
Этот материал представляет собой глубокое исследование всего, что связано с Redis. В частности — речь пойдёт о различных способах организации хранилищ Redis, о постоянном хранении данных, о форках процессов.

User
Этот материал представляет собой глубокое исследование всего, что связано с Redis. В частности — речь пойдёт о различных способах организации хранилищ Redis, о постоянном хранении данных, о форках процессов.


Кто про что, а я про баги.
В прошлом году я рассказывала вам про Багодельню — мероприятие, проводимое у нас в компании для чистки бэклога багов. Событие хорошее и полезное, но решающее проблему с багами разово. Мы провели уже шесть Багоделен, но количество участников постепенно снижалось и стало очевидно, что потребность в этом мероприятии начала отпадать. Основной причиной стало появление у нас Zero Bug Policy. О ней есть не так много источников на русском, где можно почитать и найти удобное решение для себя. В этой статье я расскажу про наш подход к теме и с удовольствием почитаю про ваш опыт в комментариях.


Компания у нас на full-remote, поэтому заседание кружка параноиков мы проводим как-то так. Иногда под банджо в углу.
В жизни любого проекта наступает катастрофа. Мы не можем заранее знать, что именно это будет - короткое замыкание в серверной, инженер, дропнувший центральную БД или нашествие бобров. Тем не менее, оно обязательно случится, причем по предельно идиотской причине.
Насчет бобров, я, кстати, не шутил. В Канаде они перегрызли кабель и оставили целый район Tumbler Ridge без оптоволоконной связи. Причем, животные, как мне кажется, делают все для того, чтобы внезапно лишить вас доступа к вашим ресурсам:
Макаки жуют провода. Цикады принимают кабели за ветки, и расковыривают их, чтобы отложить внутрь яйца. Акулы жуют трансатлантические кабели Google. А в топе источника проблем для крупной телекоммуникационной компании Level 3 Communications вообще были белки.
Короче, рано или поздно, кто-то обязательно что-то сломает, уронит, или зальет неверный конфиг в самый неподходящий момент. И вот тут появляется то, что отличает компании, которые успешно переживают фатальную аварию от тех, кто бегает кругами и пытается восстановить рассыпавшуюся инфраструктуру - DRP. Вот о том, как правильно написать Disaster Recovery Plan я сегодня вам и расскажу.
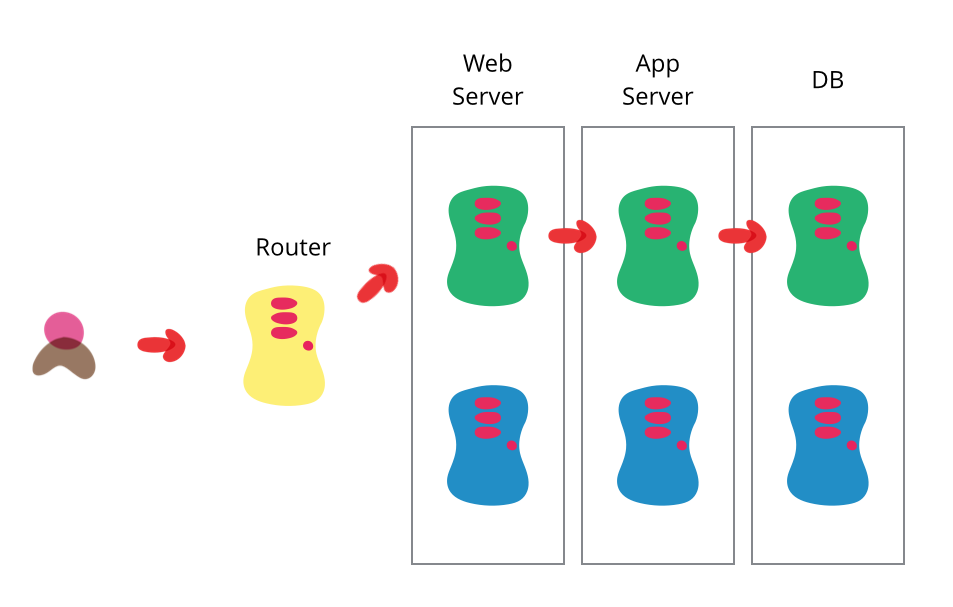
Я и мои коллеги всегда склоняем своих клиентов полностью автоматизировать процесс деплоя. Автоматизация помогает сократить количество конфликтов и задержек, которые возникают в процессе между "завершением" работы над программой и введением в эксплуатацию. Дэйв Фарли (Dave Farley) и Джез Хамбл (Jez Humble) заканчивают книгу "Непрерывная доставка" (Continuous Delivery) на эту тему. Она основывается на множестве идей, которые в целом связаны с непрерывной интеграцией и подталкивают к возможности быстро пустить софт в работу. Глава о сине-зеленом деплое привлекла мое внимание, потому что это один из малоиспользуемых методов, и я решил кратко его осветить.

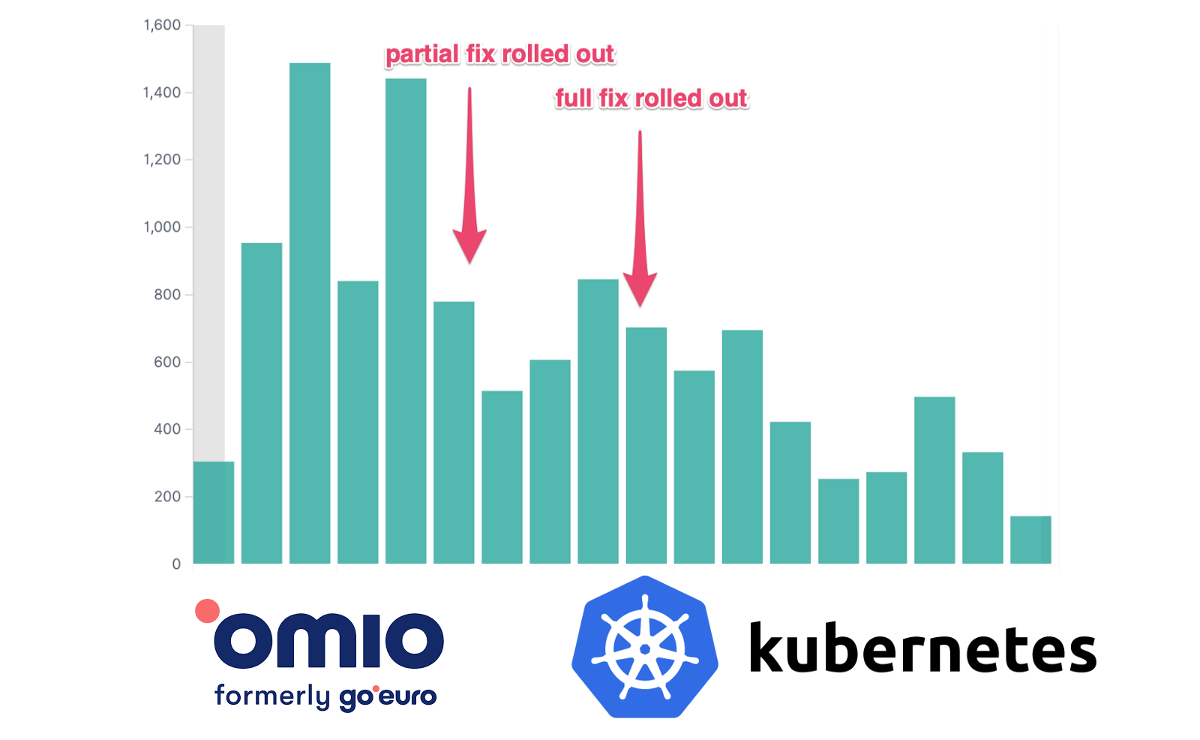
Если вы когда-либо взаимодействовали с кластером Kubernetes, скорее всего, он был основан на etcd. etcd лежит в основе работы Kubernetes, но несмотря на это, напрямую взаимодействовать с ним приходится не каждый день.
Этот перевод статьи от learnk8s познакомит вас с принципами работы etcd, чтобы вы могли глубже понять внутреннюю работу Kubernetes и получить дополнительные инструменты для устранения неполадок в вашем кластере. Мы установим и сломаем кластер etcd с тремя нодами и узнаем, почему Kubernetes использует etcd в качестве базы данных.

ReplicaSet — но это ручной процесс. Команда Kubernetes aaS от Mail.ru реализовала в своем сервисе автоматическое машстабирование на уровне кластеров. Ну а если вы хотите оптимизироваться на уровне подов — то следуйте рекомендациям этого перевода.ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler. По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
