
С конца февраля Россию покинули от пятидесяти до семидесяти тысяч IT-специалистов. Общее число уехавших людей посчитать сложно, но, по некоторым данным, это около 200 тысяч человек разных профессий.

Программист
С конца февраля Россию покинули от пятидесяти до семидесяти тысяч IT-специалистов. Общее число уехавших людей посчитать сложно, но, по некоторым данным, это около 200 тысяч человек разных профессий.
Многие новички до сих пор попадают в тупик при написании простейшей аутентификации в PHP. На Тостере с завидной регулярностью попадаются вопросы о том, как сравнить сохраненный пароль с паролем полученным из формы логина. Здесь будет краткая статья-туториал на эту тему.
Disclaimer: статья рассчитана на совершенных новичков. Умудрённые опытом разработчики ничего нового здесь не найдут, но могут указать на возможные недочёты =).

Написав предыдущую статью о сортировке подсчётом beSort - меня не отпустило. Я решил поковыряться в базовых алгоритмах и залип на модификациях пузырьковой сортировки, ну а статья о том - что из этого получилось.

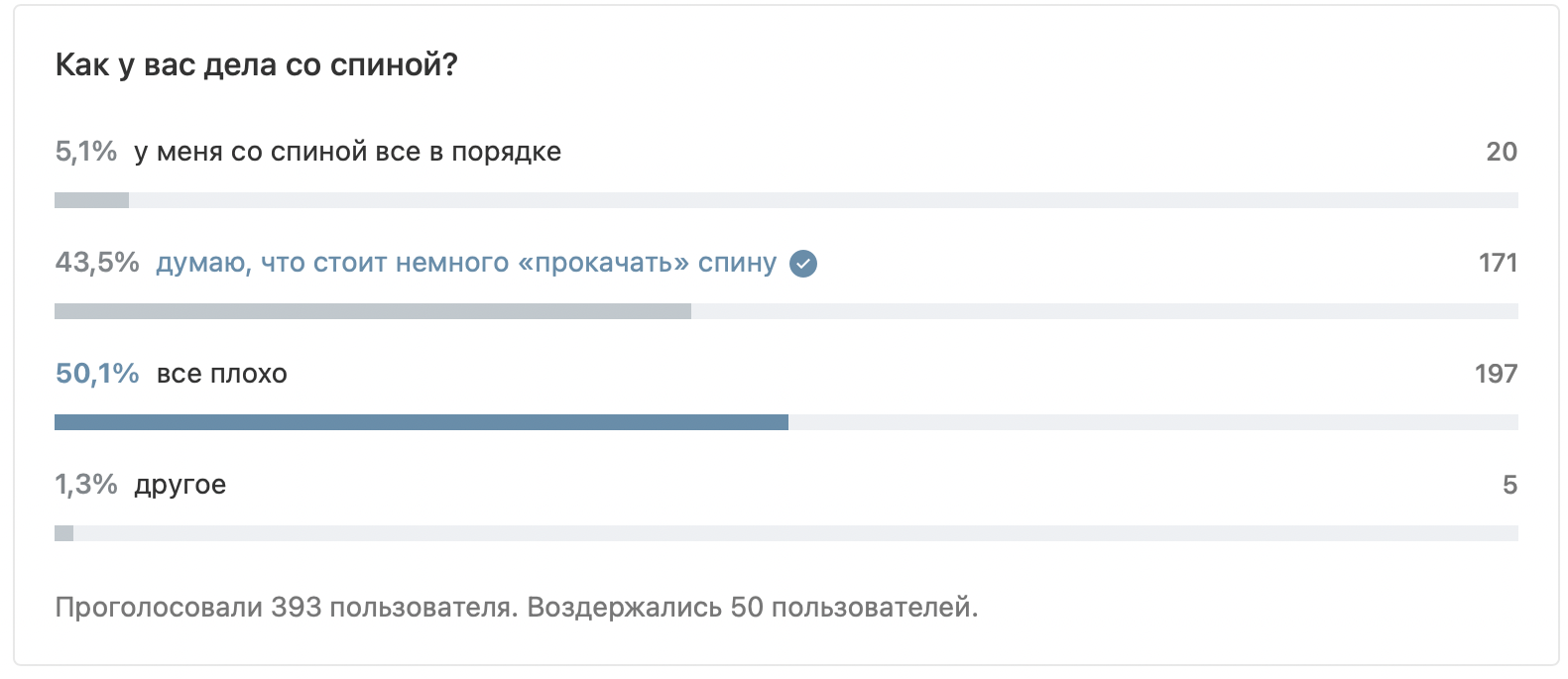
Как я изобрёл весьма быстрый велосипед и узнал, что на нём уже кто-то ездит.

Попалась мне задачка оптимизации, а так как я большой фанат Экселя, то и выбор инструмента был скорым. Единственная пакость: Эксель дико медленный. Так, на одну итерацию уходило как минимум 35 минут, а таких итераций планировалось сделать 1275 (как минимум)!
Цель этого небольшого проектика – ускорить исполнение VBA скриптов задействуя все доступные мне железяки: GPU и CPU. Ну и до кучи, так как библиотека моя, была реализована многозадачность.
Тётушка Полли попросила Тома расставить горшки с цветами у дорожки от калитки к дому, строго по высоте, чтобы самые высокие и пышные кусты стояли у самой улицы, вызывая восхищение у соседей, а постепенное убывание в высоте создало бы эффект перспективы.
Друзья по играм: Бен, Билли, Том Миллер и другие, с интересом ждали правил игры, в которую Сойер превратит задание на этот раз.
Том выбежал из дома и с азартом схватил ближайший горшок от крыльца, оставив пустое блюдце из-под горшка на земле.
-- Пропади я пропадом, если не уберу подальше от улицы все кусты, что будут похуже этого!
Том в задумчивости осмотрел ряд таких же кустов.
-- Вот второй куст, он повиднее этого! Но почём мне знать насколько он хорош? Пусть пока постоит на месте. Тётушка точно будет недовольна, если мы будем дёргать горшки почём зря.
-- Третий тоже повыше моего, оставим и его до срока.
Том медленно пошёл вдоль дорожки, придирчиво сравнивая каждый цветок со своим образцом. У очередного куста от воскликнул:
-- Попался, оборванец! Что ж поделать, многоуважаемый недоросль, ваше место займёт более возвышенный кандидат!
Аккуратно поставив образец на дорожку, Том схватил провинившийся горшок и побежал к дому. Пристроив его на пустующее первое блюдце, мальчик с пафосом обратился к соседнему, второму цветку: -- Уж даже и не знаю, насколько хороши Вы лично, но Вам точно нечего делать по соседству с этим жалким ничтожеством!
Он схватил второй куст и перенёс его на пустующее место в ряду, возле своего образца.
Поднимая свой образец с земли, Том с жалостью сказал ему: -- Судя по всему, дружок, тебе не украшать собой вход у калитки... Но пойдём дальше, поищем ещё кого-то похуже тебя.

Дикий лонг-рид о цвете в разработке дизайна: какое влияние цвета оказывают на людей как на вид животных, на какие ассоциации мы должны обратить внимание и как работать с эмоциями пользователей.
Всем привет. Хочу поделиться своим опытом в парсинге XML, хочу рассказать об инструменте который мне в этом помогает.
XML ещё жив и иногда его приходиться парсить. Особенно если вы работаете со СМЭВ (привет всем ребятам для которых "ФОИВ" не пустой звук :) ).
Цели у такого парсинга могут быть самые разные, от банального ответа на вопрос какое пространство имён используется в xml-документе, до необходимости получить структурированное представление для документа вцелом.
Инструмент для каждой цели будет свой. Пространство имён можно найти поиском подстроки или регулярным выражением. Что бы сделать из xml-документа структурированное представление (DTO) - придётся писать парсер.
Для работы с XML в PHP есть пара встроенных классов. Это XMLReader и SimpleXMLElement.

История парня с инвалидностью, который решил стать мелким блогером на YouTube.
В статье найдете мотивацию, аналитику, идеи, чек-лист перед стартом — все,что нужно, чтобы вдохновиться и действовать.
Наверное, сейчас не очень актуальная информация. Зато пригодится в будущем!

В одном из выпусков библиотеки журнала «Квант» я обнаружил перевод книги Льюиса Кэрролла «Логическая игра» (The Game of Logic). В ней автор рассказывает об оригинальном графическом способе визуализации логических суждений с помощью размеченного особым образом квадратного поля и фишек двух цветов. Этот способ помогает легко оперировать логическими множествами и на основе некоторых предпосылок формулировать новые утверждения. Давайте попробуем разобраться, как это работает.

В данной статье я хочу рассказать про то, как технически устроены бот-атаки типа парсинг цен на e-commerce сайтах, какие механизмы используют атакующие, как противостоять бот-атакам самостоятельно и с помощью прикладных решений.
Я поделюсь практическим опытом нашей компании в защите e-commerce приложений и продемонстрирую реальные кейсы противодействия парсинга и бот-атакам.
В рамках статьи я сосредоточусь на атаках, которые относятся к типу Scraping по классификации OWASP. Детальную классификацию автоматизированных угроз веб-приложениям можно изучить в документе OWASP Automated Threats to Web Applications. Конечно, противодействие бот-атакам данного типа позволит остановить и другие автоматизированные атаки, но в нашей практике мы видим, в основном, именно атаки типа price scraping – автоматизированный сбор информации о товарах и ценах, или парсинг цен. Я не рассматриваю юридические и морально-этические вопросы парсинга цен в данной статье.

Вступление
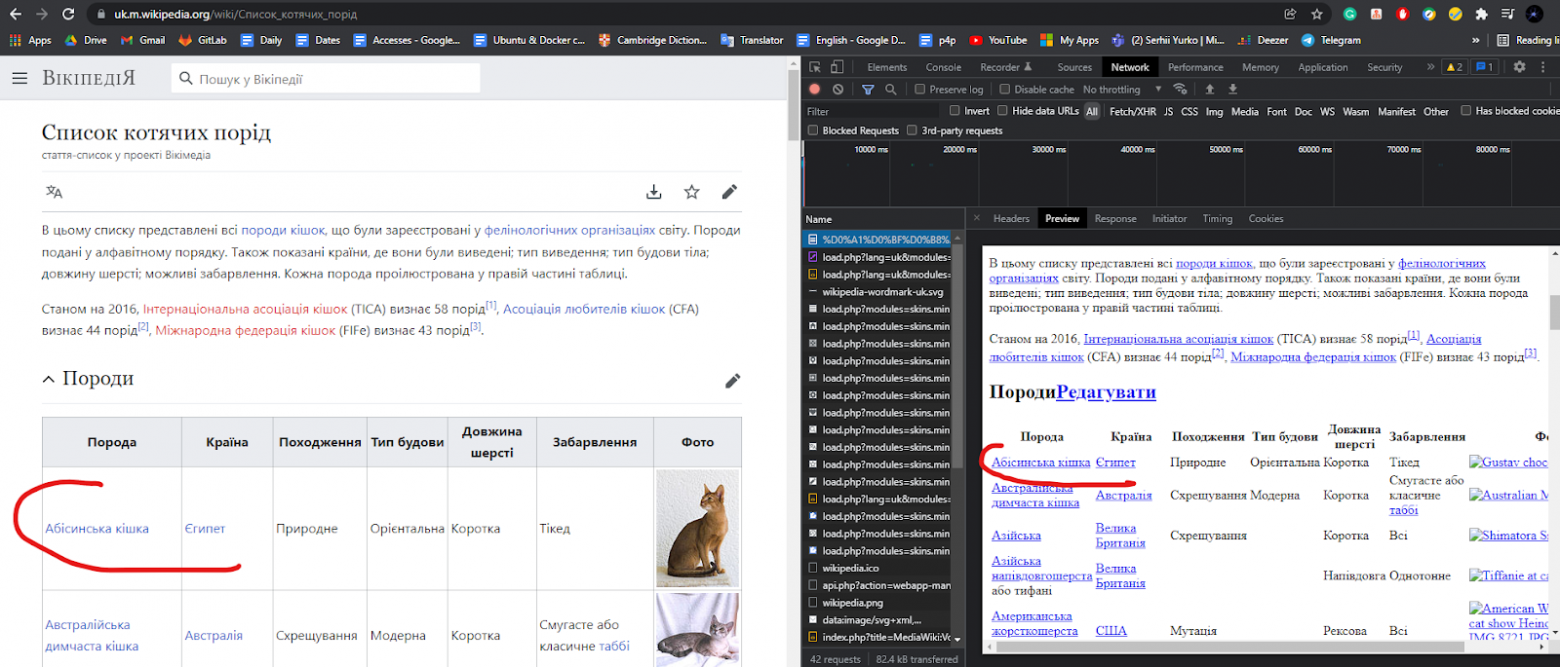
У меня бывают ситуации на проектах, когда нужна база данных какой-то статической информации. Но увы, пошарив в интернетах, какого то публичного хранилища найти не удалось, но тем не менее, я вижу кучу ресурсов, которые это используют.
В моем случае мне понадобилась база данных пород кошек, но среди этих примеров может быть что угодно, от базы данных имен, названия городов, областей и т.д. Эта статья о базовых подходах и практиках парсинга данных с веб ресурсов.
Хочу подметить, что хоть в моих жилах течет дотнет, в этом примере я буду использовать Node JS, потому что так быстрее, и удобнее в плане парсинга. Чем именно удобней - я расскажу позже в статье.
Можем ли мы спарсить?
Да, к сожалению (или счастью) веб - он не однообразен, и каждый ресурс может быть уникален по своему, но в нашем деле, ключевым моментом будет то, есть ли на этом ресурсе Server-Side Rendering (SSR), или там Client-Side Rendering и важная для нас информация подтягивается позже с помощью JS.
К примеру, нативные апки на React или тот же Angular by default есть CSR. И что бы прикрутить там SSR нужно порой очень сильно попотеть.Тем не менее, большинство сайтов с топ серч результатов любой поисковой системы будут поддерживать именно SSR, потому что таков мир SEO-оптимизаций.

Прим. Wunder Fund: ну, вы наверное, и сами догадываетесь, как мы любим быстрые алгоритмы и оптимизации. Если вы тоже такое любите — вы знаете, что делать)
Публикуем вторую часть перевода материала об очень быстром алгоритме сортировки — «Ska Sort». В первой части говорилось о временной сложности алгоритмов и о том, какие улучшения базового алгоритма «Американский флаг» позволили автору «Ska Sort» повысить скорость сортировки. Сегодняшний материал посвящён рассказу о том, почему новый алгоритм быстрее других алгоритмов сортировки.

Прим. Wunder Fund: ну, вы наверное, и сами догадываетесь, как мы любим быстрые алгоритмы и оптимизации. Если вы тоже такое любите — вы знаете, что делать)
В наши дни сказать, что изобрёл алгоритм сортировки, который на 30% быстрее того, что считают эталонным, это значит — сделать довольно смелое заявление. Я, к сожалению, вынужден сделать ещё более смелое заявление. Дело в том, что я создал алгоритм сортировки, который, для многих вариантов входных данных, вдвое быстрее std::sort. И, за исключением сортировки специально созданных входных последовательностей, на которых алгоритм упирается в свой худший случай, он всегда быстрее std::sort. (А когда появляются данные, приводящие к худшему случаю алгоритма, я эту ситуацию детектирую и автоматически перехожу на std::sort).
Почему я сказал: «…к сожалению, вынужден…»? Вероятно из-за того, что мне, скорее всего, предстоит нелёгкое дело убеждения читателя в том, что я действительно увеличил скорость сортировки в два раза. Поэтому материал, который я начинаю писать, вполне может получиться достаточно длинным. Но весь мой код открыт — это значит, что вы можете попробовать мои наработки на данных, характерных для вашей сферы деятельности. Поэтому я могу убедить вас в достоинствах моего алгоритма с помощью массы аргументов и результатов измерений. А ещё вы можете просто попробовать алгоритм самостоятельно.
Учитывая то, о чём я писал в моём прошлом материале, это, конечно, вариант поразрядной сортировки (radix sort). То есть — его временная сложность ниже, чем O(n log n). Вот два основных направления, по которым я усовершенствовал базовый алгоритм:

Автор Лысый Камрад (@LKamrad)
В начале 1900-х годов инженер Дженнаро Матроне проводил раскопки в древнеримском городке Стабии недалеко от знаменитых Помпей. Стабии погибли в том же самом извержении Везувия 79 года нашей эры, что и Помпеи с Геркуланумом.
На берегу моря он нашел останки 73 человек, видимо, ожидавших спасения на кораблях в тот роковой день. Но один скелет привлек его особое внимание - изобилием драгоценностей.
Это скелет мужчины в возрасте с золотым ожерельем из трех цепей, с золотыми же браслетами и армлетами (браслеты носят на запястье, армлеты - выше локтя), кольцами и, самое главное, мечом с рукояткой из слоновой кости в истлевших ножнах, украшенных изысканным золотым узором с изображением морских раковин. Меч указывал на то, что человек был военным, связанным с морем, причем, судя по богатству, явно на очень высокой должности...

IT-индустрия – динамичная сфера, где новые технологии и решения могут кардинально изменять структуру рынка, что влияет на популярность того или иного стека. Также IT-рынок подвержен субъективному хайпу, когда на какие-то технологии и языки программирования обращают чрезмерное внимание без объективных предпосылок к этому. Все это по итогу влияет на востребованность специалистов по конкретному языку, работающих на конкретной технологии, на определенной зарплатной вилке.
В этой статье я поделюсь своим мнением насчет востребованности PHP, как современного языка программирования – актуален ли он на 2022 год или нет.Что из себя представляет PHP
Обычно при обсуждении языка программирования приводят его сильные стороны, поэтому я буду следовать традиции и расскажу, почему PHP – это клевый и современный язык программирования.
Отличная производительность. Команда CORE PHP разработчиков выполнила гигантскую работу по оптимизации PHP и сделала его более производительным. Так, например, в своей статье Дмитрий Стогов приводит бенчмарк для версии PHP 7.0, где демонстрируется, что PHP обходит по производительности своих конкурентов, таких как Python и Ruby, и даже не сильно отстает от Java с выключенным JIT.