В рамках недавно прошедшей конференции
DotNext 2018 состоялся BoF по Domain Driven Design. На нем был затронут вопрос работы с исключениями, который вызвал жаркий спор, но не получил развернутой дискуссии, поскольку не являлся основной темой.
Также, изучая множество ресурсов, начиная от вопросов на stackoverflow и заканчивая платными курсами по архитектуре, можно наблюдать, что в IT-сообществе сложилось неоднозначное отношение к исключениям и к тому, как их использовать.
Наиболее часто упоминается, что с использованием исключений легко построить поток исполнения,
имеющий семантику оператора goto, что плохо сказывается на читабельности кода.
Есть разные мнения о том, стоит ли
создавать собственные типы исключений или использовать стандартные, поставляемые в .NET.
Кто-то делает валидацию на исключениях, а кто-то повсеместно
использует монаду Result. Справедливо, что Result позволяет по сигнатуре метода понять, возможно ли не только успешное выполнение. Но не менее справедливо, что в императивных языках (к которым относится C#) повсеместное использование Result приводит к плохо читаемому коду, засыпанному конструкциями языка настолько, что с трудом можно разглядеть исходный сценарий.
В данной статье я расскажу о практиках, принятых в нашей команде (если кратко — мы используем все подходы и ни один из них не является догмой).
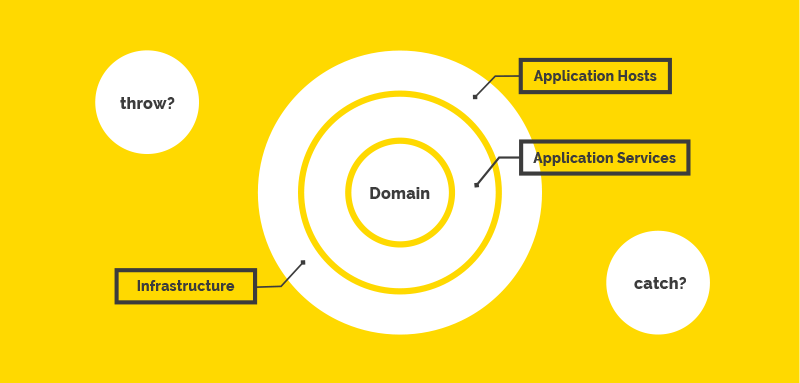
Речь пойдет об enterprise-приложении, построенном на базе ASP.NET MVC+WebAPI. Приложение построено по
луковой архитектуре, общается с базой данных и брокером сообщений. Используется структурированное логирование в ELK-стек и настроен мониторинг при помощи Grafana.