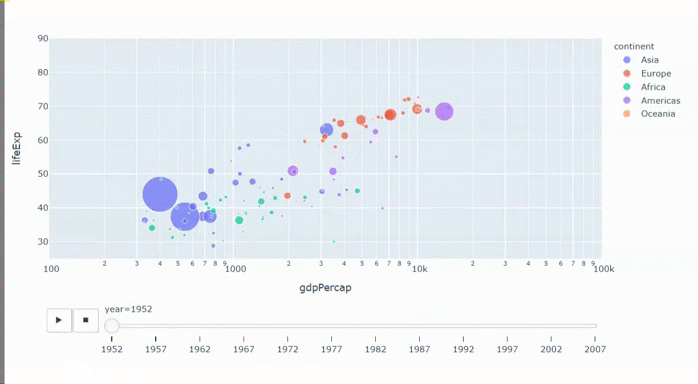

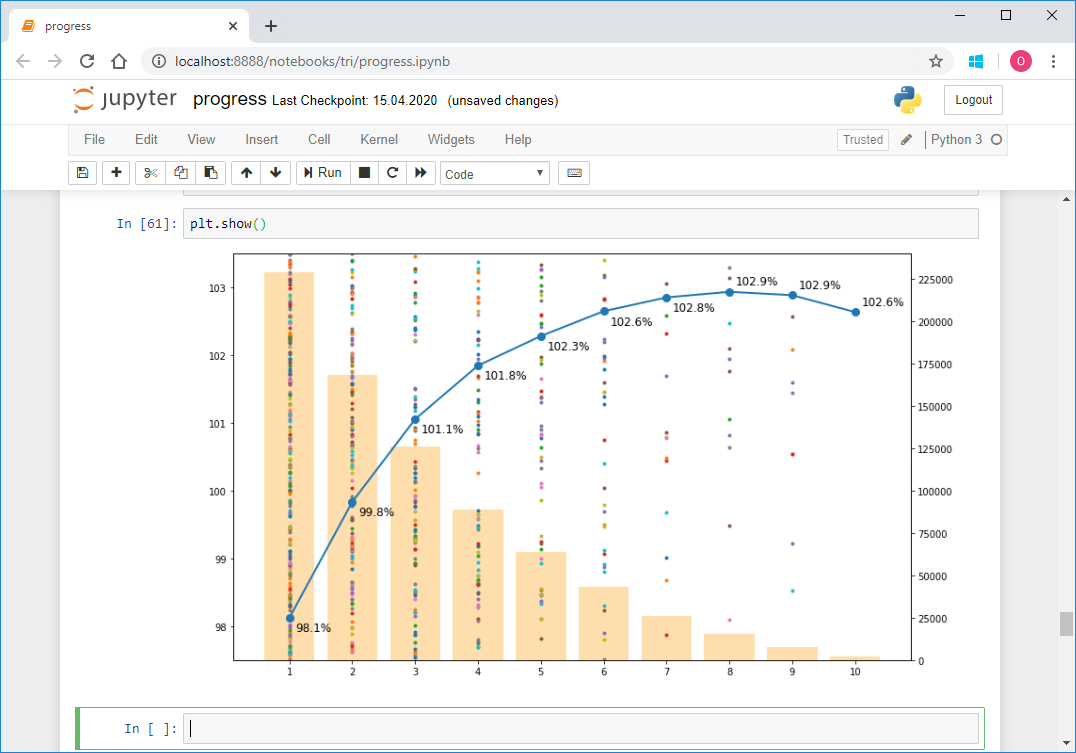







 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест