Часть 1 — линейная регрессия
В первой части я забыл упомянуть, что если случайно сгенерированные данные не по душе, то можно взять любой подходящий пример
отсюда. Можно почувствовать себя
ботаником,
виноделом,
продавцом. И все это не вставая со стула. В наличии множество наборов данных и одно
условие — при публикации указывать откуда взял данные, чтобы другие смогли воспроизвести результаты.
Градиентный спуск
В прошлой части был показан пример вычисления параметров линейной регрессии с помощью метода наименьших квадратов. Параметры были найдены аналитически —
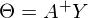
, где
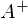
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).

 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест