— Прототипное наследование — это прекрасно
JavaScript — это объектно-ориентированный (ОО) язык, уходящий корнями в язык Self, несмотря на то, что внешне он выглядит как Java. Это обстоятельство делает язык действительно мощным благодаря некоторым приятным особенностям.
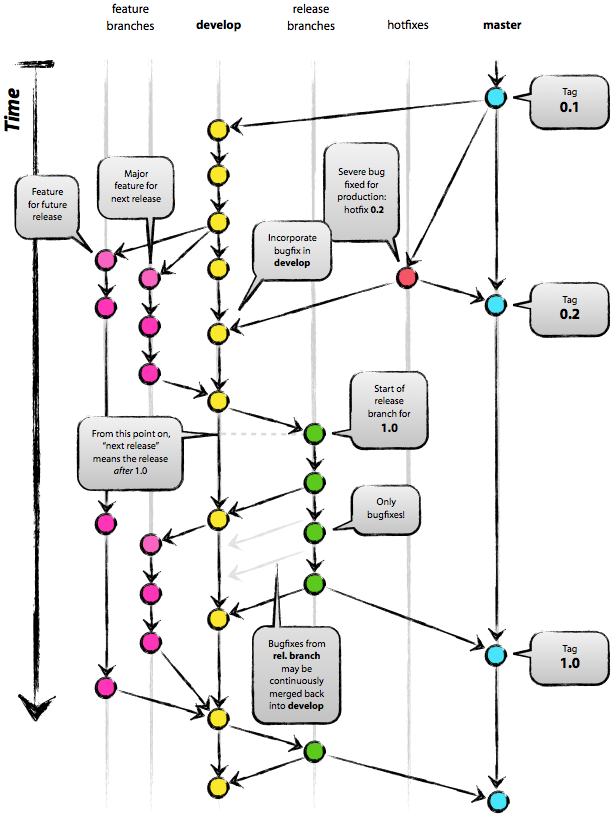
Одна из таких особенностей — это реализация прототипного наследования. Этот простой концепт является гибким и мощным. Он позволяет сделать наследование и поведение сущностями первого класса, также как и функции являются объектами первого класса в функциональных языках (включая JavaScript).
К счастью, в ECMAScript 5 появилось множество вещей, которые позволили поставить язык на правильный путь (некоторые из них раскрыты в этой статье). Также будет рассказано о недостатках дизайна JavaScript и будет произведено небольшое сравнение с классической моделью прототипного ОО (включая его достоинства и недостатки).
JavaScript — это объектно-ориентированный (ОО) язык, уходящий корнями в язык Self, несмотря на то, что внешне он выглядит как Java. Это обстоятельство делает язык действительно мощным благодаря некоторым приятным особенностям.
Одна из таких особенностей — это реализация прототипного наследования. Этот простой концепт является гибким и мощным. Он позволяет сделать наследование и поведение сущностями первого класса, также как и функции являются объектами первого класса в функциональных языках (включая JavaScript).
К счастью, в ECMAScript 5 появилось множество вещей, которые позволили поставить язык на правильный путь (некоторые из них раскрыты в этой статье). Также будет рассказано о недостатках дизайна JavaScript и будет произведено небольшое сравнение с классической моделью прототипного ОО (включая его достоинства и недостатки).
 1. Введение
1. Введение


 От переводчика: Это первая статья из
От переводчика: Это первая статья из