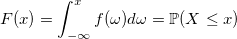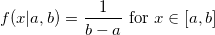Недавно у меня с коллегой вышла дискуссия — влияет ли объём данных на трудоёмкость разработки.
В сухом остатке осталось:
Для разработчика, прямо скажем, выводы получились не очень весёлые и однозначные.
Но дискуссия возникла не на пустом месте, а в рамках обсуждения задачи с простым вычислительным алгоритмом, но большим количеством данных.
Цель публикации — поделиться опытом как, за приемлемое время, обработать два связанных списка по миллиарду записей в каждом.
В сухом остатке осталось:
- Объём данных не должен оказывать значительного влияния на трудоёмкость разработки. Основная трудоёмкость разработки, как правило, связана со сложностью алгоритма обработки данных, а не с их количеством. Заранее зная фактический объём данных, достаточно разработать код, который работает на небольших данных, а затем его можно применить к требуемому объёму.
- Все основные вычислительные алгоритмы давным-давно известны (как минимум уже несколько десятков лет). Главное, как можно раньше (до начала разработки), определить правильный подход к задаче. Но это вопрос не трудоёмкости, а профпригодности — то есть, матчасть надо изучать заранее, а разрабатывать быстро.
- Ни один Заказчик не поймёт почему трудоёмкость разработки кода в несколько сотен строк, заняла много времени. Заказчику проще сменить команду, чем вложиться своим временем и деньгами в чей-то процесс обучения или в какой-то непонятный ему эксперимент.
- Небольшие накладные расходы, связанные с объёмом данных, конечно могут быть. Но эти издержки, обычно, не превышают погрешности первоначальной (правильной) оценки трудоёмкости и учитывать их отдельно не имеет смысла.
Для разработчика, прямо скажем, выводы получились не очень весёлые и однозначные.
Но дискуссия возникла не на пустом месте, а в рамках обсуждения задачи с простым вычислительным алгоритмом, но большим количеством данных.
Цель публикации — поделиться опытом как, за приемлемое время, обработать два связанных списка по миллиарду записей в каждом.



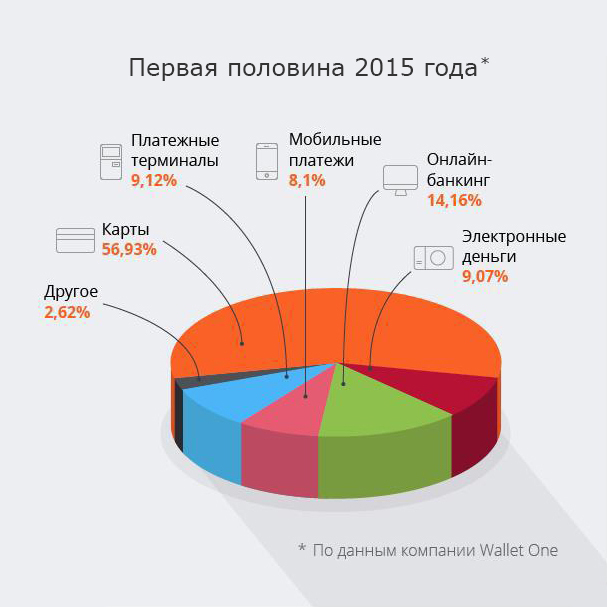
 В этом посте я бы хотел поделиться результатами исследования способов оплаты, которые предпочитают пользователи при совершении покупок онлайн. Данное исследование охватило более сотни способов оплаты и тысячи сайтов, подключенных к агрегатору платежей «
В этом посте я бы хотел поделиться результатами исследования способов оплаты, которые предпочитают пользователи при совершении покупок онлайн. Данное исследование охватило более сотни способов оплаты и тысячи сайтов, подключенных к агрегатору платежей «